第二章 链接你的数据
无论是个人还是企业,需要分析的数据正在变得越来越多,数据的来源也变得越来越多样,这些待分析的数据往往分散在多个数据库、文本文件、电子表格,外部数据源中。DataFocus为用户提供了整合各种数据源的“数据管理”功能模块,用户可以通过它连接各种各样主流的数据库,也可以上传或者同步本地excel文件。DataFocus标准版以上产品的数据管理模块包含了大数据仓库和内存计算引擎。用户接入的数据都将以列式存储的格式保存在数仓中,这保证了分析计算的高效性。
2.1链接你的数据
2.1.1 连接本地文件
打开DataFocus系统,点击左侧数据管理,然后点击右侧操作按钮,点击导入数据。可导入本地CSV、TXT、XLS、XLSX以及JSON等本地数据文件。选中后点击上传,并确认行列属性是否正确。若行列属性不正确(如数值保留了字符串格式未转化为数值格式),则无法进行可视化分析。适用于一些本地已有文件(如一些店铺数据或是自录数据表)的分析,或是一些未购买数据库的企业。
导入本地数据,大小限制为50MB。本地Excel文件经常存在数据不规范的问题,DataFocus的数据导入模块提供了简单的数据清理功能,具体操作为在导入数据时点击高级按钮,会展开一系列选项,用户可以设置跳过行、读取行数、跳过注释行、拆分列等操作,进行简单的数据清理。
2.1.2 批量导入Excel数据
对于大量的,经常更新的本地数据源,DataFocus还提供了excel文件批量同步工具。比如有些小企业或工厂经常采用excel进行数据管理,他们将数据存放在某些固定的文件夹中,并定时更新。这种场景,就可以通过设定excel批量同步工具定时将excel数据追加上传到DataFocus的数据仓库中进行分析。
DataFocus Sync tool提供了丰富的数据同步追加功能,以及数据清洗和预处功能,足以允许部分习惯于使用excel进行数据管理的企业平滑的将其数据迁移到DataFocus中来。使用前需要用户在服务参数配置中填入对应的服务器地址和对应的Key。
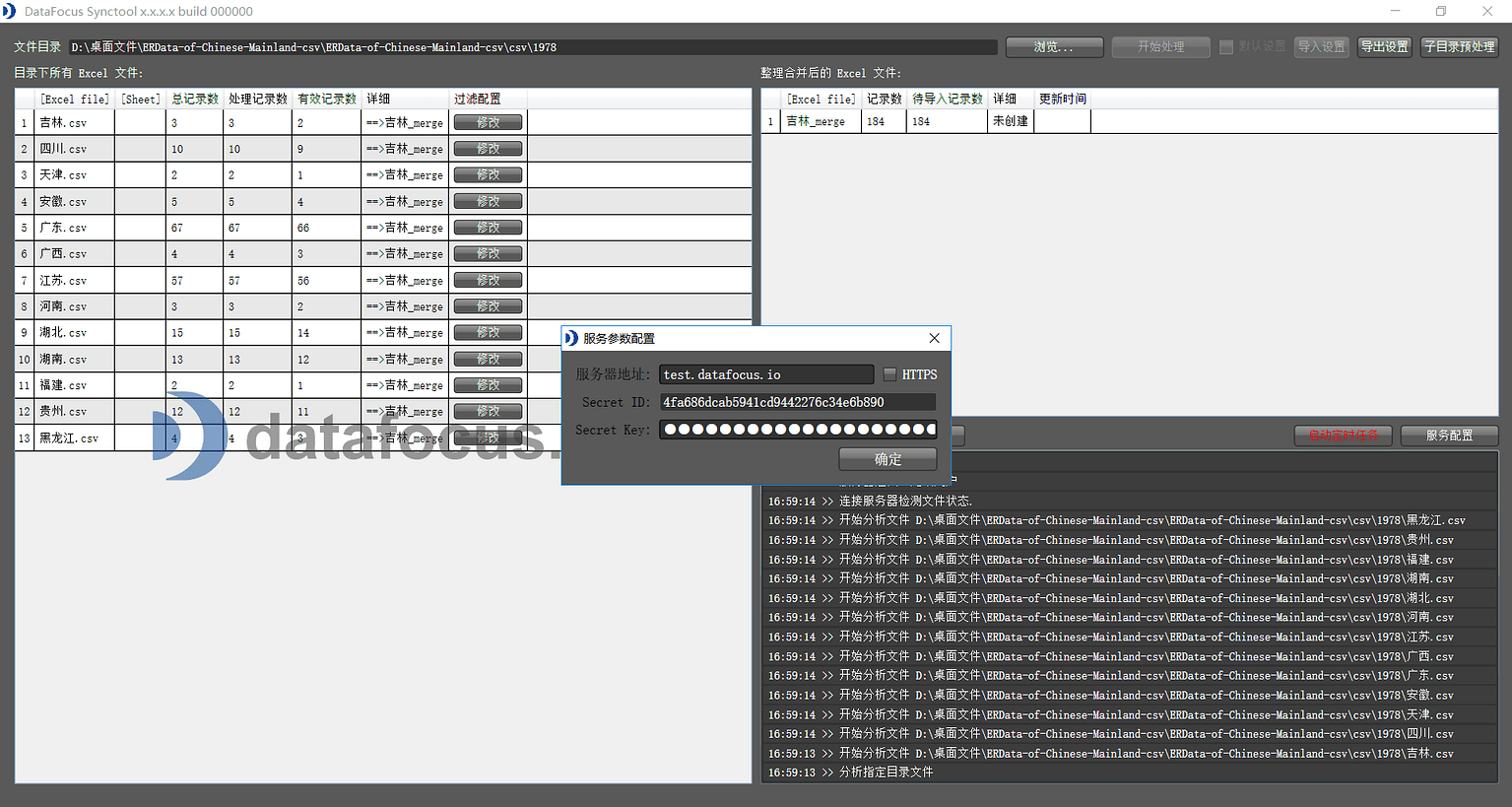
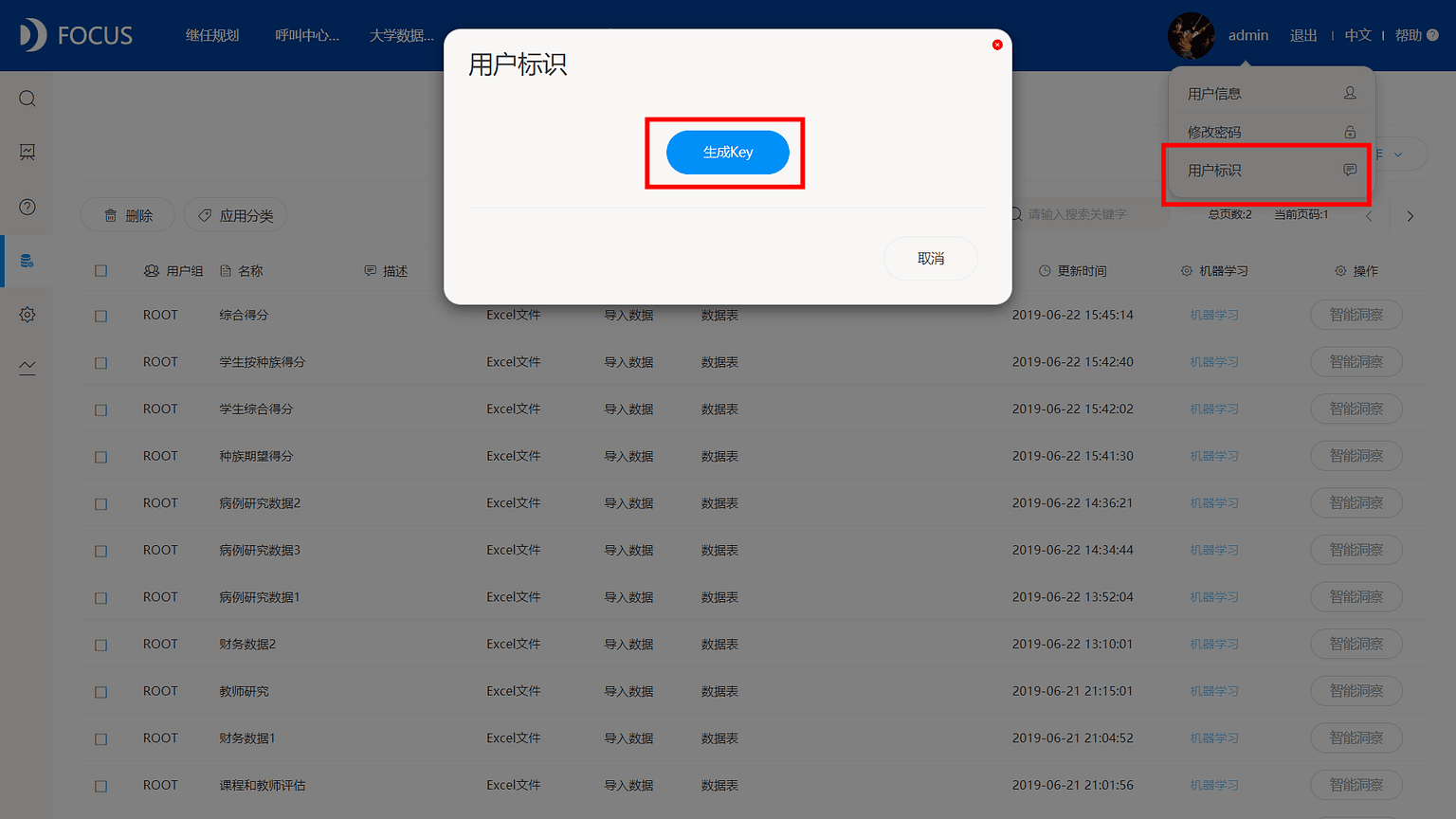
服务参数SecretID和SecretKey通过DataFocus系统的用户页面点击用户标识,生成对应的Key。用户完成配置连接成功后,同步工具将自动扫描所选文件夹,整理和汇总对应的数据表,如果服务器搭建在云端,应采用https加密连接方式进行。同步工具还提供了数据清理功能,用户可以自主配置规则对数据表进行过滤和筛选,这对不规范的excel表非常有用,还可以设定定时导入功能以便用户定时同步追加数据到DataFocus的服务端。DataFocuaMini及以上版本均支持同步工具的导入。
2.1.3 连接数据库
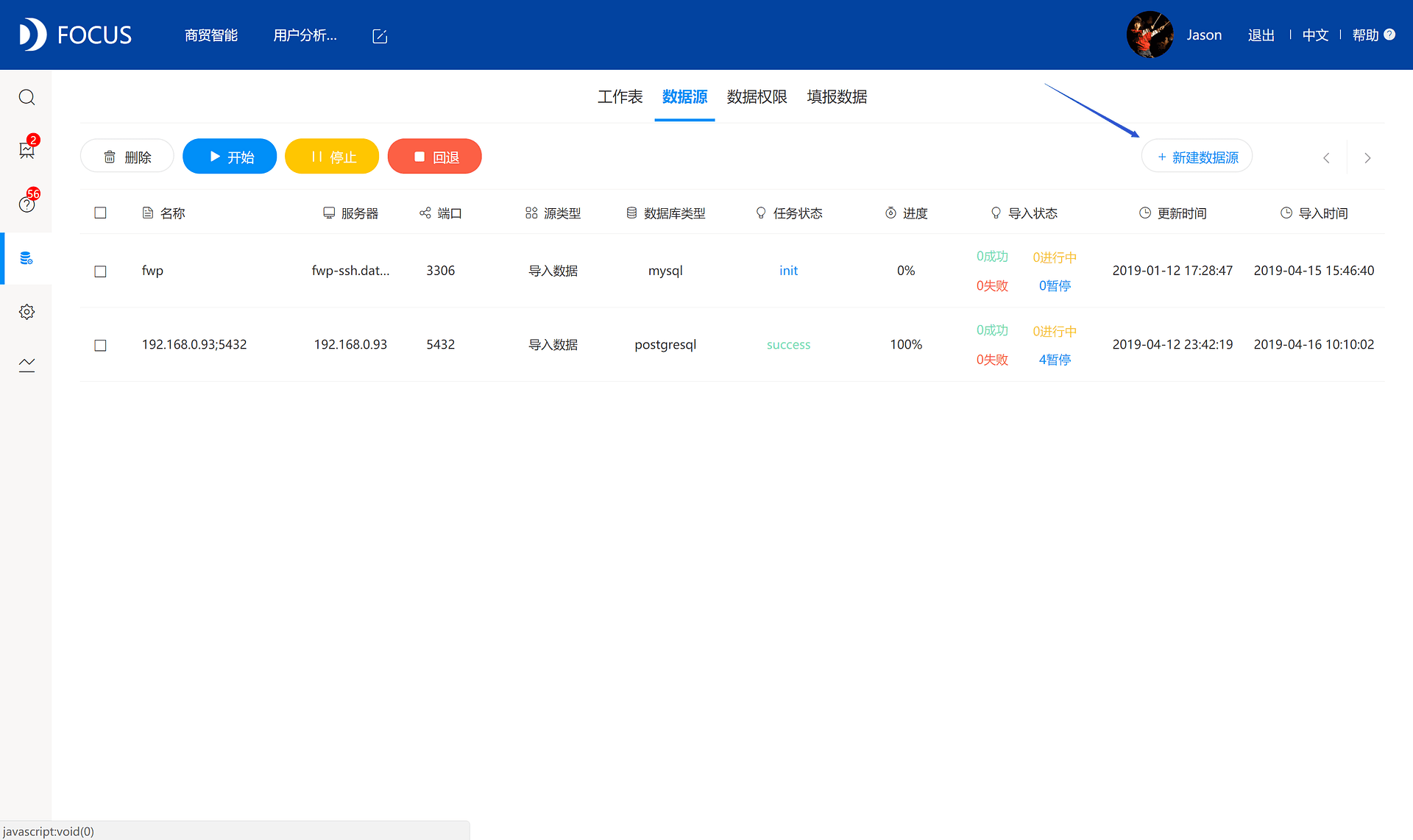
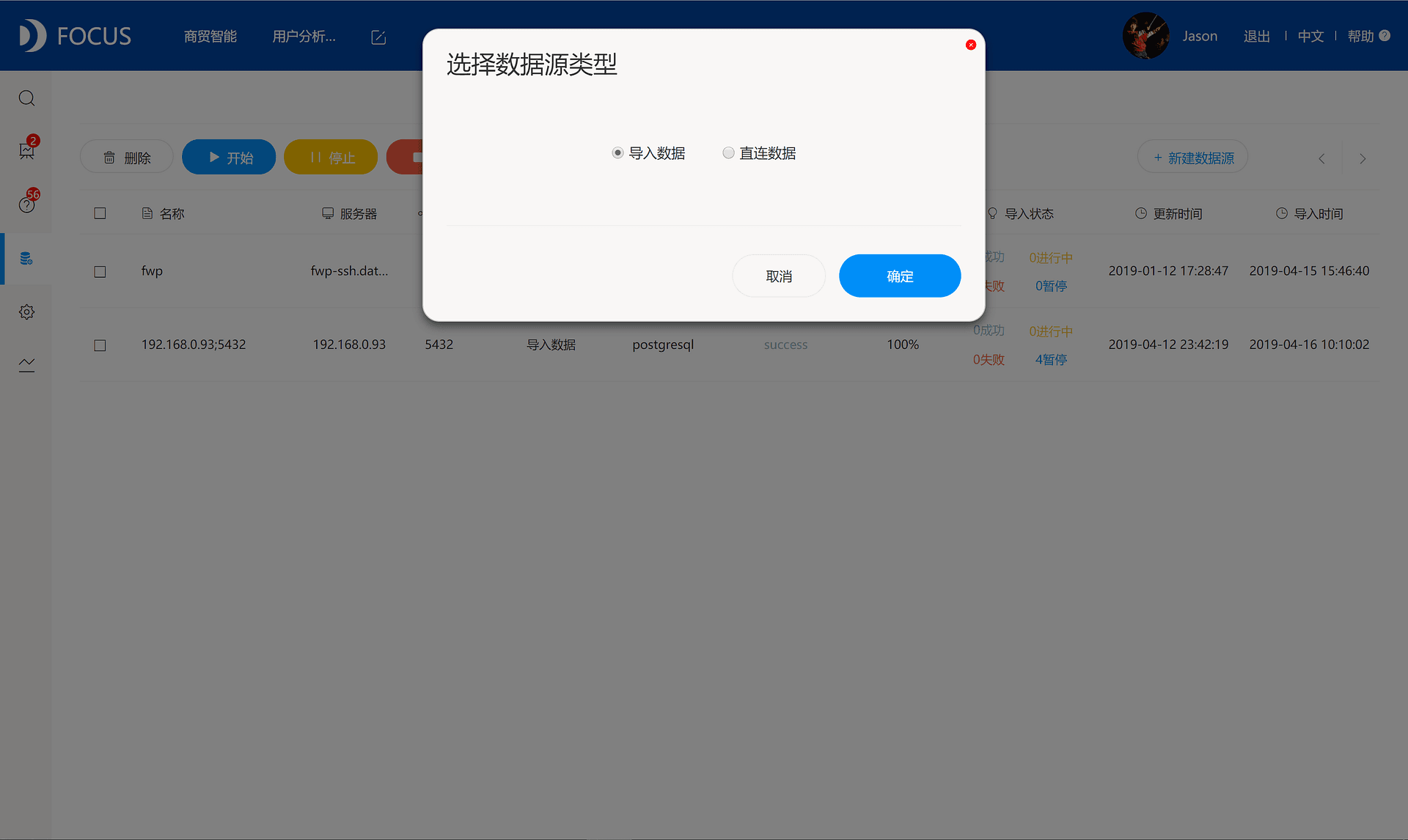
点击左侧数据管理模块,点击上方数据源按钮,点击右侧新建数据源,可点击直连数据和导入数据。需要注意的是,导入数据为数据导入到DataFocus自带大数据仓库,直连数据为直接抽取服务器数据进行分析。若是操作大量分析,建议使用导入数据,DataFocus数据仓库性能可保障分析顺畅,否则直连数据分析则依靠对方设备的性能。数据导入后,可点击上方“开始”则可进行导入,列表可查看导入状态。
导入数据支持定时更新,更新频率一般为每天、每周、每月。直连数据可支持实时更新,数据库中数据有变化,DataFocus中直连的这些表,以及依赖这些表制作的报表等也都能实时更新。
2.1.4 直连数据和导入数据
使用DataFocus进行数据分析需要与数据库交互,但这与你使用ERP、CRM系统与数据库交互的形式是完全不一样的。前者属于联机分析处理OLAP(On-Line Analytical Processing)业务,一般需要进行比较复杂的数据库计算,分析数据量大、维度多;而后者则属于联机事务处理OLTP(on-line transaction processing)范畴,主要是基本的、日常的事务处理,例如销售流水记录、银行交易记录,这类分析要求实时性高,往往只需要简单的读写或者查询数据库即可。这是两种典型的数据库应用场景。DataFocus连接数据库时,同时提供了直连数据库功能和导入数据功能。这两种不同的功能分别对应着不同的应用场景。
直连数据库的优点。有少数场景也需要实时查询相应的数据,比如用于汇报或展示的数据可视化大屏、用于生产线的数据看板,均需要显示实时的产量、交易数等。DataFocus提供了直连用户数据库的功能,用户的搜索分析指令将被转交给用户业务系统的数据库进行计算,因此一般此类通过直连数据库的数据分析复杂性较低,否则会对用户业务系统数据库造成压力。
一般情况下,如果业务系统数据库稳定性要求极高,或者数据库压力过大,不推荐使用数据库直连方式,这会对用户的业务造成不可预知的影响。
数据导入的灵活性。将用户数据中的数据定时导入到DataFocus的大数据仓库中,经过模型构建再进行分析,适用于分析、探索大数据(比如上亿行数据),或者维度繁多的数据, DataFocus会将这些数据压缩成列式存储格式,并调用内存计算引擎进行高速分析,可以获得极佳的探索分析体验。
用户将数据库中的数据导入DataFocus数据仓库中进行分析,可以减轻业务系统数据库的分析压力,因为数据分析有时候需要对数年的数据,或者多张关联的数据表进行筛选、聚合、计算,其计算强度往往比业务系统中的业务流程所触发的数据库计算强度要高得多,把这些工作放到DataFocus的计算引擎中去执行,高效且可靠,不会对业务系统造成额外的压力。及时偶尔出错也不会干扰业务系统的正常运行。
通常,有经验的用户会设定DataFocus的定时导入功能从数据库中抽取数据,根据业务系统数据库能够承受的压力以及决策的时效性需求,制定合理的更新频率。第一次导入数据时可以全量导入,之后就可以定时增量更新。有时候,如果业务系统的安全性要求较高,可以设置DataFocus从备库中导入数据。
2.2数据表关联配置
2.2.1 数据表的关联关系
进行数据库记录时,为了提高效率,需要将数据按业务情况存放到多个数据表中,这些数据表之间彼此通过外键关联的方式链接起来,方便进行跨表查询和分析。DataFocus中支持的典型的数据库表关联关系一般有左连接(left join)、右连接(right join)和内链接(inner join)三种常用链接方式。
500px|缩略图|居中|《玩转DataFocus数据分析》 图2-8 数据库关联方式 左关联(left join)
{kind=link}
500px|缩略图|居中|《玩转DataFocus数据分析》 图2-8 数据库关联方式 右关联(right join)
{kind=link}
500px|缩略图|居中|《玩转DataFocus数据分析》 图2-8 数据库关联方式 内关联(inner join)
{kind=link}
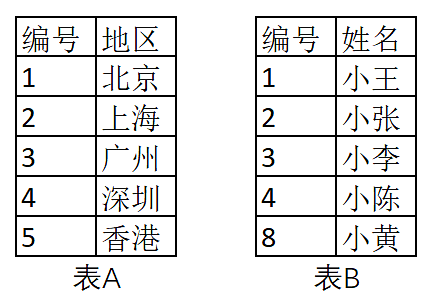
从上图很容易看出,左连接(left join)返回包括左表中的所有记录和右表中相关联字段的记录;右连接(right join)返回包括右表中的所有记录和左表中关联字段相等的记录;内链接(inner join)则只返回两个表中关联字段相等的行。举例来说,假设A表记录了地区及编号,B表记录了姓名及编号:
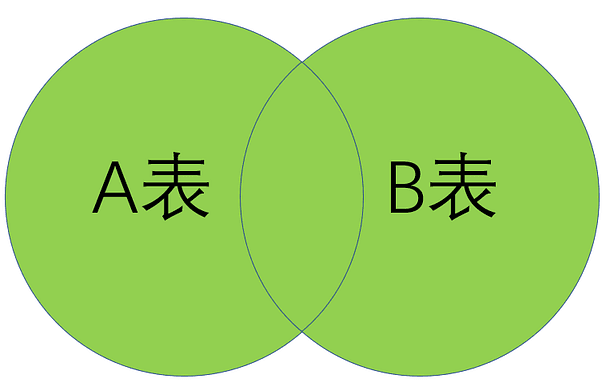
表2-1 数据关联表 四种关联结果分别如下,可以看出第四种关联结果产生了大量的冗余信息,称之为笛卡儿积,这有时候会造成无意义的数据膨胀,创建关联关系时应该尽量避免。
2.2.2 配置多表关联
在进行数据分析的时候,经常会出现需要多张表格联立使用的情况,因此就需要在系统中添加表与表之间的关联关系。 在数据管理页面,点击一张表格,在弹出的表格信息中选择“关联关系”,如图2-4-1所示。
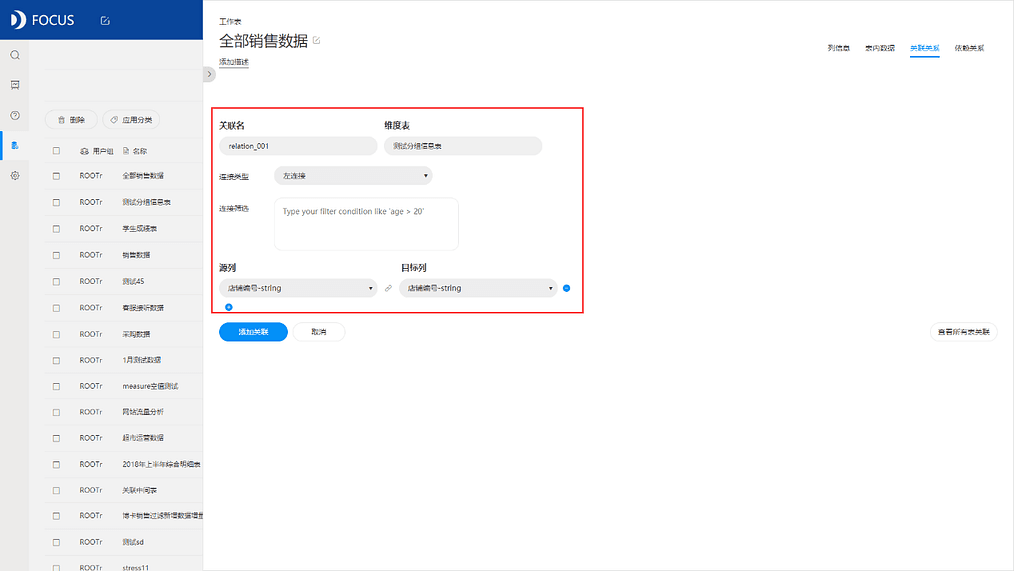
点击“添加关联”,在弹出的具体的操作界面,如图2-4-2所示,填写关联名、维度表、连接类型、连接筛选(选填)、源列、目标列的内容。 维度表就是指要与该表建立关联关系的数据表,点击维度表的输入框会出现系统里现有的前7张表格,可以直接选择或者输入表名选择自己想要关联的表;连接类型分为三种:内连接、左连接及右连接;源列和目标列就是关联两张表格的数据列。
点击“添加关联”,就会在“关联关系”的页面出现两张表格的表名以及箭头符号,代表了关联关系的方向和关联的表格信息,如图2-4-3所示。
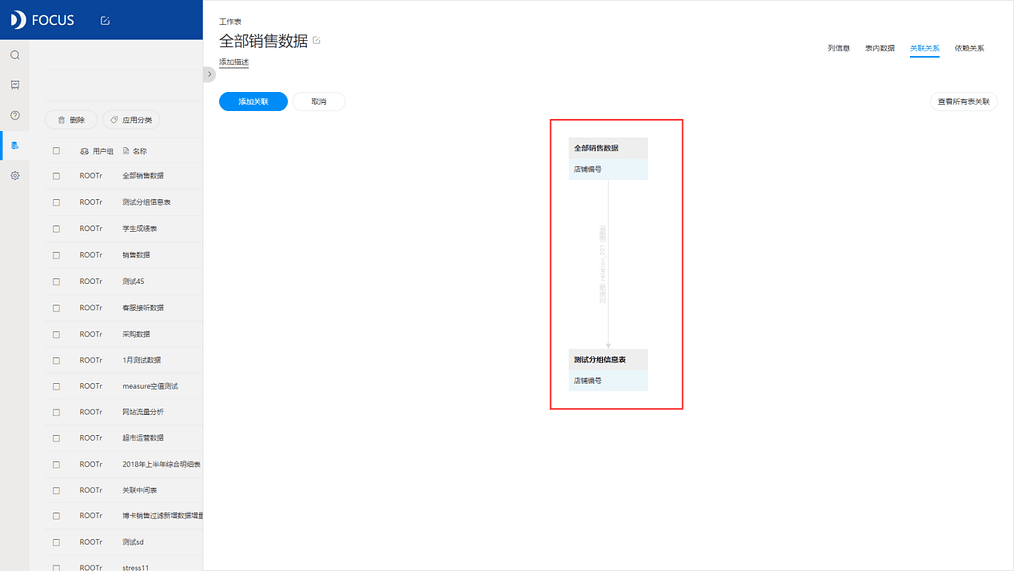
关联好的两张表格也会在数据管理页面通过两个红色小箭头标注,如图2-4-4所示。
2.2.3 配置条件关联
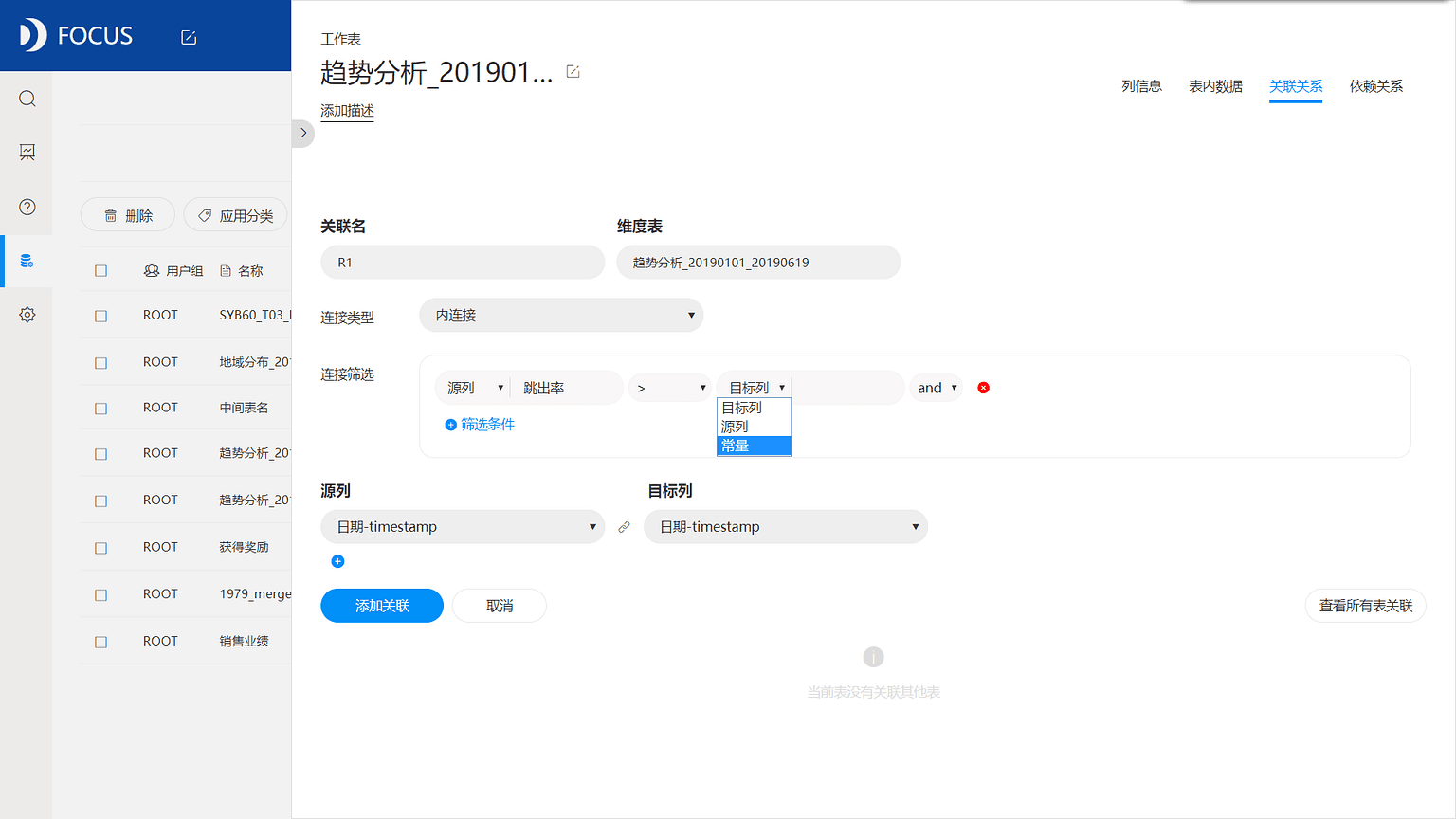
为了更灵活的分析,有时候关联关系的配置需要设定条件,DataFocus中可以通过设定链接筛选条件实现按条件的数据关联,这在数据量非常大的情况下进行特定的分析非常有益,可以有效的降低数据量,提升分析效率。比如,如果待关联的两张表,通过时间列关联,但是用户只想分析某个特定时间段的数据,就可以设定时间在某个范围的关联条件。
2.2.4扇形陷阱和断层陷阱
根据上面的章节介绍,我们知道两个表要建立连接一定要存在主外键关系, 例如上节所述的表A和表B就是通过编号这个外键建立关联关系的。但有些时候,一些关系型数据库设计不规范,两个表需要关联,但是没有直接主外键,借助第三个表进行关联,按照其设置好关联关系后,构建模型容易造成扇形陷阱(Fan Traps)。
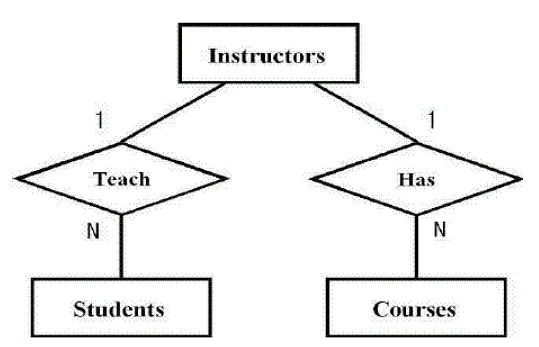
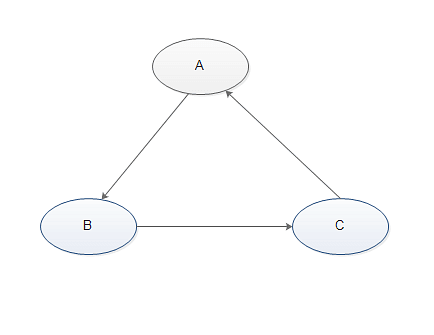
扇形陷阱通常是产生于一些事实表(Fact Table)拥有多个一对多的关联,好像扇子散开一样,而关联在一起的实体间的关联性让人产生混淆。比如:Instructors、Students、Courses这三个实体,其中一个Instructor可以有多个Student,一个Student有多个Course,一个Instructor也可以有多个Course,这时如果把关联设计为下图的形式:
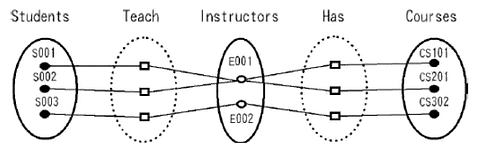
这样就出现了扇形陷阱:其中student与course的关系非常混乱了,成了多对多。
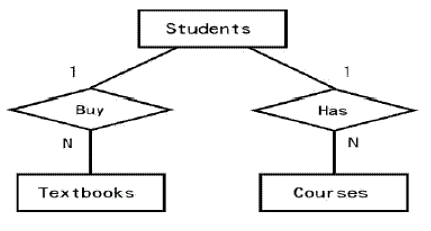
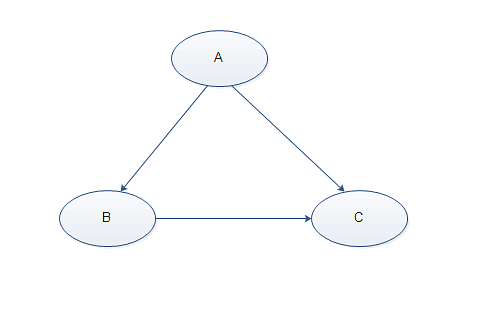
断层陷阱(Chasm Traps),还有一种情况是事实表之间该存在的关系却没有体现出来,两个事实表并没有办法找到一条路径来连接。比如:Students、Textbooks、Courses三个实体,其中一个Student可以有多个Textbook,一个Student也可以有多个Course,如果把关联设计为下图的形式:
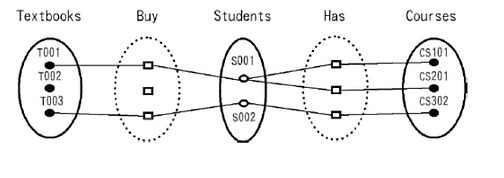
这就产生了断层陷阱:由于Student可以没有Textbook,Textbook就不知道是属于哪个Course的了。
2.2.5 数据表关联约束
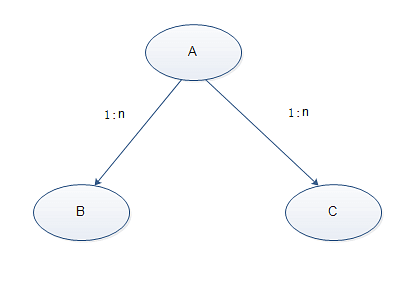
各种数据设计缺陷,如上节所述的扇形陷阱(Fan Traps)和断层陷阱(Chasm Traps)最为常见,此外还有一些如闭环陷阱之类的问题,都会导致数据库表关联后SQL语句无法执行的问题。为了保障DataFocus能够正常运行,用户必须尽量避免以上问题的发生,在配置关联关系时,DataFocus系统对部分以上问题进行了预处理,这些处理是不彻底的(也无法做到完美),其目的是最大限度的适应用户的数据库现状,即便如此,用户依然应该尽量优化数据库设计,规避此类缺陷发生。 关联环路:用户在配置数据表关联关系的时候应避免配置成关联环路(如图2-19所示),A->B->C->A关联环路会导致事实表和纬度表关联关系混乱,DataFocus系统无法根据这样的关联关系构造出能够执行的SQL语句,所以DataFocus系统不支持配置关联环路。
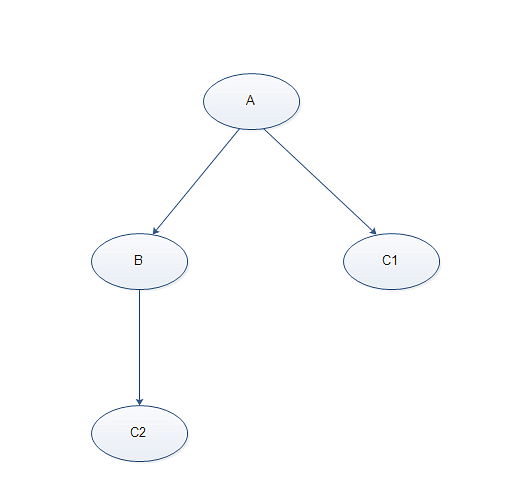
关联节点闭合:用户在配置数据表关联关系的时候有可能把某一个维度表配置成闭合节点(如图2-20所示)A->C而且A->B->C则维度表C为一个闭合节点,正常来说有闭合节点的情况下构建关联查询SQL会造成C表重复关联的错误,DataFocus对此种状况做了一定的适配。把这种关联关系拆分成了A->C1和A->B-C2(如图2-21所示)其中C1和C2就是C表的但是使用的不同的别名,这样可以把构建出来可以执行的关联SQL。但是如果闭合节点C以下又有很多维度表关联的话会导致构造关联SQL的时候别名过多,所以暂时不支持闭合节点C以下关联其他维度表。
扇形陷阱/断层陷阱:用户在配置关联关系的时候应尽量避免配置成扇形陷阱和断层陷阱,如果用户配置关联关系造成了扇形陷阱,DataFocus为了防止扇形陷阱导致的数据极度膨胀会做一定的检测,如果检测到用户可能配置造成了扇形陷阱,会对关联关系做一定的适配处理。如图2-21 A->B和A->C表如果存在扇形陷阱,则B和C的关系将会变的混乱,不适合在一起查询,当出现这种情况,DataFocus中会做一定适配只能让A表和B表同时查询,A表和C表同时查询,B表和C表不能同时查询。
2.3 数据库模型
2.3.1数据类型介绍
存储在关系数据库(RMDBS)中的一般以结构化数据居多,这部分数据也最容易拿来进行分析和可视化。结构化数据一般都是以二维表的形式存储,如下表所示。在DataFocus中,我们将“姓名”、“性别”、“年龄”称作列名,对应列名下的值,如“张三”“17”等,称之为列中值,列名是进行搜索分析的重要元素,列中值则经常用来进行过滤和筛选。
| 姓名 | 性别 | 年龄 |
|---|---|---|
| 张三 | 男 | 17 |
| 李四 | 女 | 18 |
表2-3 二位数据表
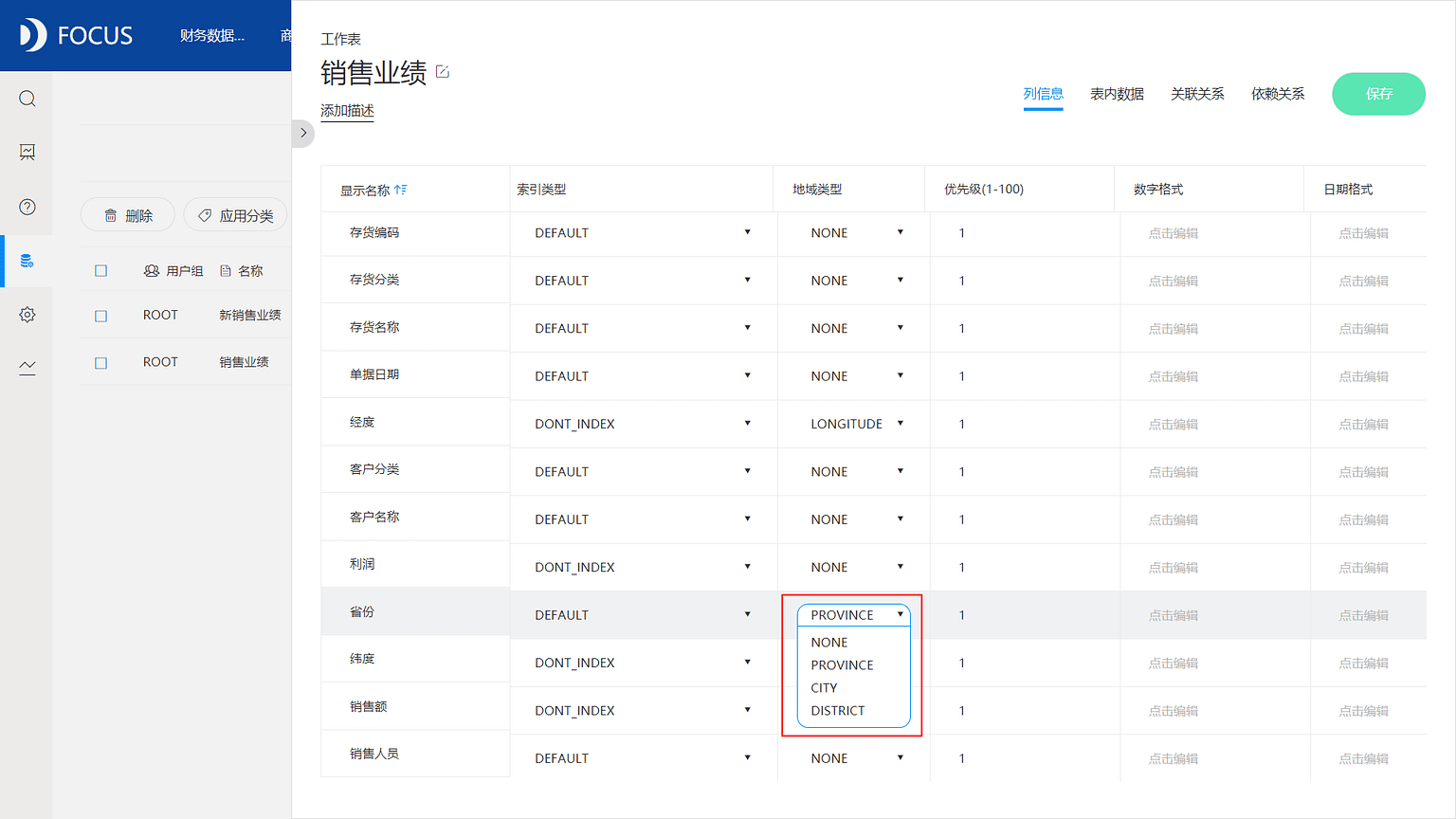
列名大致分为属性列(attribute)和数值列(measure),其中属性列一般分为字符串(string)、日期(timestamp)、地理位置(Geomap)几大类,数值列则一般为int、double。
数据导入DataFocus系统中时,如果是从数据库中导入数据,系统会自动继承数据表的各项属性,一般不需要用户干预,如果是从本地导入excel数据,系统会判断和识别数据类型,但地理位置类型数据,需要用户选择设定对应的省、市、区,聚合方式选择成none。如果是经纬度数据,则需要配置成LATITUE或者LONGITUDE。
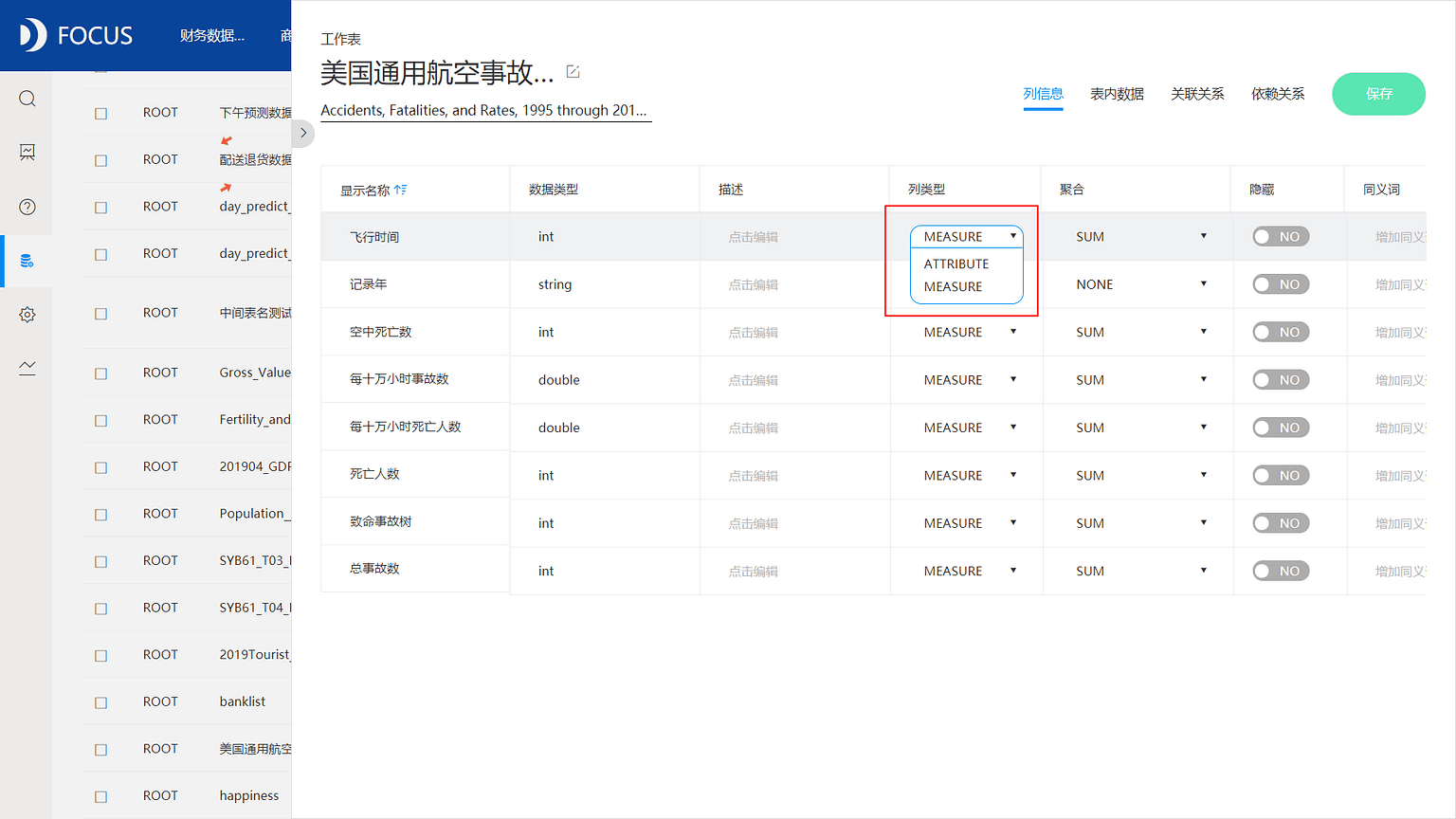
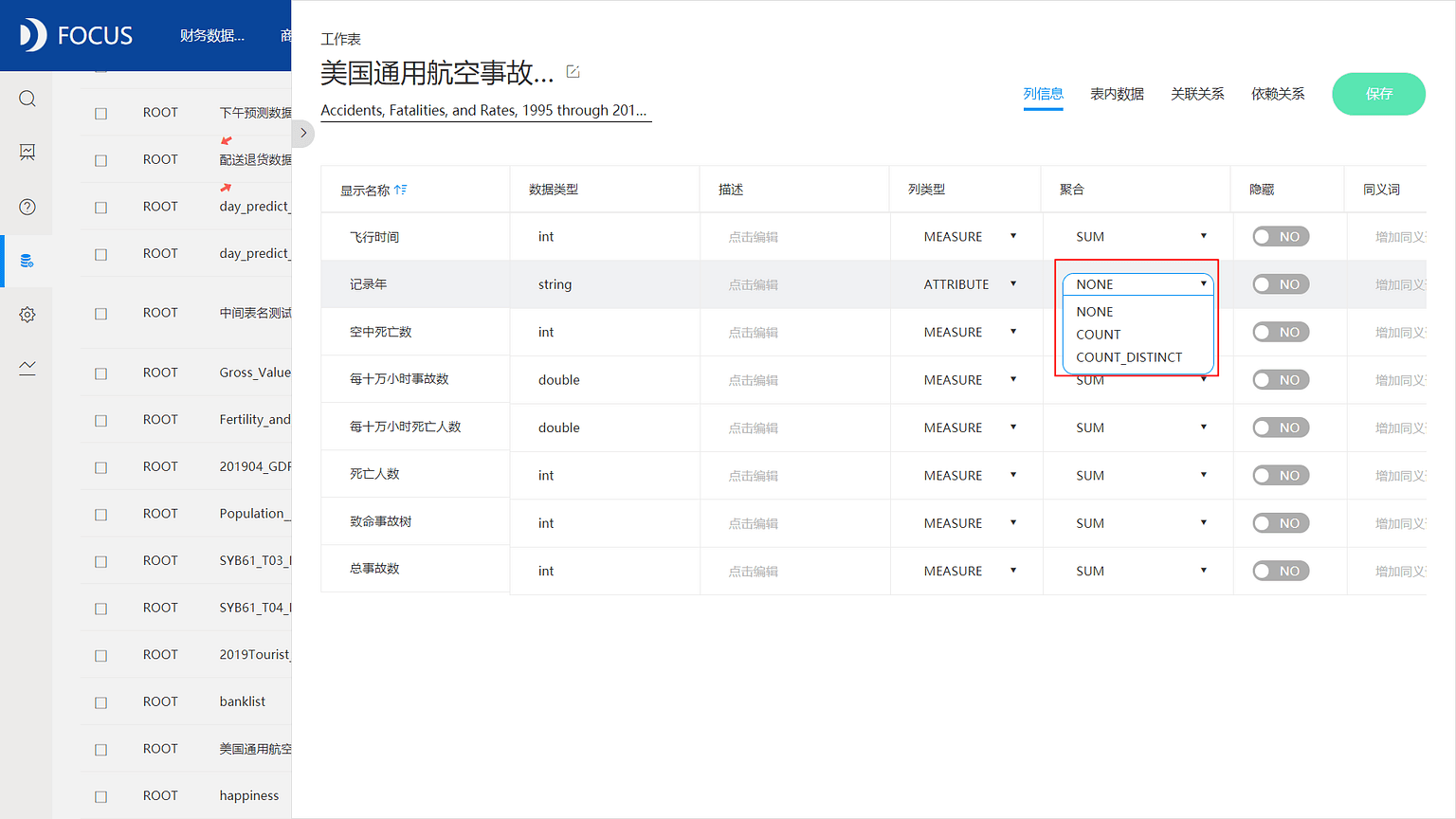
不同的列属性对应着不同的数据库聚合操作。属性列默认在数据分析时不会自动聚合,如有需要则可以进行计数(统计数量)或去重计数;数值列则可以进行求最大值、最小值、平均值、求和、标准差、方差、计数等各种操作,数据分析时会默认进行聚合分析,一般不选择的情况下,会默认进行求和操作,如果不希望分析时自动聚合数据,则可以选择none,DataFocus系统默认不进行任何聚合操作。
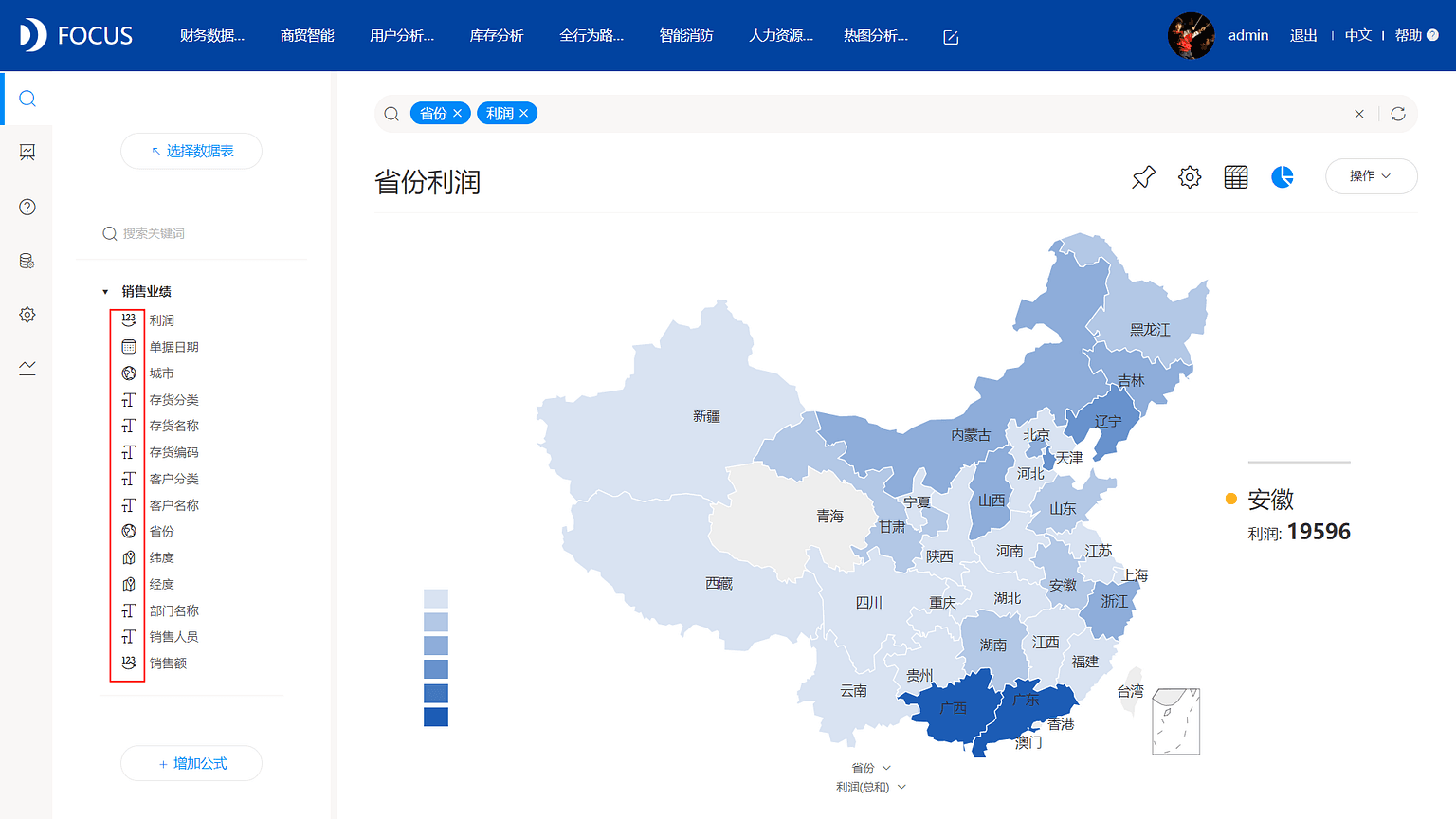
列的不同属性,在DataFocus中加载数据后,会以不同的图标显示出来,也意味着不同的关键词操作,比如,对于字符串类型的属性列,就可以用“姓名开头是张的”进行查询,数值列则可以进行排序和聚合,比如“成本的平均值排名前三的工序”。而特殊类型如日期列则可以直接提问“每月销售额”,地理位置图则直接以地图形式呈现可视化结果。
2.3.2星形模型和雪花模型
企业的数据库一般由多个维度表(Dimision table)和事实表(Fact table)组成,这些数据表之间的关联方式多种多样。在多维分析的商业智能解决方案中经常会用到星型数据模型(Star Schema)和雪花模型(Snowflake Schema),DataFocus同时支持这两种数据模型,鉴于着两种数据模型在不同市场场景下各有优劣,建议用户在设计数据逻辑模型时,应该认真考虑使用何种模型。 星型数据模型,当所有维度表都直接连接到“ 事实表”上时,整个表结构就像星星一样,故将该模型称为星型模型。星型模型是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
雪花模型,当有一个或多个维度表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维度表进一步层次化,原有的各维度表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
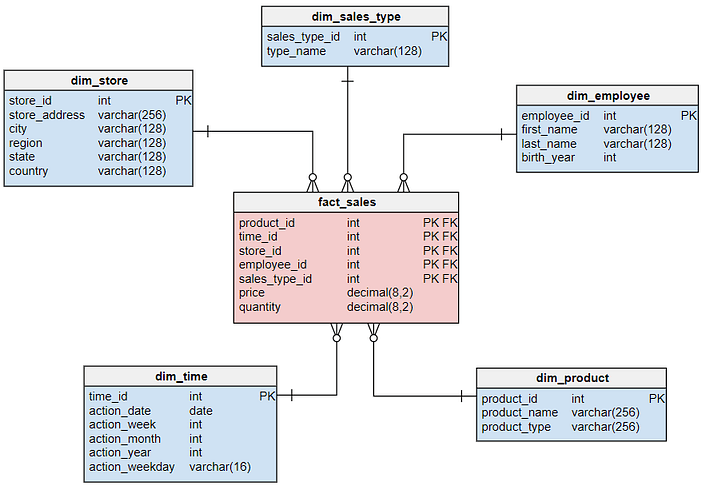
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
总体来讲,雪花模型使得进行复杂维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”星形模型做简单的指标分析更适合,比如“销售员张三的销售额?”
2.3.3数据模型构建
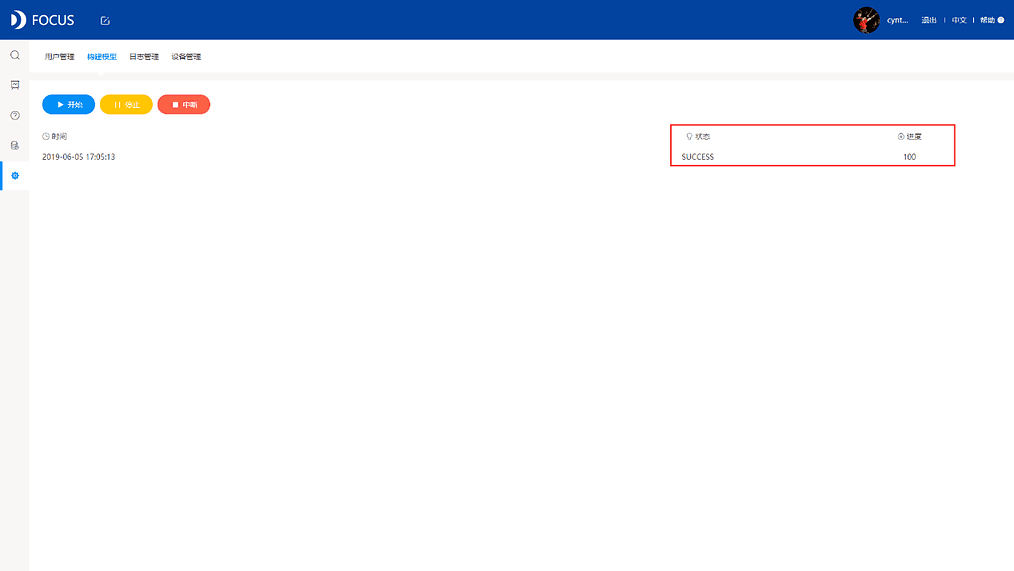
将数据导入DataFocus中以后,必须先按照设计的数据模型进行表间关联配置。在DataFocusMini以及DataFocus Public版本中,由于没有大数据仓库,不需要进行模型就见就可以立即进行分析。但是这种方式不能处理数据量巨大的情况;DataFocusStandard及以上版本则提供了模型构建功能,如下图所示,点击进行模型构建,100%完成后即可进行大数据分析了,后续数据库增量更新,不需要重新构建模型,但如果更改了数据模型,比如改变某些表之间的关联关系,则必须重新构建模型才能进行联表分析。
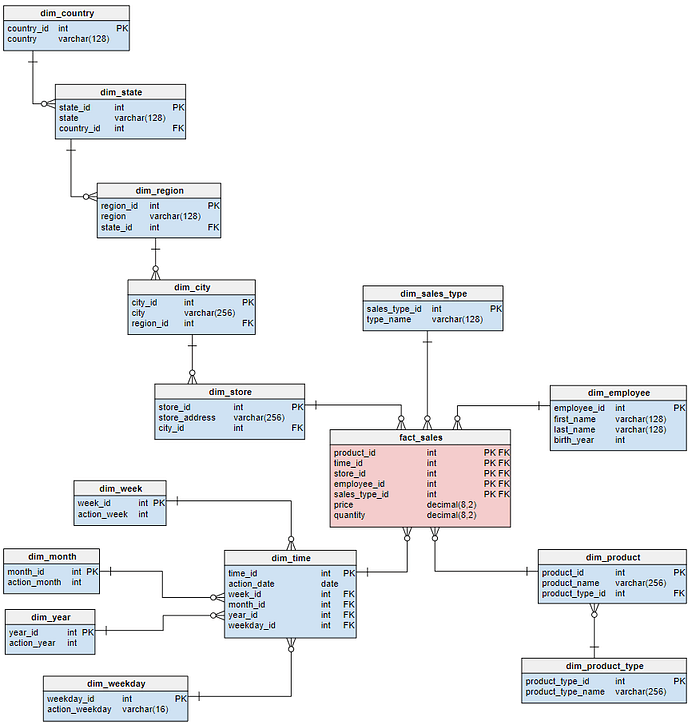
当模型构建的状态变成SUCCESS,进度为100%时,代表模型构建成功,如图2-4-6所示。
关联好的多张表格可以在搜索页面进行多表联立搜索,如图2-4-7所示。 用户在创建表关联关系的时候,表关联不能出现回路和闭环。