搜索模块
选择数据表
在进行搜索数据分析前,用户需要先选择自己要使用的数据表。点击“选择数据表”按钮后会弹出一个选择数据表的界面,此处可选择数据表或者数据集,选择完成后就可以开始分析了。
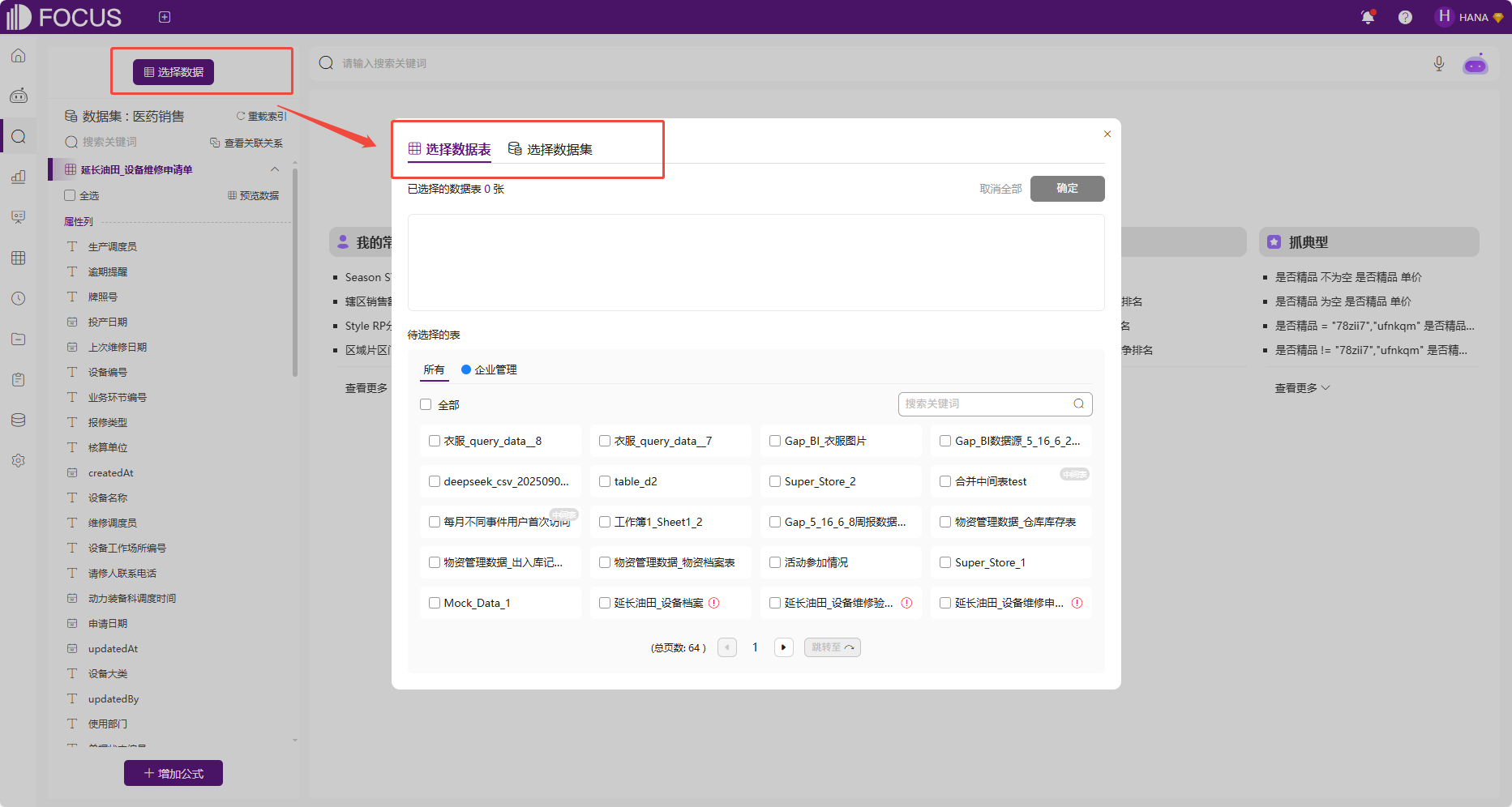
图 2-1选择数据表
如何搜索
搜索框中的可识别搜索语句包括数据列、数据列的同义词、关键词以及公式。这里需要注意,DataFocus系统对数值型列名数据,不加限定的条件下,默认使用“总和”的聚合方式展示。
具体的关键词和公式用法参考关键词和公式章节。
列名歧义
同时选择多个数据表时,由于不同的数据表中可能存在同样的列名称,因此需要清楚歧义,选择正确的映射。
用户在搜索框中输入搜索语句时,当有歧义语句出现时,系统会进行提示,显示该语句有歧义,并列出多个不同选项询问想要如何映射,只要点击对应的表名即可。已选定的歧义可以进行修改。将鼠标移到歧义列名处,同样会弹出多个歧义选项,重现点击选择即可修改歧义
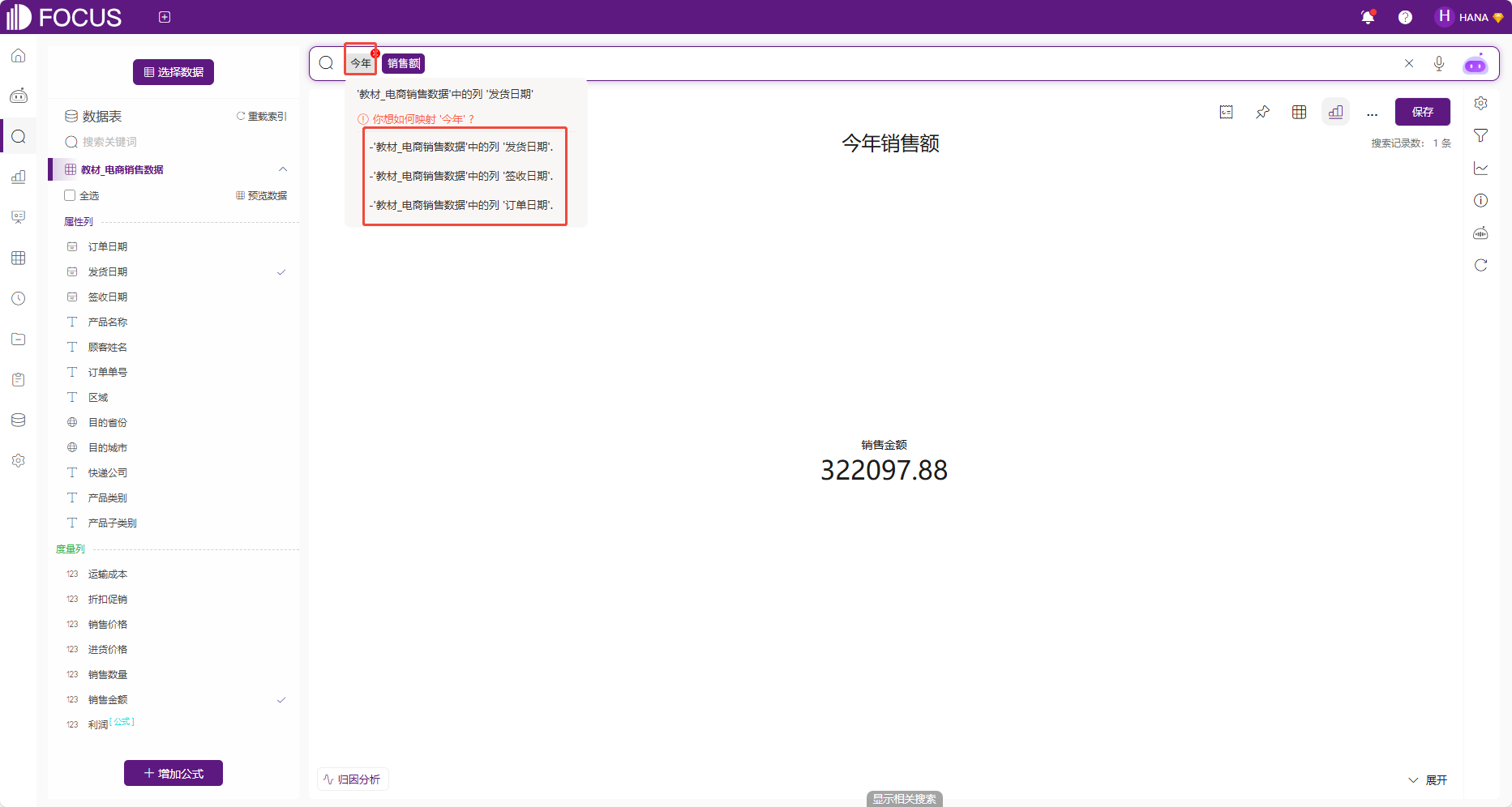
图 2-2列名歧义
图形切换
系统会根据用户当前输入的字段类型和字段个数,自动推荐比较合适的图表类型。用户也可以利用“图表转换”按钮选择更加美观合适的图表类型,满足用户的可视化需求。灰色表示该搜索结果不适合用此类图形展示,彩色表示该搜索结果适合用此类图形展示。
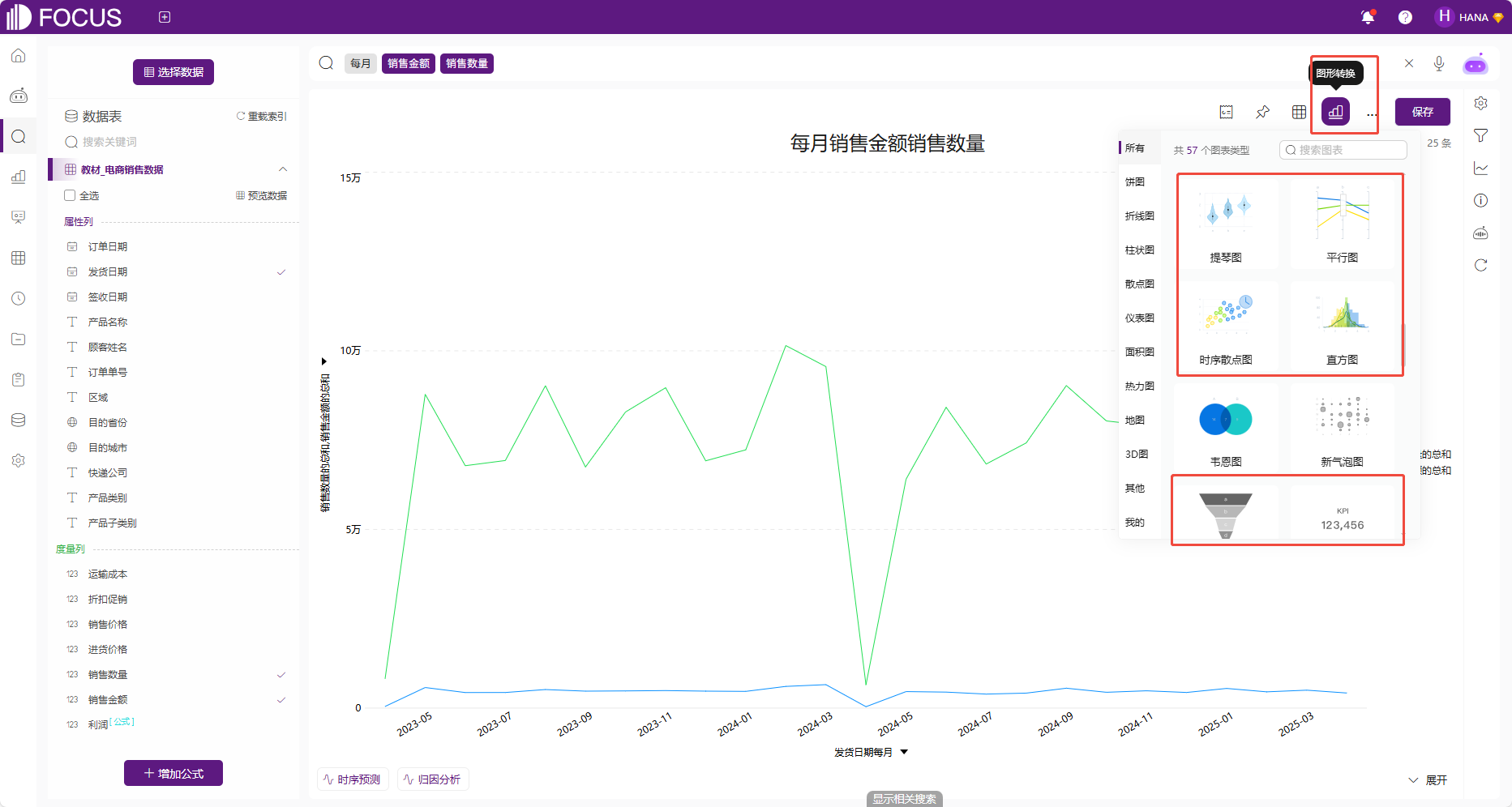
图 2-3图形转化
除此之外,点击数值表,可以将搜索结果以数值表的形式显示。
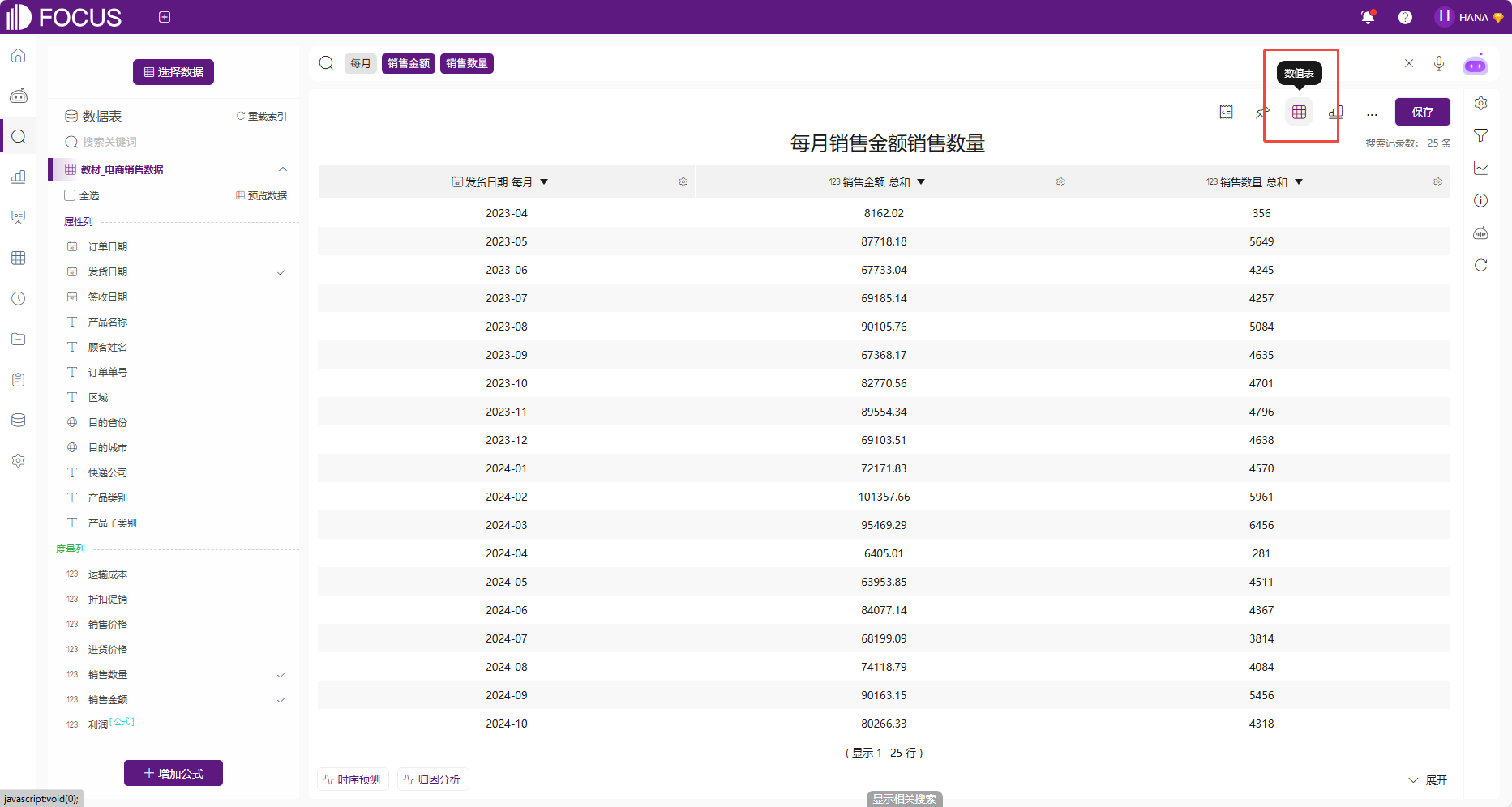
图 2-4数值表
图形类型与实现前提
DataFocus系统中支持的基本图表类型有柱状图、堆积柱状图、折线图、面积图、饼图、环图、散点图、气泡图、新气泡图、条形图、堆积条形图、漏斗图、帕累托图、KPI指标图、数字翻牌器、仪表图、完成度、水位图、火柴图、雷达图、组合图、位置图以及树形图等,这些都是日常分析中最常出现的图表类型。
除了上面介绍到的经常会用到的基础图形,DataFocus系统还支持一些稍微复杂但非常美观的高级图表,包括矩形树图、分解树图、关系网络图、词云图、瀑布图、旭日图、打包图、弦图、桑基图、箱型图、平行图、时序柱状图、时序条形图、时序散点图、时序气泡图、极坐标柱状图、子弹图、日历热图、位置经纬图、经纬图、经纬气泡图、经纬热力图、经纬统计图、轨迹图和直方图等,其中时序柱状图、时序条形图、时序散点图、时序气泡图都属于动态图表,会根据数据中的时间日期进行变动。
| 编号 | 图表类型 | 前提(Attribute表示属性列、Measure表示数值列、Legend列是Distinctcount是50以内的属性列) |
| 1. | 柱状图 | 问题包含至少1个Attribute列,至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 2. | 折线图 | 问题包含至少1个Attribute列,至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 3. | 饼图 | 问题包含至少1个Measure列,至少1个Attribute列; 查询结果记录不超过100; 当满足饼图条件时,如果只有1个Measure列,则优先显示饼图;如果有>1个Measure列,则优先显示环图。 |
| 4. | 环图 | 问题包含至少1个Attribute列,至少1个Measure列(画图时允许2个以上的Y轴); 查询结果记录不超过100; |
| 5. | 散点图 | 问题包含至少1个Attribute列,至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 6. | 漏斗图 | 问题包含至少1个Attribute列,1个有效的Measure列; 1 <= 总条目数 <= 10。 |
| 7. | 气泡图 | 问题包含至少1个Attribute列,至少2个有效的Measure列,允许1个Legend列 (Attribute列)。 |
| 8. | 新气泡图 | 问题包含至少2个Attribute列,至少1个有效的Measure列,允许1个Legend列 (Attribute列)。 |
| 9. | 堆积柱状图 | 问题包含n(n >= 1)个Attribute列,n(n >= 2)个Measure列; 或者n(n >=1 )个Attribute列,1个Measure列,1个Legend列; |
| 10. | 条形图 | 问题包含至少1个Attribute列和至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 11. | 面积图 | 问题包含至少1个Attribute列和至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 12. | 帕累托图 | 问题包含至少1个Attribute列,至少1个Measure列,允许1个Legend列(Attribute列); 总条目数量 < 100。 |
| 13. | 火柴图 | 问题包含至少1个Attribute列,至少1个有效的Measure列,允许1个Legend列(Attribute列)。 |
| 14. | 数据透视表 | 问题包含至少2个Attribute列,至少1个Measure列。 |
| 15. | 位置图 | 仅支持(用中文省份绘制)中国地图和(用英文国家绘制)世界地图; 问题包含1~n个地址列(n < 4,当包含多个地址列时不允许包含平级地址列,如不能有2个省份列,但允许有1个省份列1个城市列); 除地址列外包含1~n个Measure列; 除地址列外不能包含其他Attribute列; |
| 16. | GIS位置图 | 问题包含至少一个地址列(最多3个),1个Measure列; |
| 17. | 组合图 | 问题包含2~n个Measure列,1~n个Attribute列; |
| 18. | 仪表图 | 用户输入n(n >= 1 )的Measure列 , 无Attribute列时可以画仪表图; 用户输入n(n >= 1)个Attribute列 ,n个Measure列(画图时限制1个) ,且数据量 < 10 时允许画仪表图 ; 用户输入n(n >= 1)个Attribute列 ,n个Measure列,且数据量 = 1时允许画仪表图; |
| 19. | 完成度 | 问题包含至少一个Measure列,无属性列; |
| 20. | 水位图 | 问题包含至少一个Measure列,无属性列; |
| 21. | 数字翻牌器 | 问题只能包含1个Measure列,且查询结果记录不超过5; |
| 22. | 雷达图 | 1个Attribute列,n (n >= 1)个Measure列; 1个Attribute列,1 个legend , 1 个Measure列; Attribute列的数值均小于 50 个; |
| 23. | 矩形树图 | 至少一个Measure列(画图时只允许一个Y轴),1个Attribute列; 至少一个Measure列(画图时只允许一个Y轴),1个Attribute列,1个Legend列; |
| 24. | 树形图 | 有且只有一对由嵌套父列构成索引的Attribute列,至少一个非索引Attribute列,至少一个Measure列;注:嵌套父列这对数据需要有一定的层级关系,如部门组织架构关系,岗位层级关系等 |
| 25. | 词云图 | n 个Measure列 (但是画图只允许1个Measure列),1个Attribute列; 且数据少于100条; |
| 26. | 瀑布图 | n个Measure列(但是画图只允许1个Measure列) ,1个 Attribute列; 在增长率这样的语句中优先显示瀑布图; |
| 27. | 弦图 | 问题至少包含2个Attribute列,1个Measure列; 2个Attribute列具有双向流动性,且去重后数据总量 <= 10; |
| 28. | 旭日图 | 问题包含1~3个Attribute列,1个Measure列(图形的层级是按问题中Attribute列的顺序排列); 如果用户输入的Attribute太多,层级太多会导致数据过度膨胀,页面节点太多; |
| 29. | 打包图 | 问题包含1~3个Attribute列,1个Measure列(图形的层级是按问题中Attribute列的顺序排列); 如果用户输入的Attribute太多,层级太多会导致数据过度膨胀,页面节点太多; |
| 30. | 桑基图 | 问题包含至少2个Attribute列,1个Measure列; 2个Attribute列具有单向流动性,且去重后数据总量<100; |
| 31. | 平行图 | 用户输入至少1个Attribute列和至少1个有效的Measure列; Attribute列去重后的数量<=50; Attribute列和Measure列数量总和<=20; |
| 32. | KPI指标 | 问题包含1个Measure列,0~1个Attribute列; 查询结果记录数小于5; |
| 33. | 堆积条形图 | 问题包含n(n >= 1)个Attribute列,n(n >= 2)个Measure列; 或者n(n >=1 )个Attribute列,1个Measure列,1个Legend列; |
| 34. | 时序柱状图 | 问题包含唯一的每年/每月关键词; 除时间关键词外包含1~n个Measure列; 除时间关键词外包含1~n个Attribute列; 查询结果记录数< 1000; |
| 35. | 时序气泡图 | 问题包含唯一的每年/每月关键词; 除时间关键词外包含2~n个Measure列; 除时间关键词外包含1~n个Attribute列; 查询结果记录数< 1000; |
| 36. | 时序散点图 | 问题包含唯一的每年/每月关键词; 除时间关键词外包含1~n个Measure列; 除时间关键词外包含1~n个Attribute列; 查询结果记录数< 1000; |
| 37. | 箱型图 | 问题包含至少1个Attribute列和1个Measure列; 查询结果记录大于10; |
| 38. | 时序条形图 | 问题包含唯一的每年/每月关键词; 除时间关键词外包含1~n个Measure列; 除时间关键词外包含1~n个Attribute列; 查询结果记录数< 1000; |
| 39. | 极坐标柱状图 | 问题包含1个Attribute列(去重后数量<=50),1个时间列(去重后数量<100),1个Measure列; 查询结果记录数>=100; |
| 40. | 子弹图 | 问题包含1个Attribute列,2个Measure列; 查询结果记录<=20; |
| 41. | 日历热图 | 问题包含1~n个Measure列,1个时间列; 且时间列必须按天聚合(时间跨度在3年内)或按小时聚合(时间跨度在30天内); |
| 42. | 轨迹图 | 问题包含有且仅有2对经纬度; 至少1个Measure列; |
| 43. | 直方图 | 问题包含1个Attribute列和1个Measure列; 或者0个Attribute列和多个Measure列; |
| 44. | 位置经纬图 | 问题包含至少一个位置属性列,至少一个Measure列; 多个位置属性列时,地理位置列必须是连续的地理列,例: 国家 省; |
| 45. | 经纬图 | 问题包含合法经纬度,至少0个Attribute列和1个Measure列; |
| 46. | 经纬气泡图 | 问题包含合法经纬度,至少0个Attribute列和1个Measure列; |
| 47. | 3D地球柱状图 | 问题有且仅有一组经纬度数据,至少1个Measure列 |
| 48. | 3D地球散点图 | 问题有且仅有一组经纬度数据,至少1个Measure列 |
| 49. | 3D地球飞线图 | 问题有且仅有两组经纬度数据 |
| 50. | 相关热力图 | 问题至少两个数值列且至少两行搜索数据。 |
| 51. | 矩阵热力图 | 两个属性列,且唯一元素数量不超过50;一个数值列,且数值处于区间[-1,1] |
| 52. | 经纬热力图 | 搜索结果中包含合法经纬度及至少零个属性列和一个数值列 |
表 2图形类型与实现前提
图表属性
DataFocus中,除了支持自由更换图形之外,还支持各种图形的个性化设置,不同图形可设置的功能点有些许区别,用户可以点开设置项,探索其中的差异。每个人的审美和视觉喜好都不一样,DataFocus在可控制的范围内,尽可能地满足每个人的喜好,包括主题颜色、字体设置、数据标签格式等等,都可由用户自行设置。
以折线图为例,在搜索出结果后,点击右上角的“图表属性”,可配置图表属性,其中包括有通用属性配置、线条配置、颜色/线条、X轴、Y轴、图例、网格线配置、数据标签、悬浮文本设置、标度、分析器配置、拓展搜索结果、定时刷新等。
通用配置
通用属性配置,主要是用来设置主题颜色、字体大小、是否隐藏聚合方式、是否禁止动画、图例数量限制等功能,如图2-5。为了提升可视化效果,将字体大小设置为加粗和倾斜,此时画图区域文字都会加粗和倾斜。如果只想在X轴和Y轴显示列名,则可以勾选隐藏聚合方式,那么此时的X轴“发货日期每月“将会修改为“发货日期”,Y轴“销售金额的总和”将会修改为“销售金额”。图例数量限制可以作为图例列的列中值数量限制,默认情况下,列中值去重后的数量<=50的属性列才可以作为图例,在这个配置下若某一属性列去重后的列中值大于50,则不允许配置为图例。
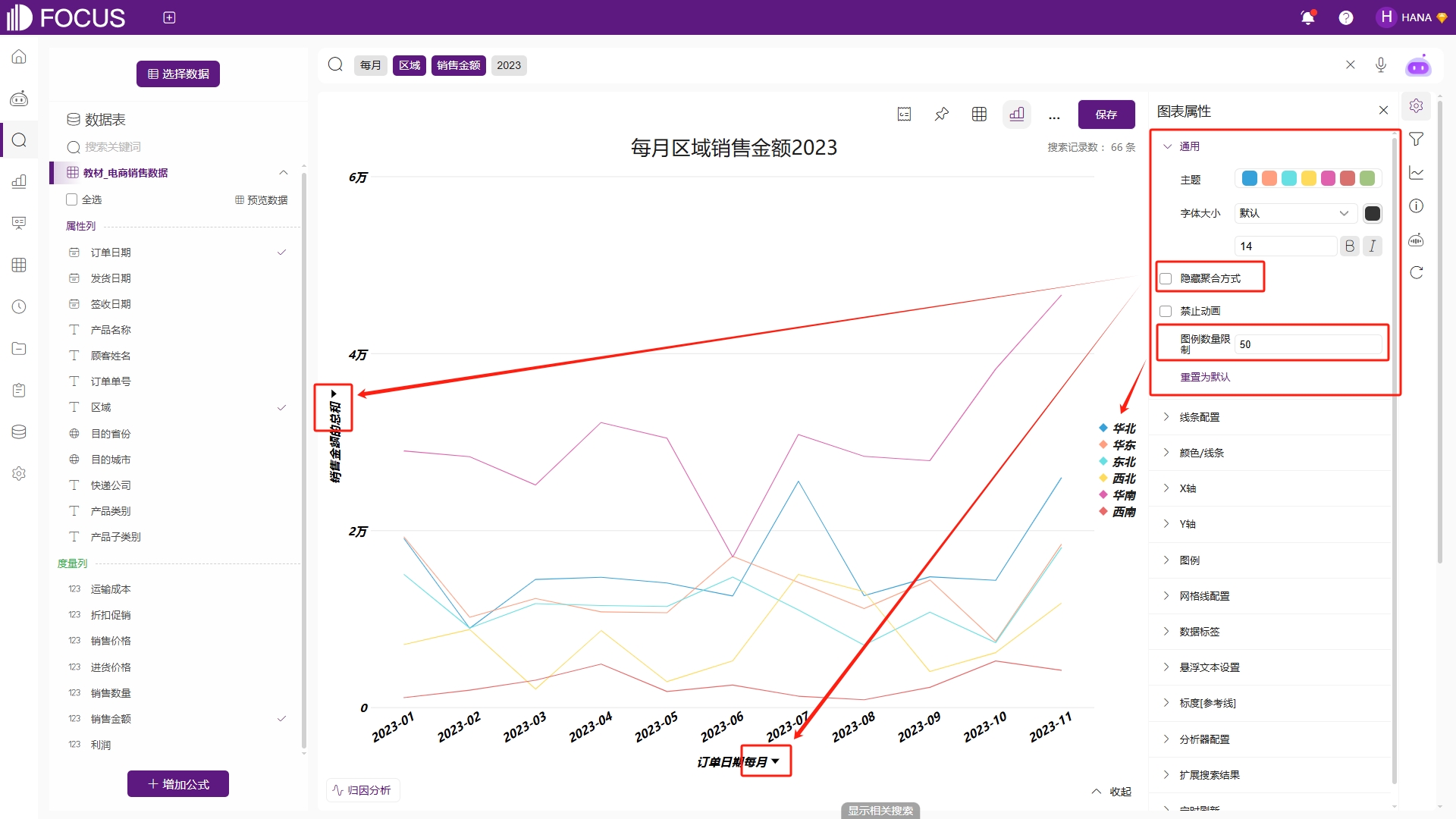
图2-5 通用配置
地图类图表的通用配置和其他图表不同,包括可选 Mapbox 或天地图作为底图数据源,配置项将“主题”替换为专有的“地图主题”,并可分别精细调控地球底色、陆地、水域、道路、地标、边界等各要素的颜色。
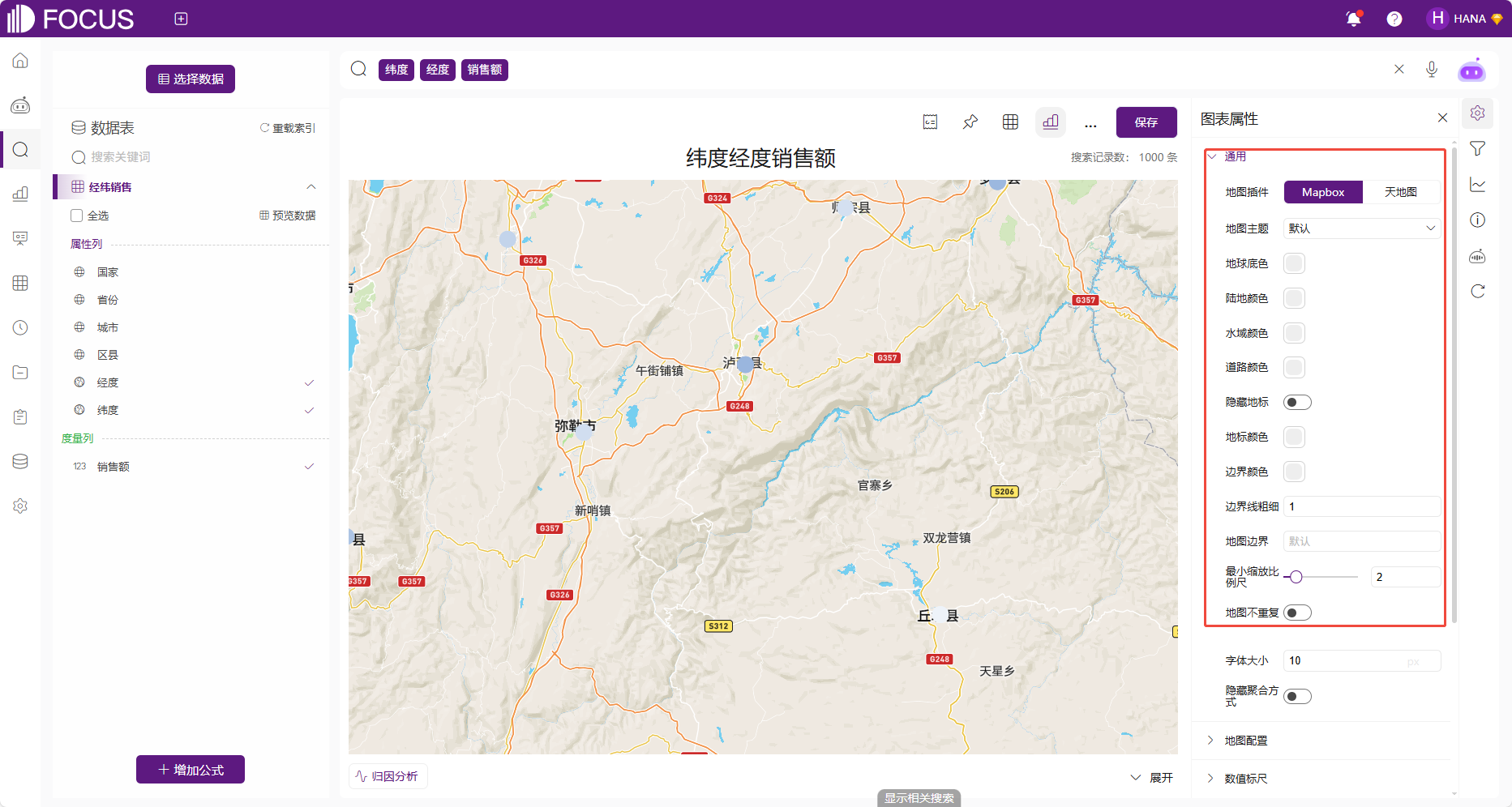
图 2-6地图通用配置
地图配置
地图类图表部分还可以进行地图配置,包括配置地图的颜色模式,主要应用于数据的展示。区别于通用中对地图样式的颜色配置,该地图配置中的颜色配置直观地表达数据的分布和差异。两者结合,共同定义了数据如何在地图背景上呈现。
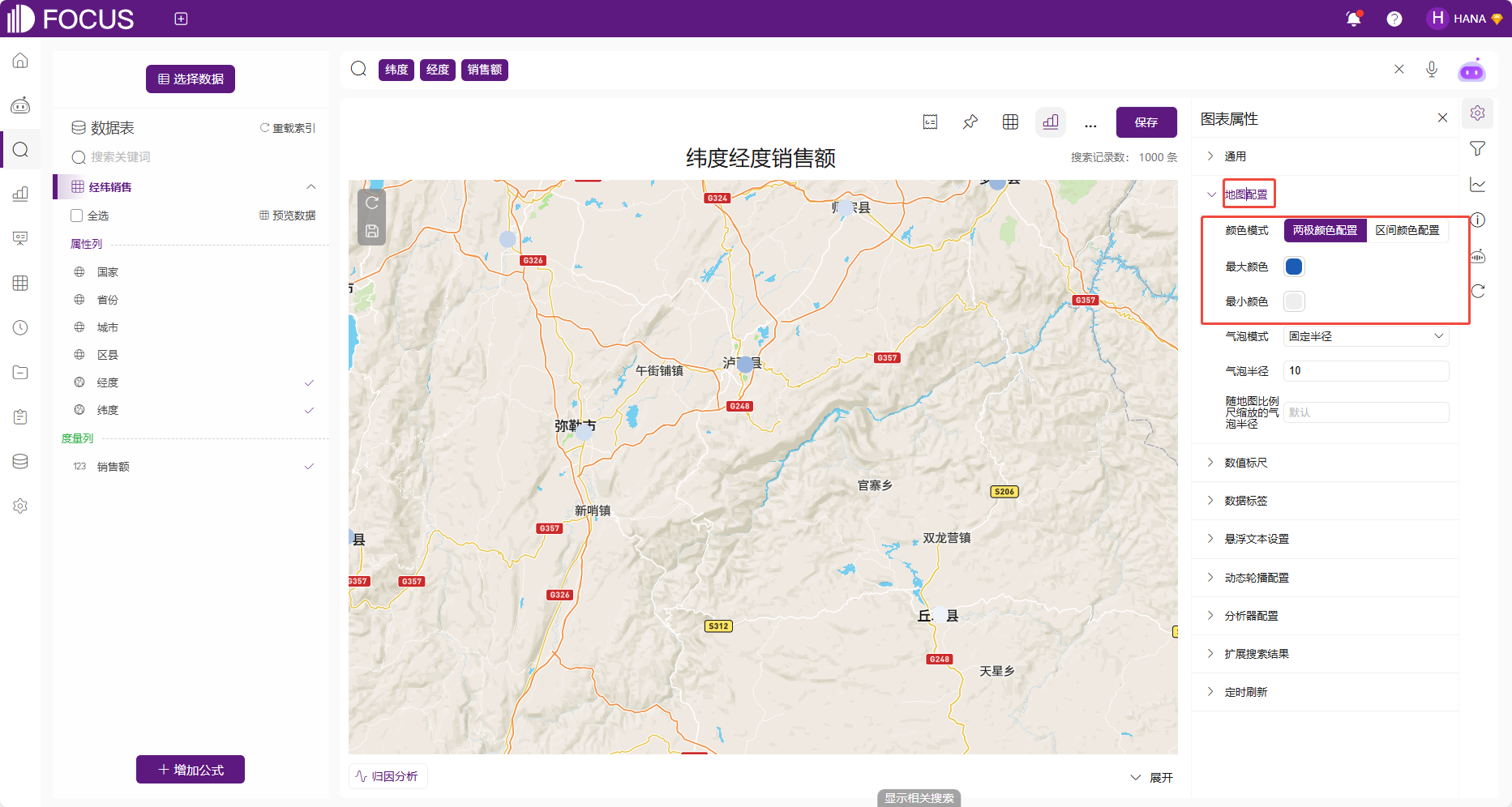
图 2-7地图配置
饼/环配置
饼图专属的配置——饼配置,可配置饼图模式,以及通过调整半径大小、起点、圆角半径及饼间距,可控制扇形的尺寸、起始位置、边缘弧度与分布间距,实现数据对比的可视化优化。
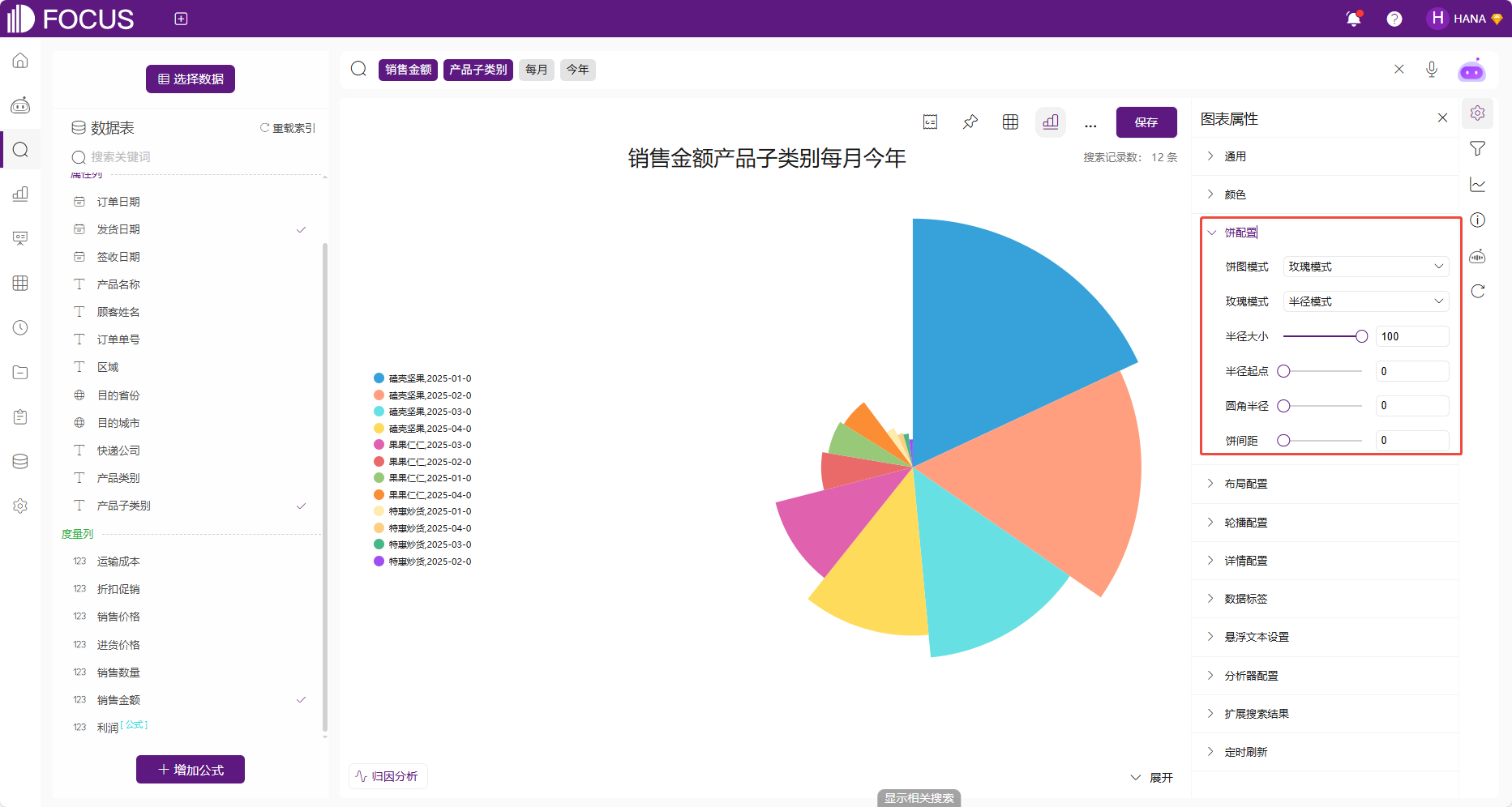
图 2-8饼配置
环图也可通过环配置,调整环的半径大小和起点。
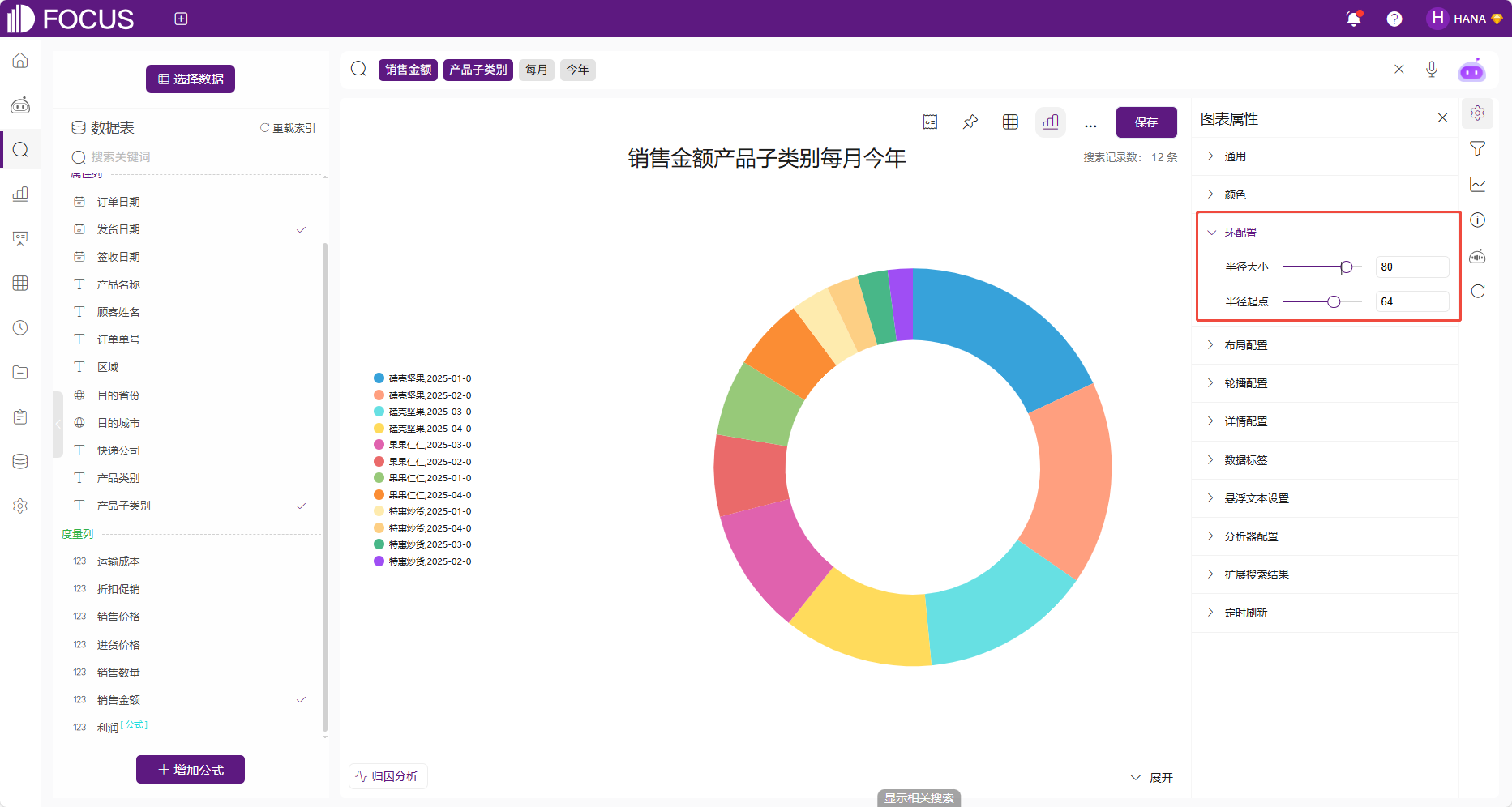
图 2-9环配置
线条配置
线条配置、颜色/线条则是折线图特有的图表属性配置,可配置折线的线条样式、宽度、颜色以及节点样式等,如图2-10。在线条配置中线条样式选择自然曲线、线宽输入2、虚实选择虚线,此时折线图中的折线变为线宽为2,样式为自然曲线的虚线。勾选显示节点,可以对节点的半径、节点样式、节点是否描边进行配置,例如配置节点为菱形且有黑色描边以凸显节点。勾选阴影线,折线下方则填充对于图例颜色阴影。
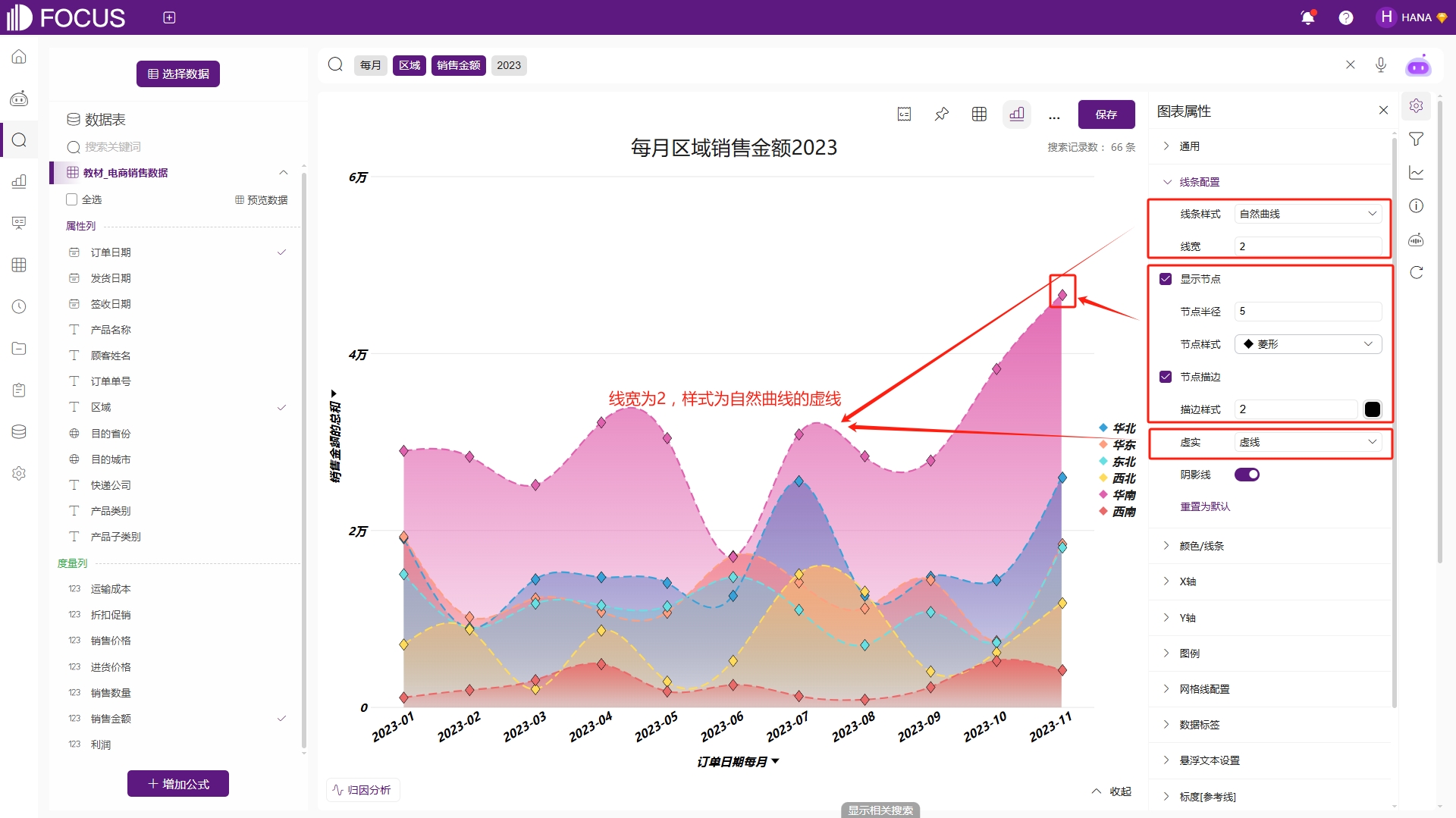
图2-10 线条配置
除了基础的折线图,帕累托图和组合图都含折线,因此也都有线条相关配置。
柱体配置
由于组合图和帕累托图都可以同时用柱体和线条展示数据,他们都可以自定义柱状图显示效果。柱体配置支持设置固定柱宽或每页刻度数以控制显示密度,最小柱宽确保可读性,柱宽比例滑块调节粗细平衡,并可通过堆积展示选项实现多数据系列的叠加呈现(只有组合图),从而优化数据可视化布局与对比分析。
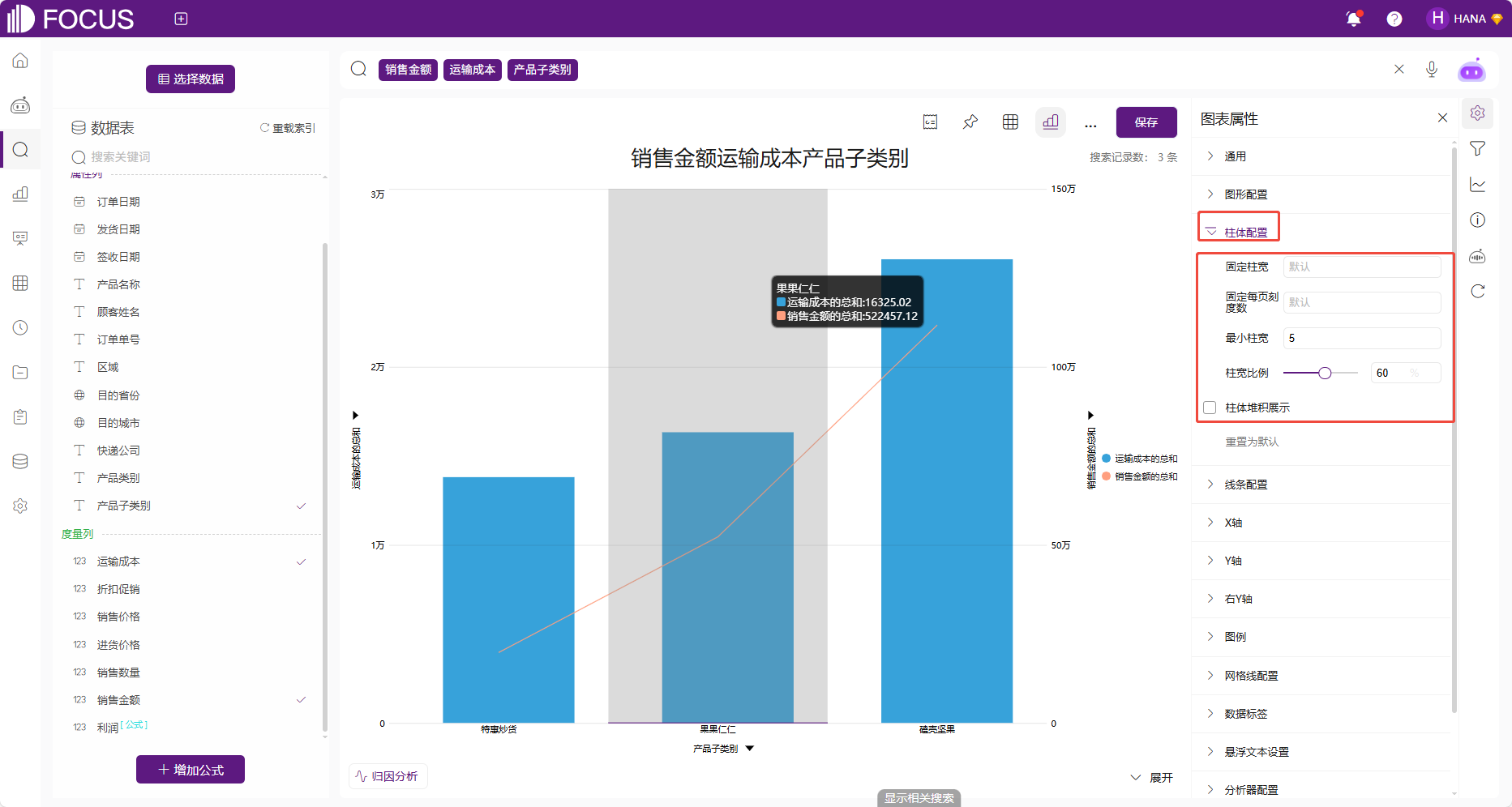
图 2-11柱体配置
X轴Y轴配置
针对有X轴和Y轴的图表的可配置项,例如饼图就没有这两项配置。X轴、Y轴可配置是否显示图轴、图轴字体样式、刻度、轴标题、对齐方式等。以X轴配置为例,轴标签和轴标题可分别配置,其中字体样式会继承通用配置中的字体样式当然可单独修改,例如将X轴的轴标题字体颜色设置为蓝色,同时设置轴标题内容为“日期”,如图2-12。
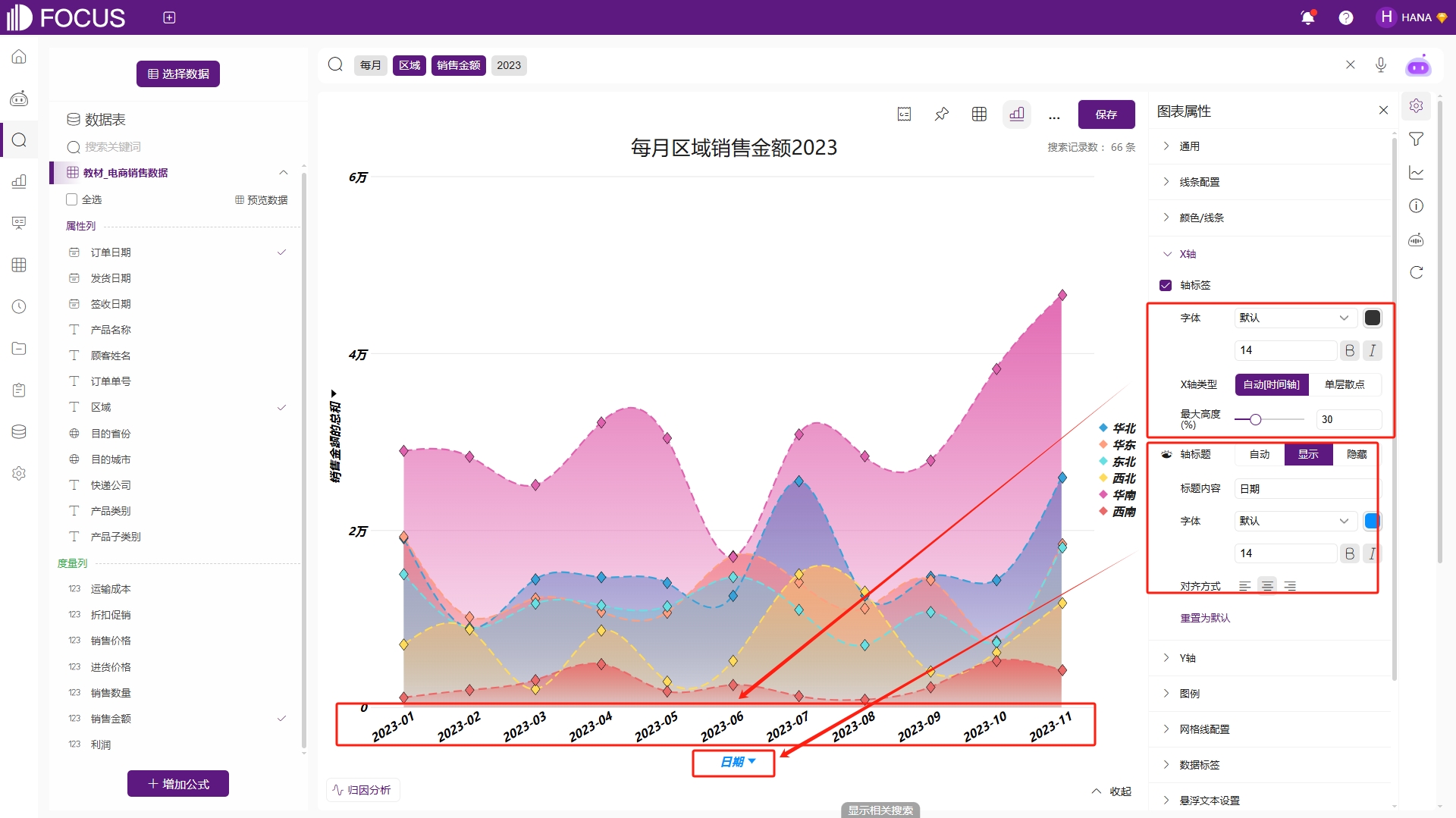
图2-12 X轴配置
图例配置
支持配置图例的字体样式、位置、边距、间隔等。例如为了实现图例显示在画图区域上方,可在图例配置的位置选择顶部,并且调整间距为70以获得更好的可视化效果,如图2-13。
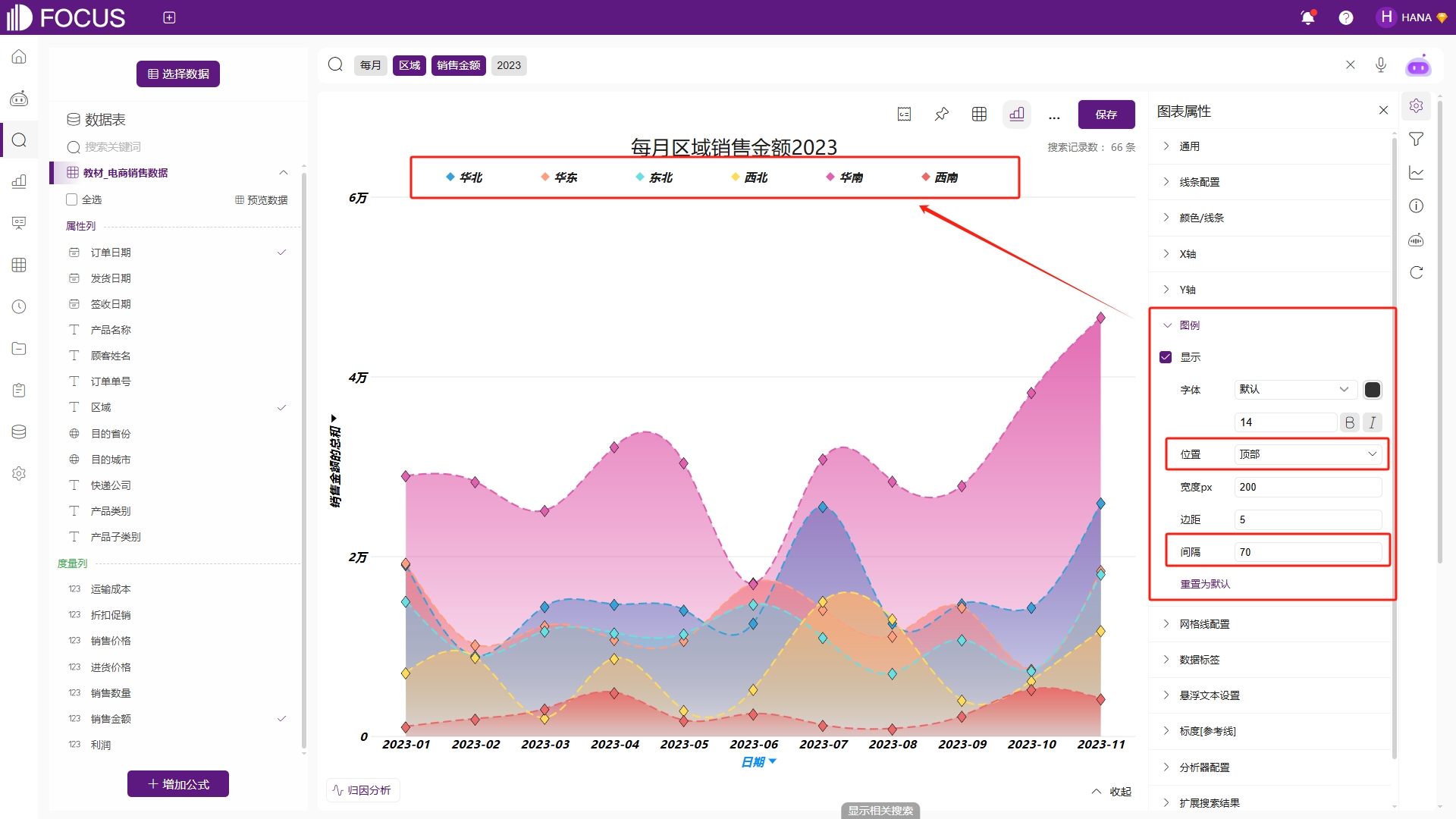
图2-13 图例配置
网格线配置
主要用来配置是否隐藏网格线、零线,以及配置样式。例如为了画图区域更简洁,我们可以勾选只显示零线,并且配置零线颜色为蓝色,此时除零线外其余网格线将被隐藏,只显示一条蓝色的零线,如图2-14。
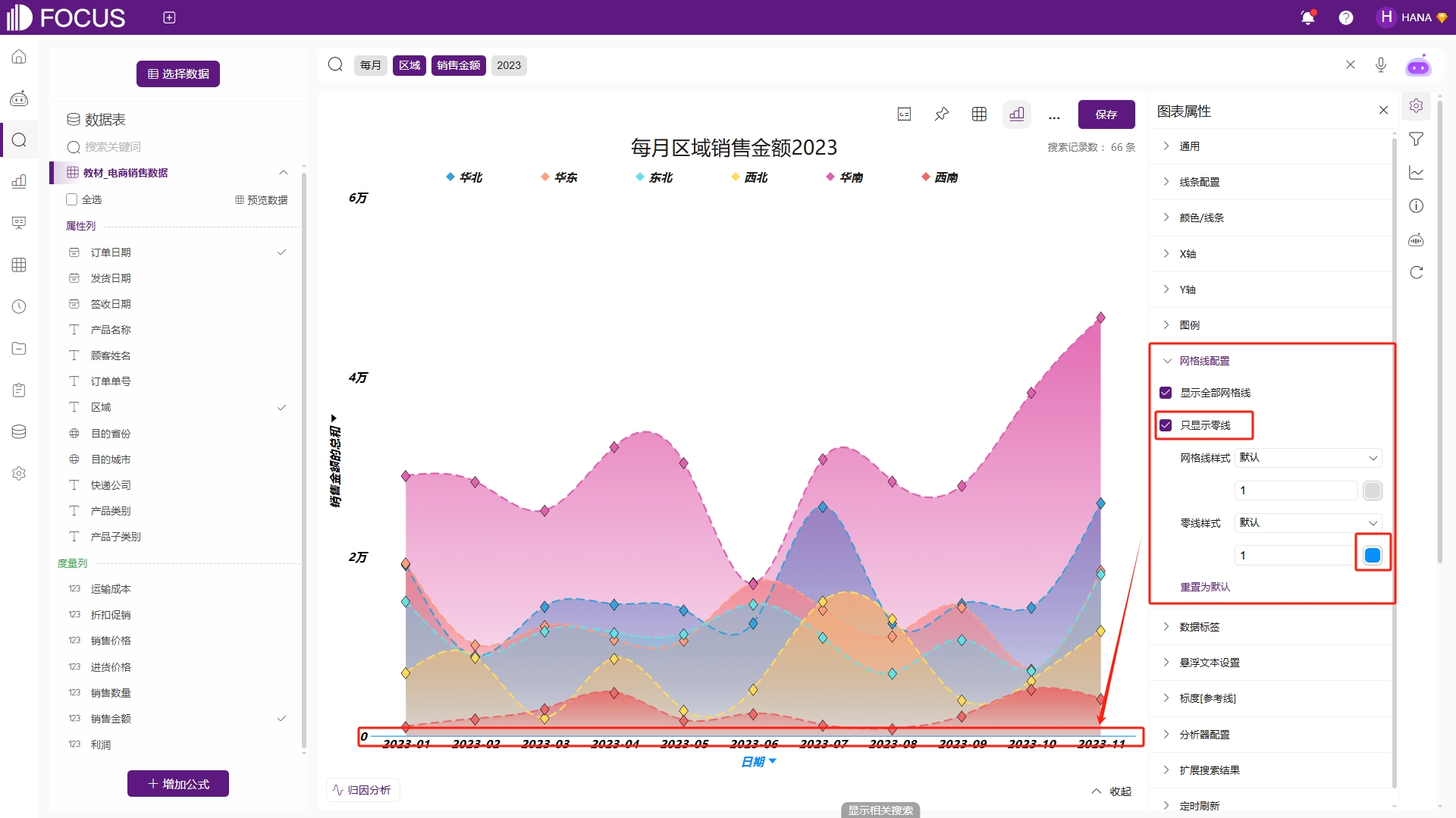
图2-14 网格线配置
数据标签格式配置
勾选显示数据标签后可配置数据标签格式,包括字体样式、显示文本、位置、旋转、显示范围,是否允许重叠。例如为了更好地观察各区域销售金额的最大值和最小值,在文本配置中通过不同的宏替换成想要显示的内容,使用宏“ [区域(第2列)] [销售金额(第3列)]”,即可将默认的数值内容更改为区域和销售金额,同时显示范围选择“最大/最小”,图表的数据标签将只显示各区域销售金额的最大及最小值,如图2-15。
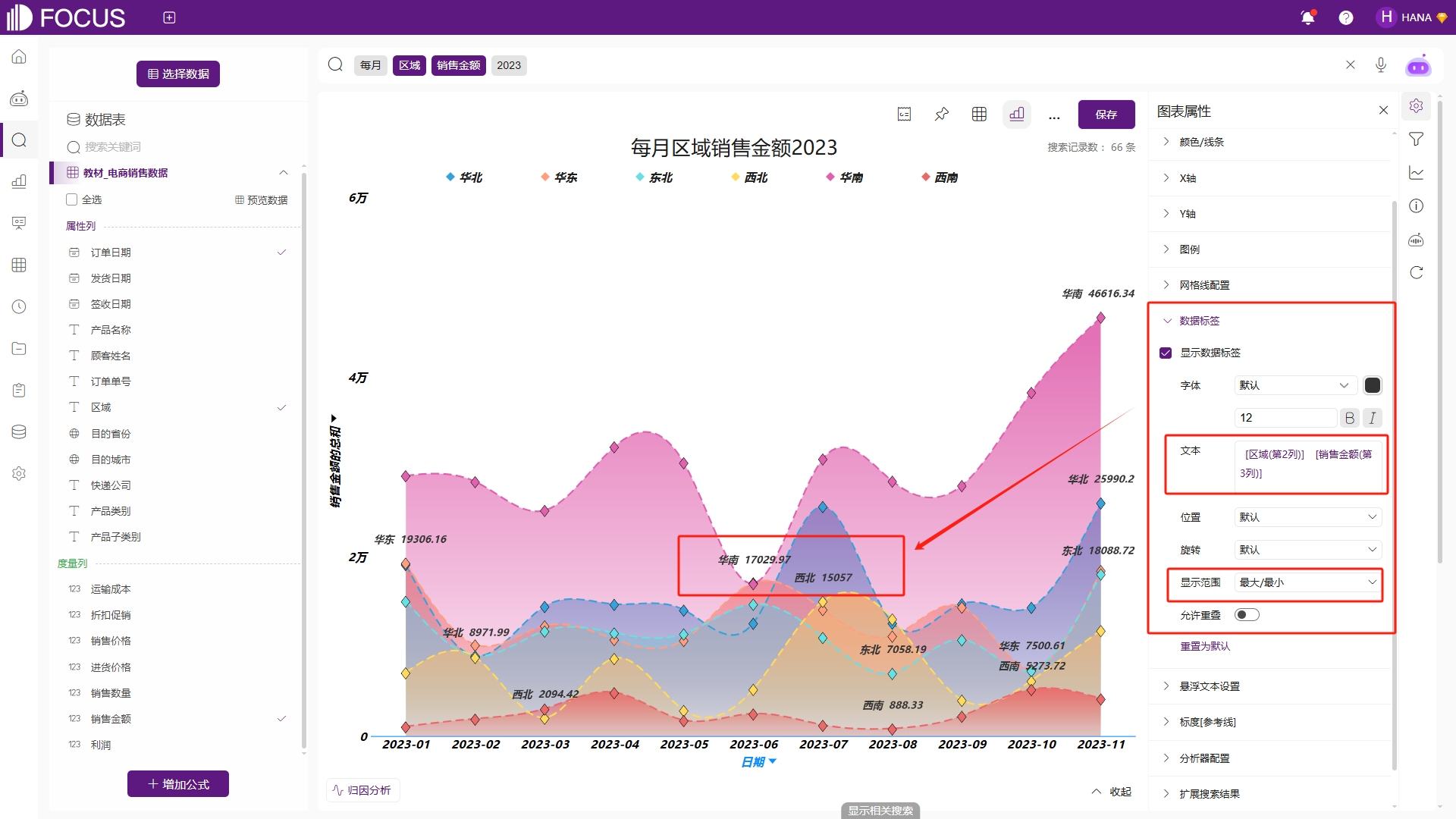
图2-15 数据标签配置
悬浮文本配置
和数据标签类似,悬浮文本配置也可通过替换宏的方式配置。例如配置悬浮文本为“[发货日期(第1列)] [区域(第2列)] [销售金额(第3列)]”,此时数据悬停于任一节点,将按显示该节点的发货日期、区域及销售金额数据,如图2-16。
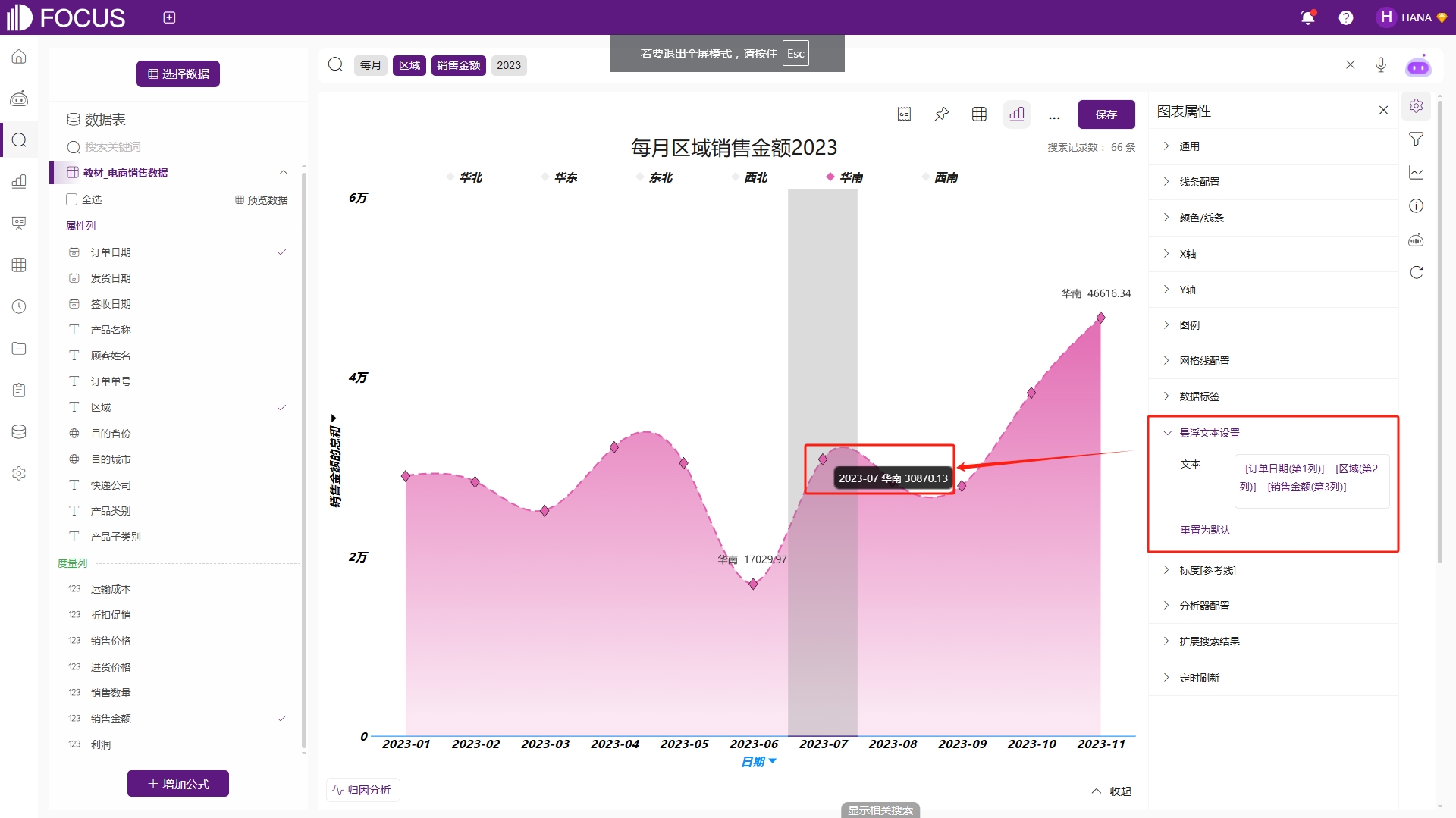
图2-16 悬浮文本配置
标度配置
允许用户自定义多个Y轴标度[参考线],Y轴文本,显示颜色及显示样式,只有在标度值与颜色被设置过,才会在图形中显示直线模式下,默认标度值为第一个数值列的平均值。标度类型可选择直线或者范围,例如配置标度为标准差和平均值的区域范围,那么将标度上限设置为“平均值”,下限设置为“标准差”即可,如图2-17。
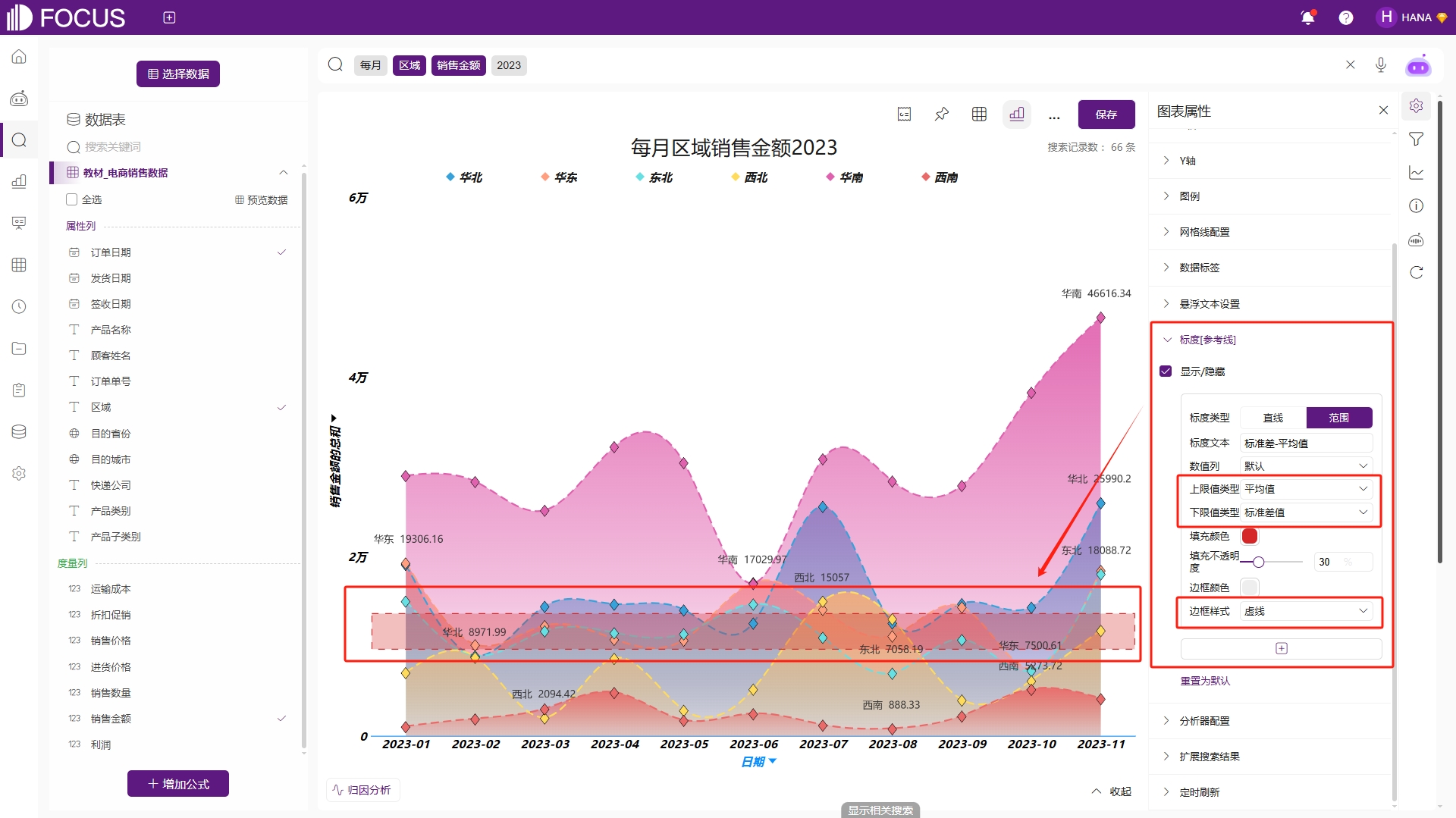
图2-17 标度配置
分析器配置
选择当前搜索结果可以配置的分析器,默认为无分析器。可按需选择分析器。相关性分析:使用最小二乘法绘制出拟合线两个度量列数据的拟合线。离群分析:检测数据中存在的个别数值与其他数值相比差异较大的数据。时序预测:使用Holt-Winters指数平滑分析方法预测未来数据,如图2-18。
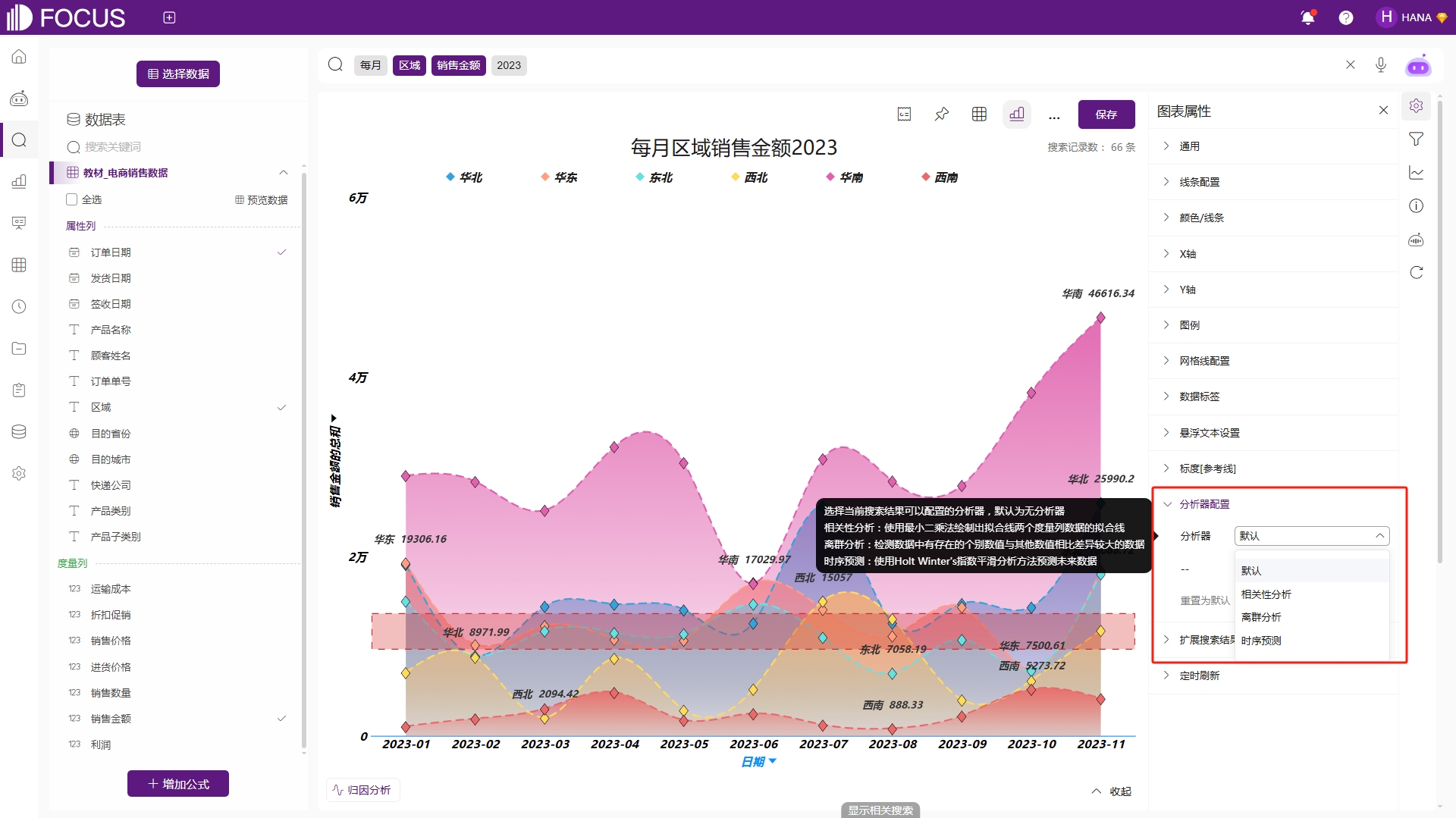
图2-18 分析器配置
扩展搜索结果
搜索结果数量的配置,默认为1000,最多返回100000。多用于返回结果较多时,通过该配置提升返回数据行数,例如搜索“订单日期 订单单号 运输成本”,数据超过了1000行,为了查询所有数据,将搜索行数配置为5000,此时返回了所有符合条件的数据,行数为4147,如图2-19。
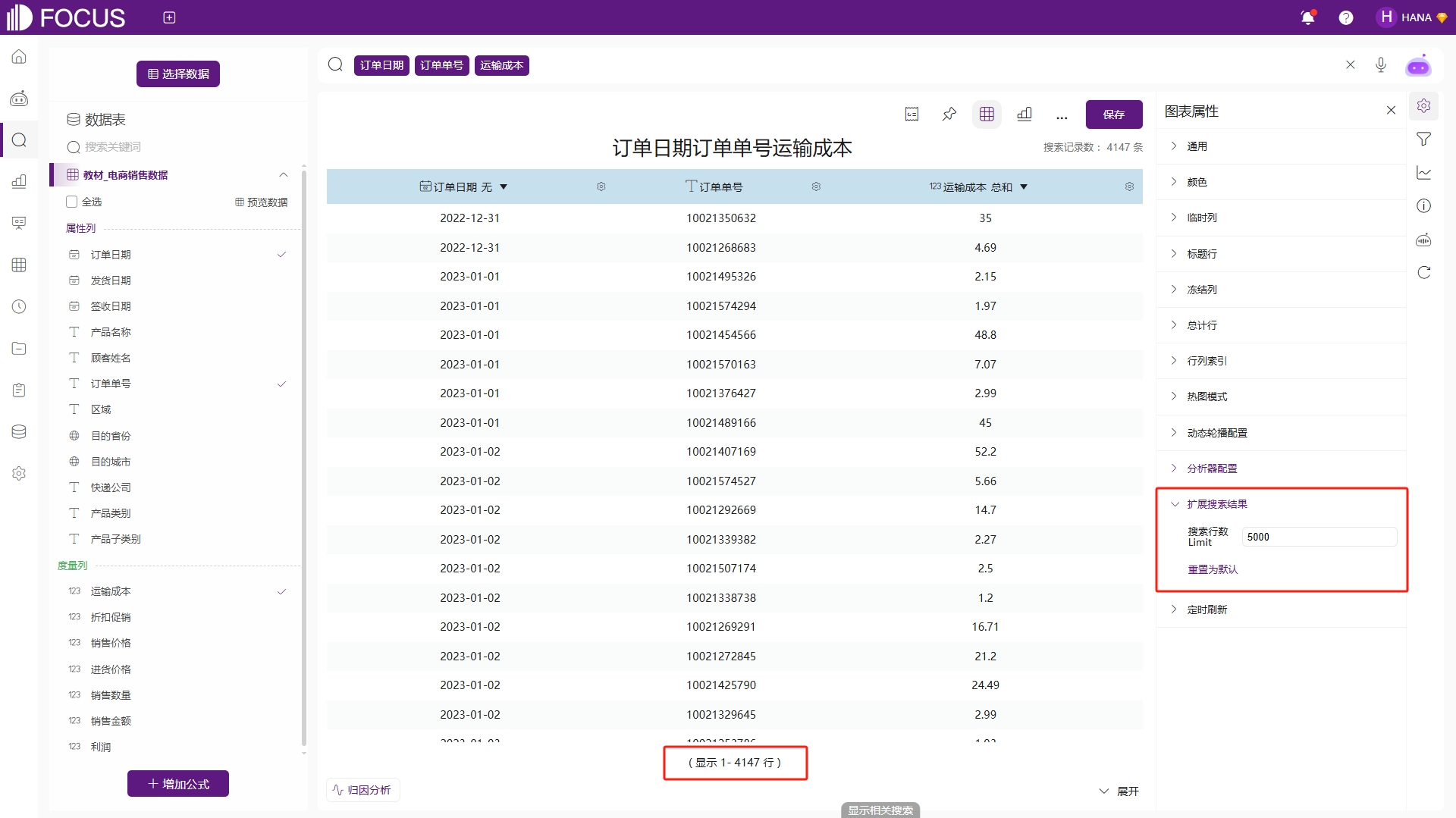
图2-19 扩展搜索结果配置
动态轮播配置
时序柱状图和时序条形图、时序散点图、时序气泡图四个时序图为了展示时间序列数据的变化趋势,支持动态轮播配置,自动按时间顺序播放数据变化。动态轮播配置默认1s,可配置0.5~10s。
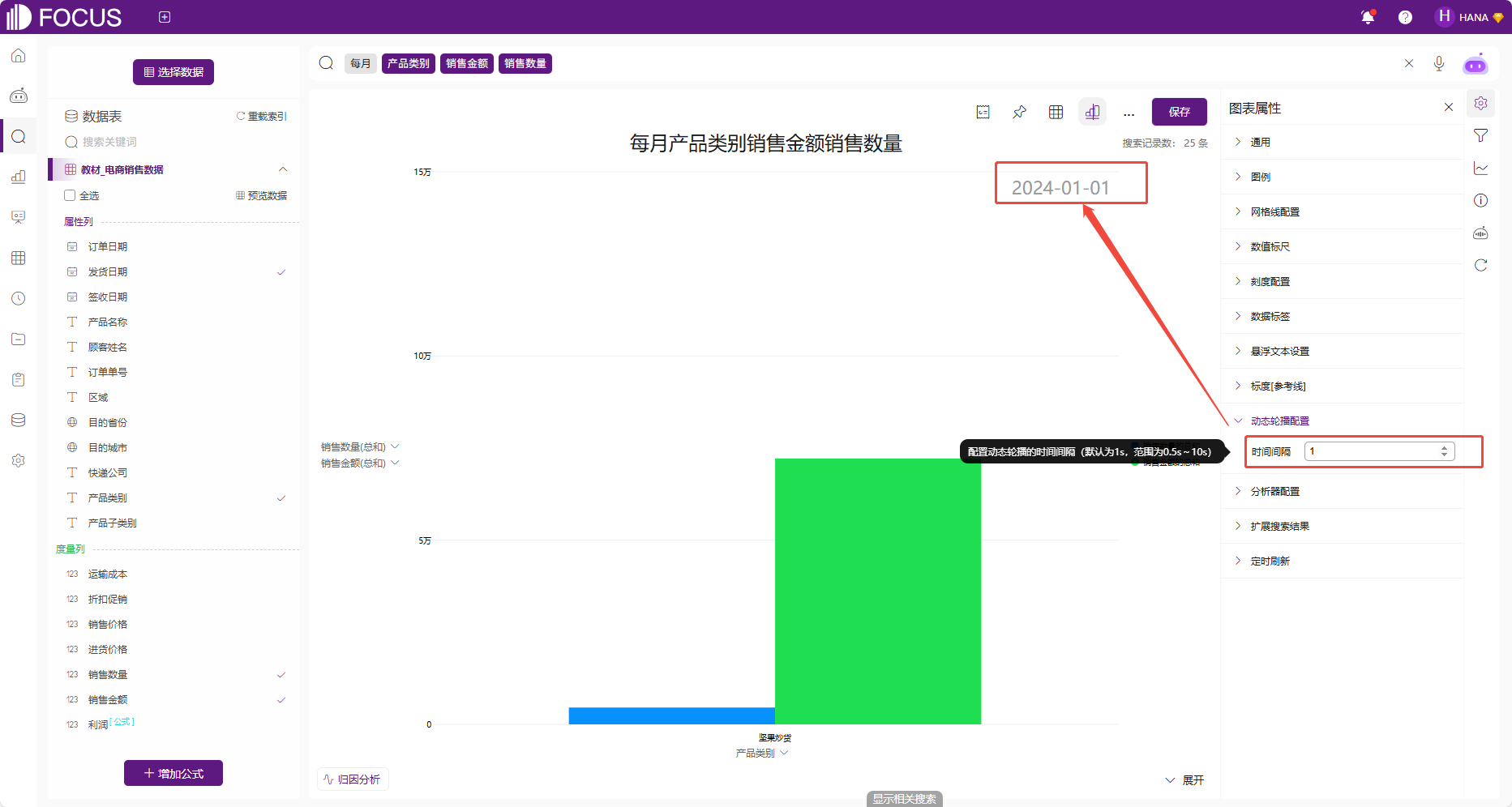
图 2-20动态轮播配置
定时刷新
定时刷新配置是启动并配置在数据看板内的定时刷新间隔,配置后,当前历史问答在数据看板中会定时刷新数据,变化后反应在图形中。定时刷新只作用在使用了直连表的问答上;导入表数据更新后,问答数据会自动更新。配置间隔时间(s)后,当前问题将会按照配置的时间间隔定时刷新。间隔时长至少>20s。例如为了获取最近6个月的销售金额,制作了一个KPI历史问答用于数据看板,并且希望伴随每日直连的销售数据源更新,该结果也及时在数据看板被更新,则可以勾选“启动在数据看板内的自动刷新”,如图2-21。
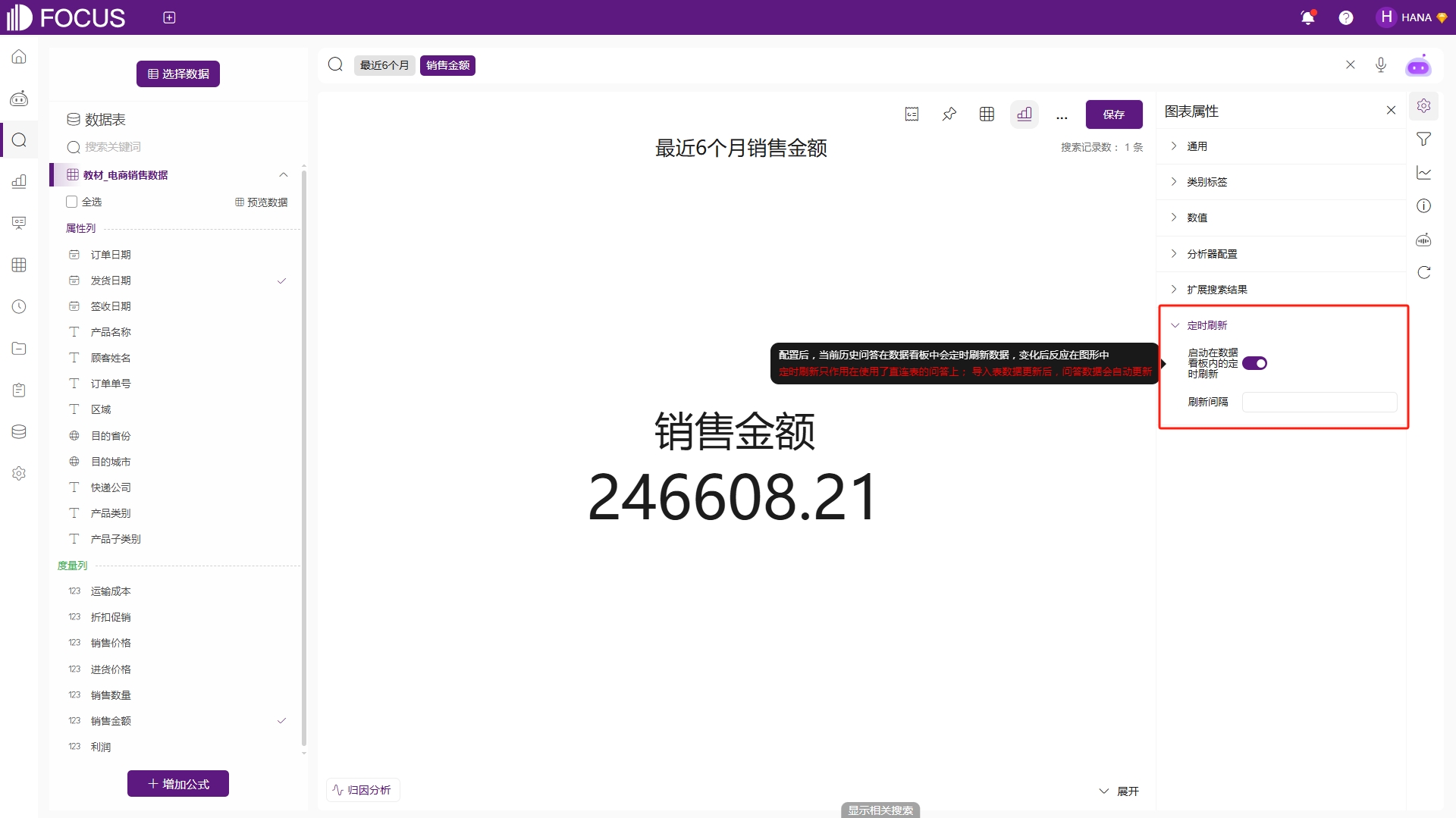
图2-21 定时刷新配置
行列索引
对于数据表可配置是否显示行列所索引。并且对于行索引可配置显示名、列宽。行索引常用于显示行序号,例如将行索引的显示名修改为“序号”。特别的是,还可以配置行索引的单个索引样式,如图 2-22,对索引值为6的单条索引配置字体颜色为红色,背景颜色为蓝绿色。
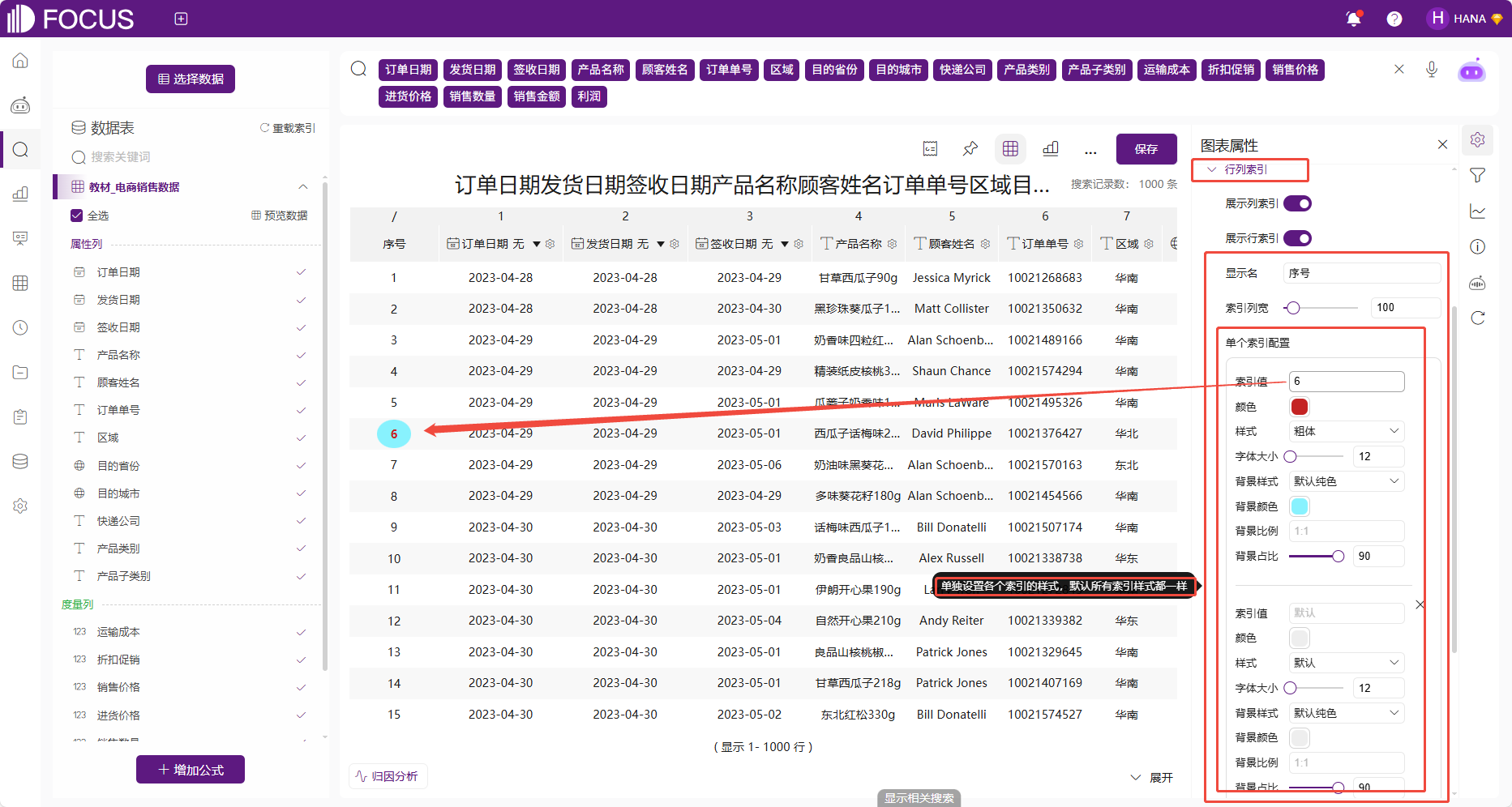
图 2-22行列索引
总计行
对于数值表、数据透视表、交叉表可配置是否显示总计行。总计行配置包括总计行样式、总计行位置以及是否隐藏属性列计数。
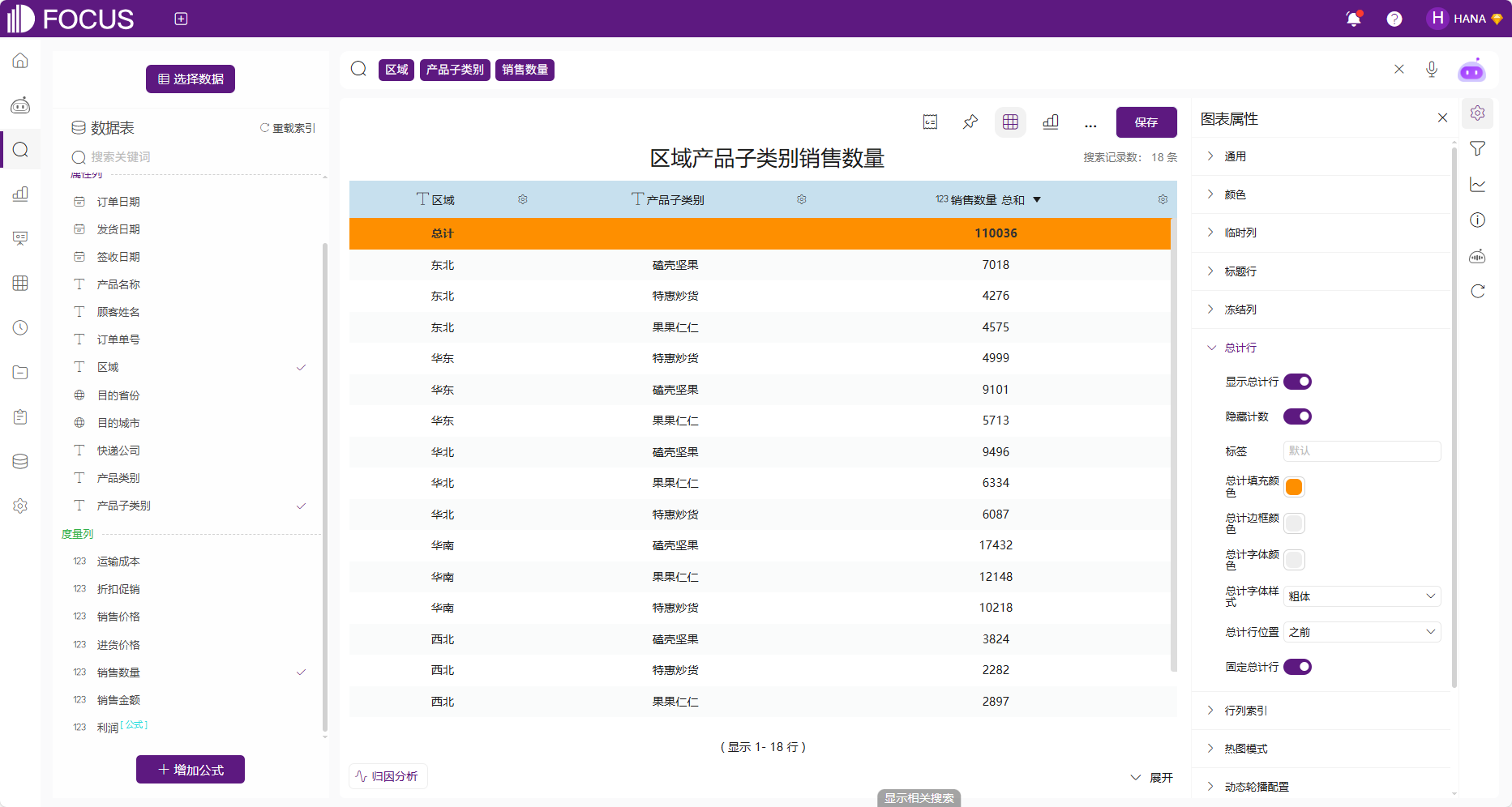
图 2-23总计行
小计行
数据透视表可以配置小计行,包括小计行的样式以及可以配置小计行显示为在总计中所占百分比。
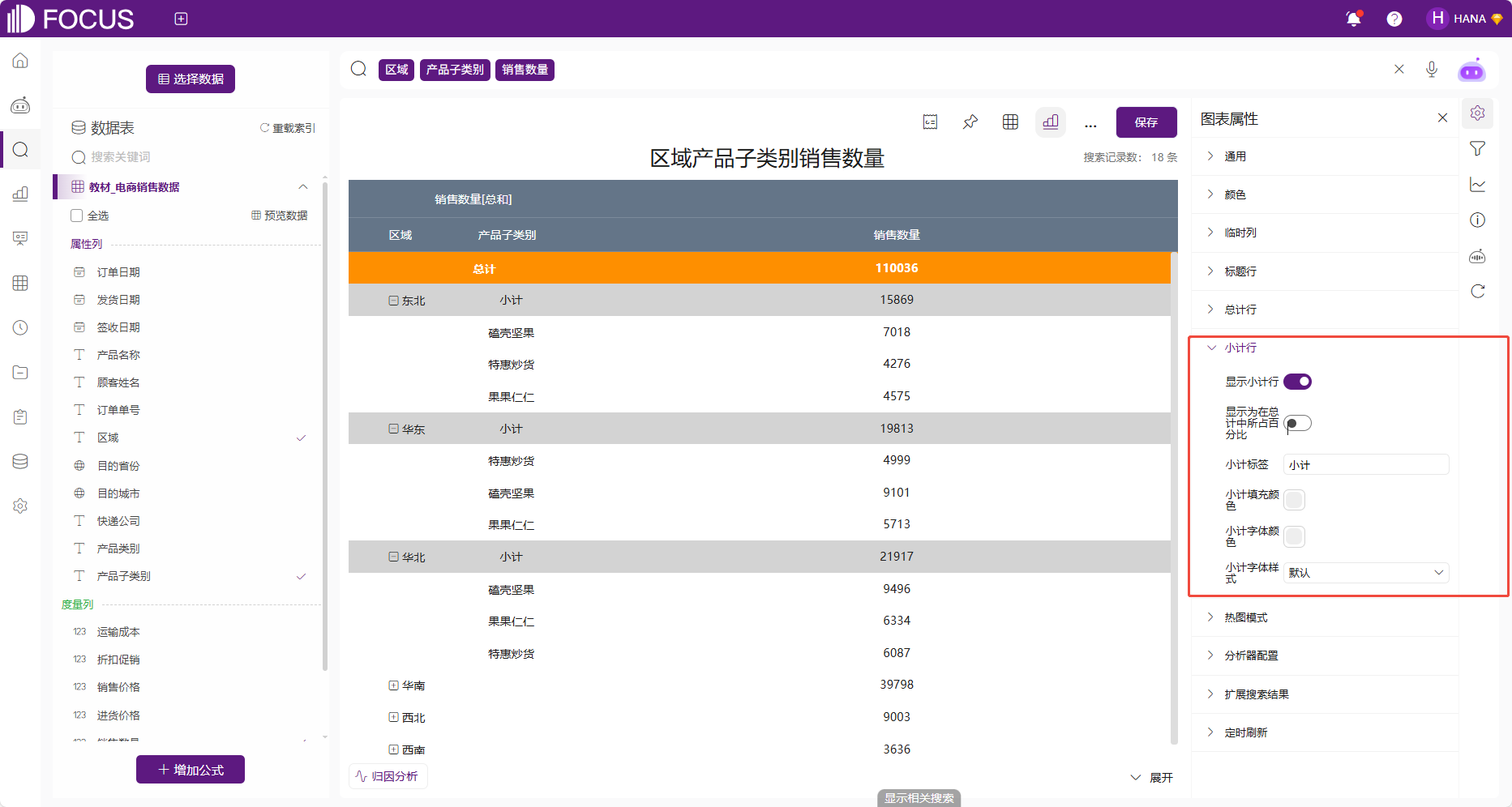
图 2-24小计行
冻结列
数值表可配置冻结列,具体配置方法是输入需要冻结的前N列,例如冻结前3列,还支持配置冻结列的样式,如图 2-25。
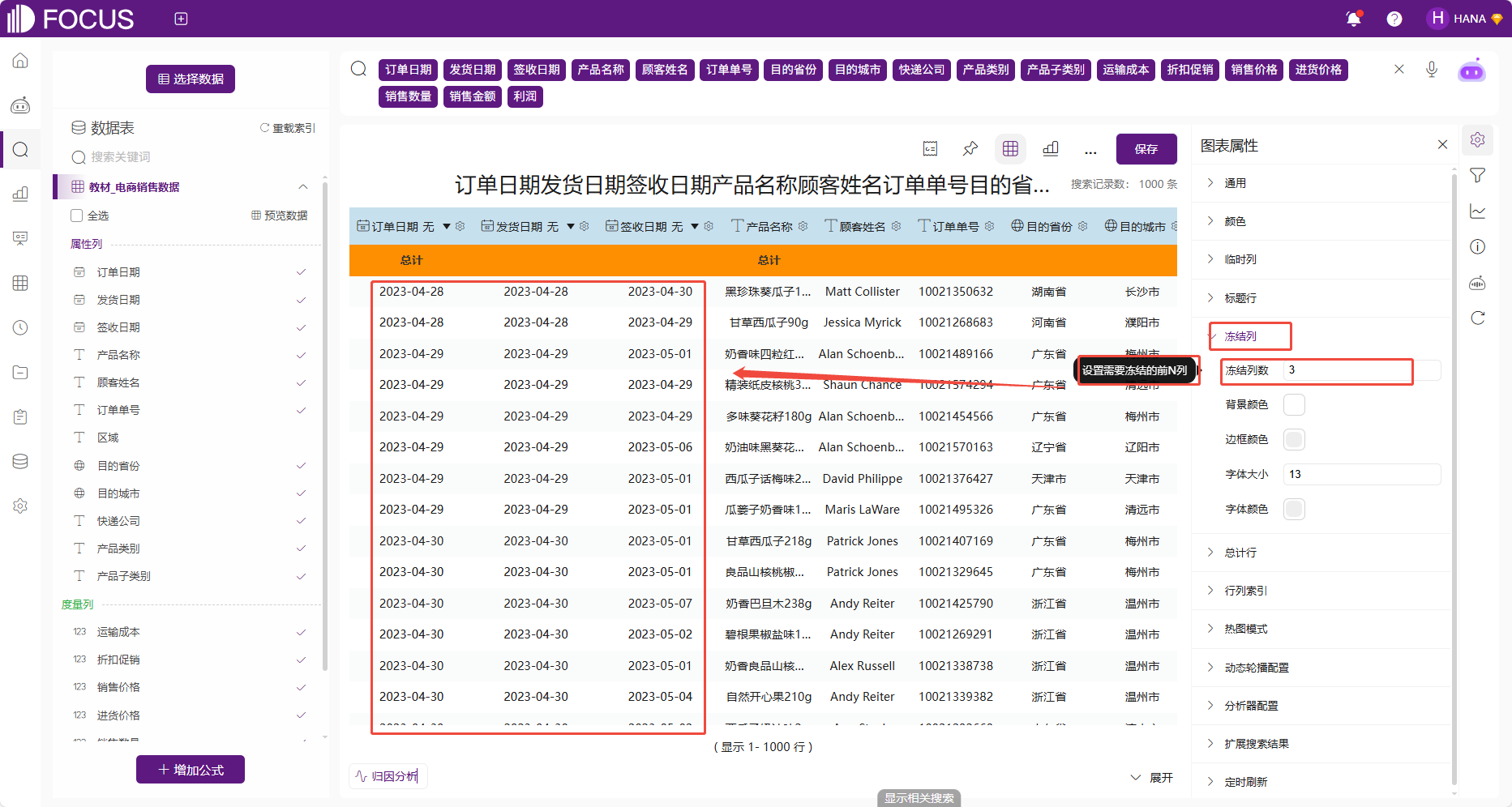
图 2-25冻结列
标题行
数值表和数据透视表可配置标题行,包括标题行的样式,以及是否隐藏表头。
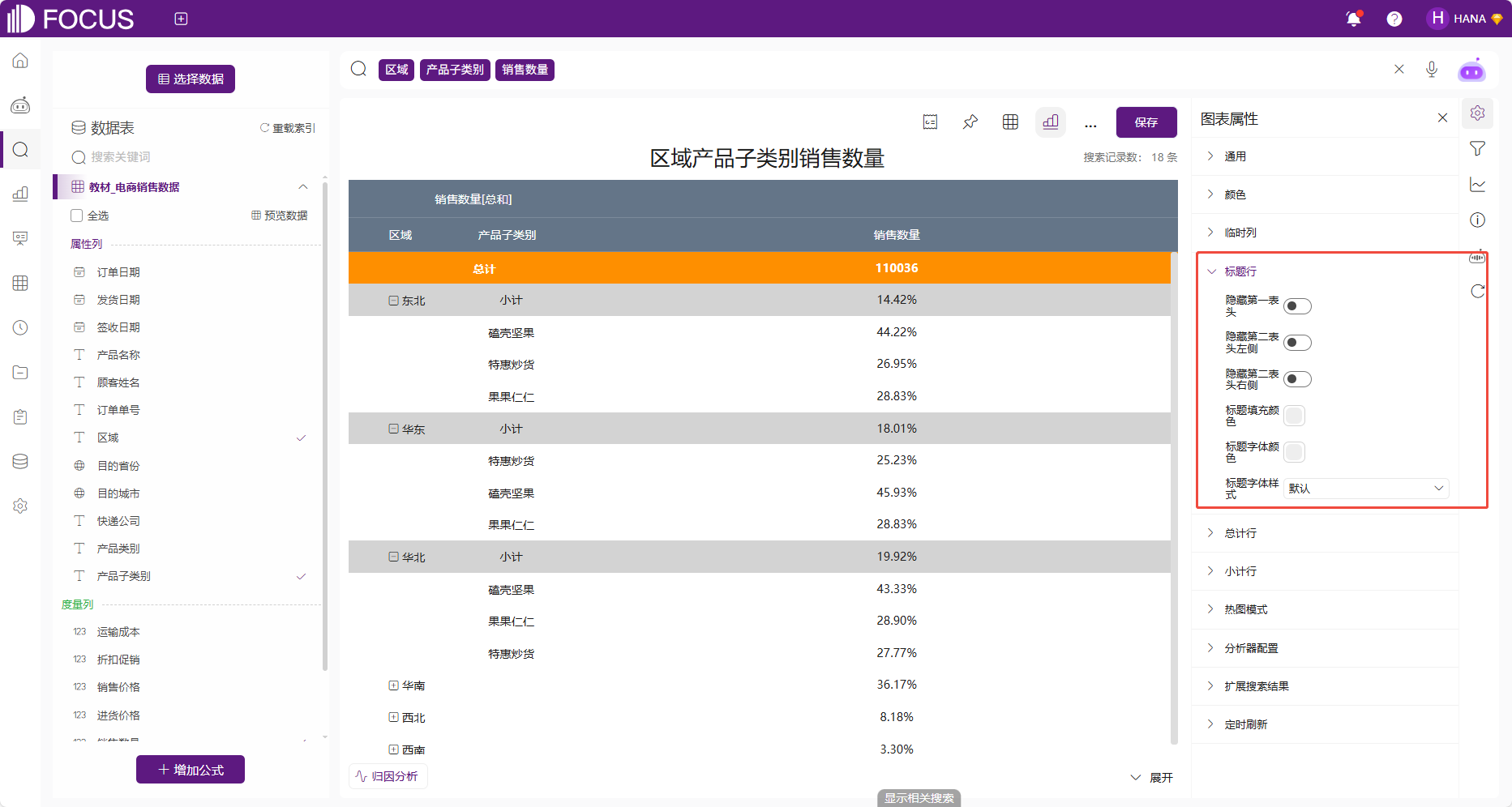
图 2-26标题行
表头
而交叉表有单独的综合表头、顶部表头、左侧表头对表头进行是否隐藏和样式的配置。
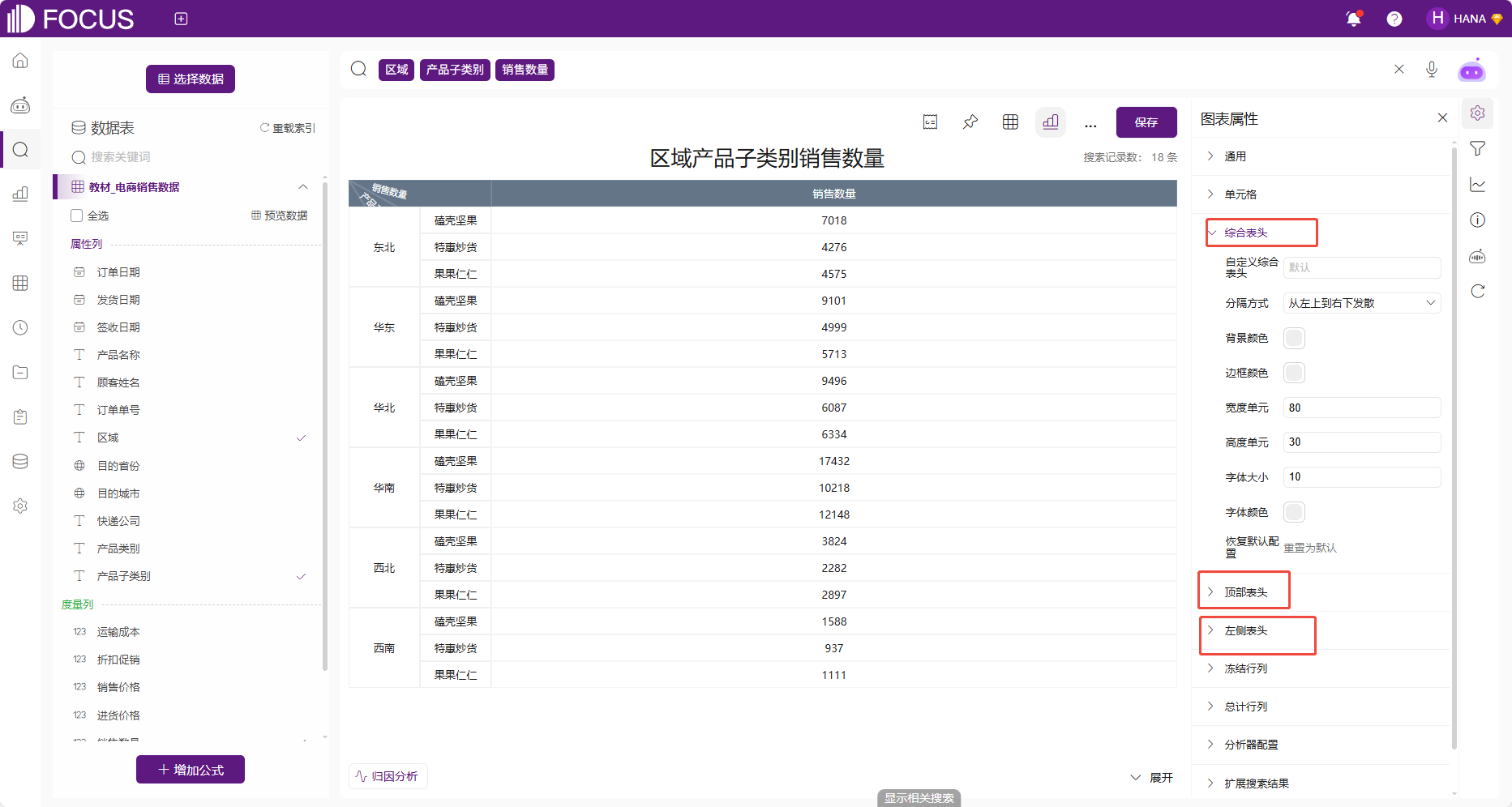
图 2-27表头
临时列
支持自定义临时列,可通过简单的数学运算生成数值列,也可以自定义迷你图形列,增加表格的可视化。例如增加一个临时列,将搜索结果中的销售数量减去折扣促销得到扣减折扣后销售额。
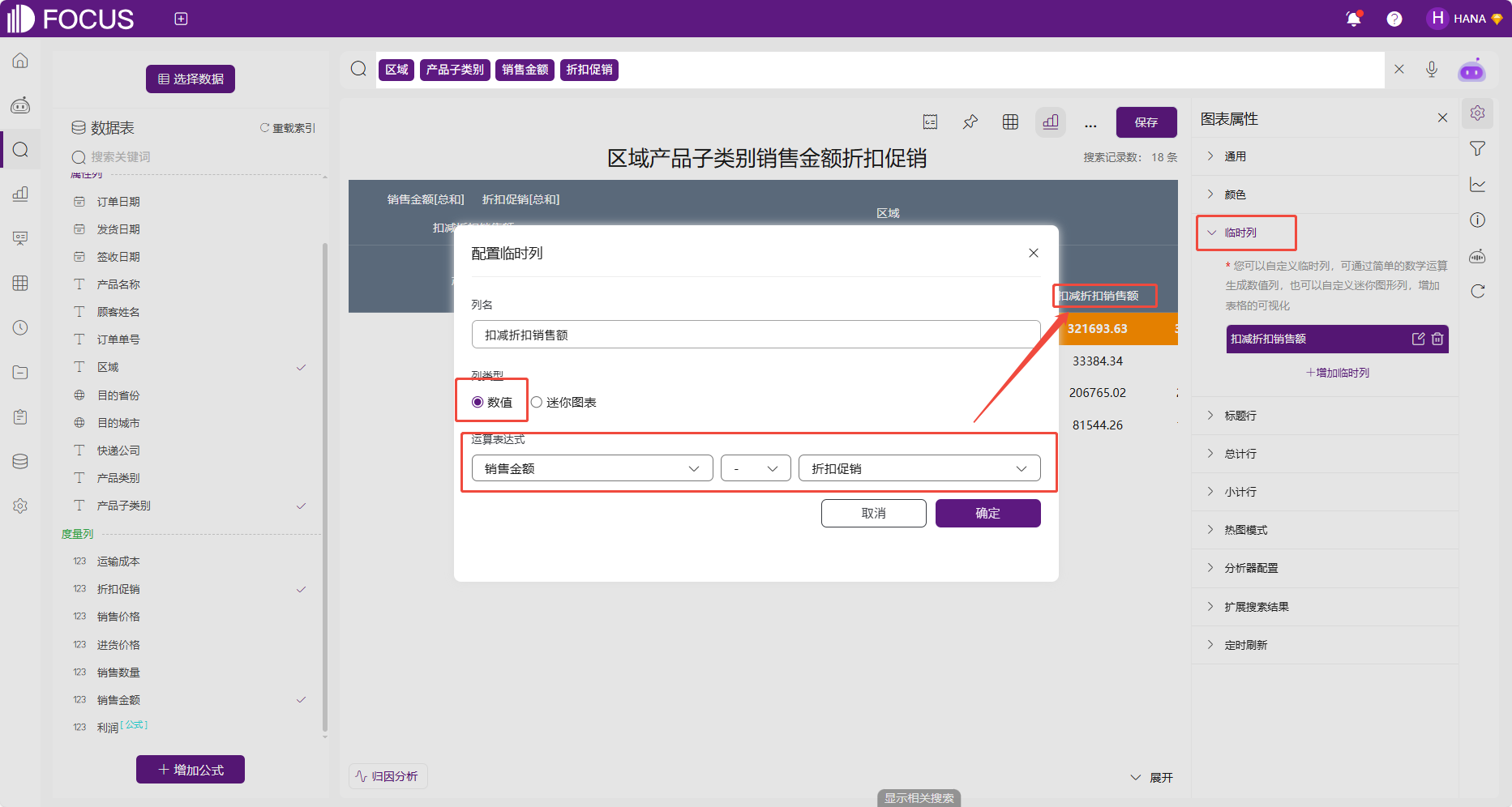
图 2-28临时列
临时列创建成功后,默认在未可视化列中,需要并在图轴配置中将临时列拖入值中即可显示。
切片放大
在数据可视化展示中经常会遇到数据量非常多的情况,横坐标轴经常会只显示部分标签,这时候用户看不到所有的横坐标轴标签值,有可能会错过某些重要信息。在DataFocus中,可以将某块局部区域放大到能够看清所有信息为止,那么如何放大呢?其实很简单,在需要放大的区域按住鼠标左键,然后往左或者往右拖,鼠标松开的那一刻,即可看到这块区域被放大,数据显示得更加清晰,如图2-29和图2-30。
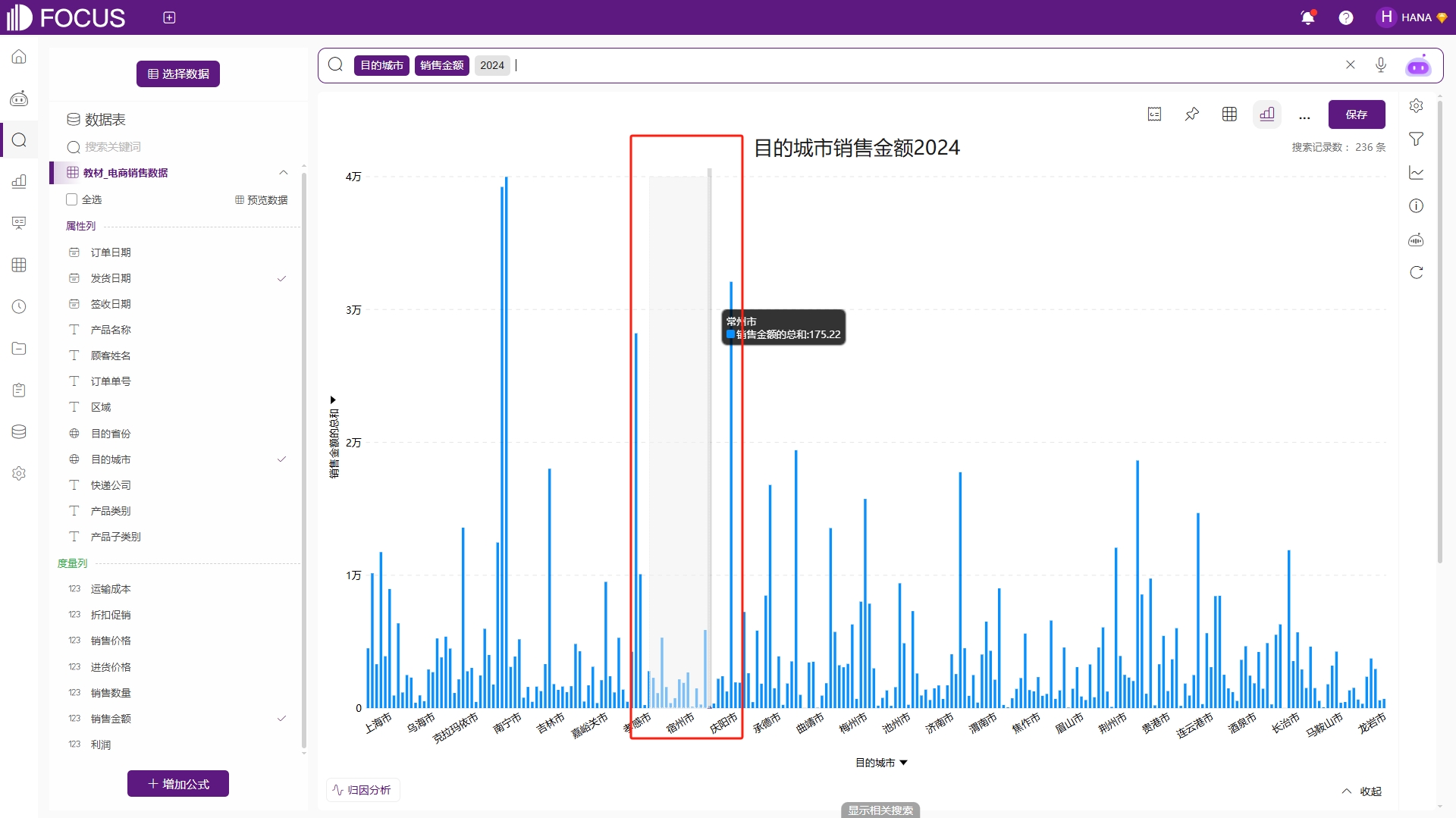
图2-29 数据压缩显示
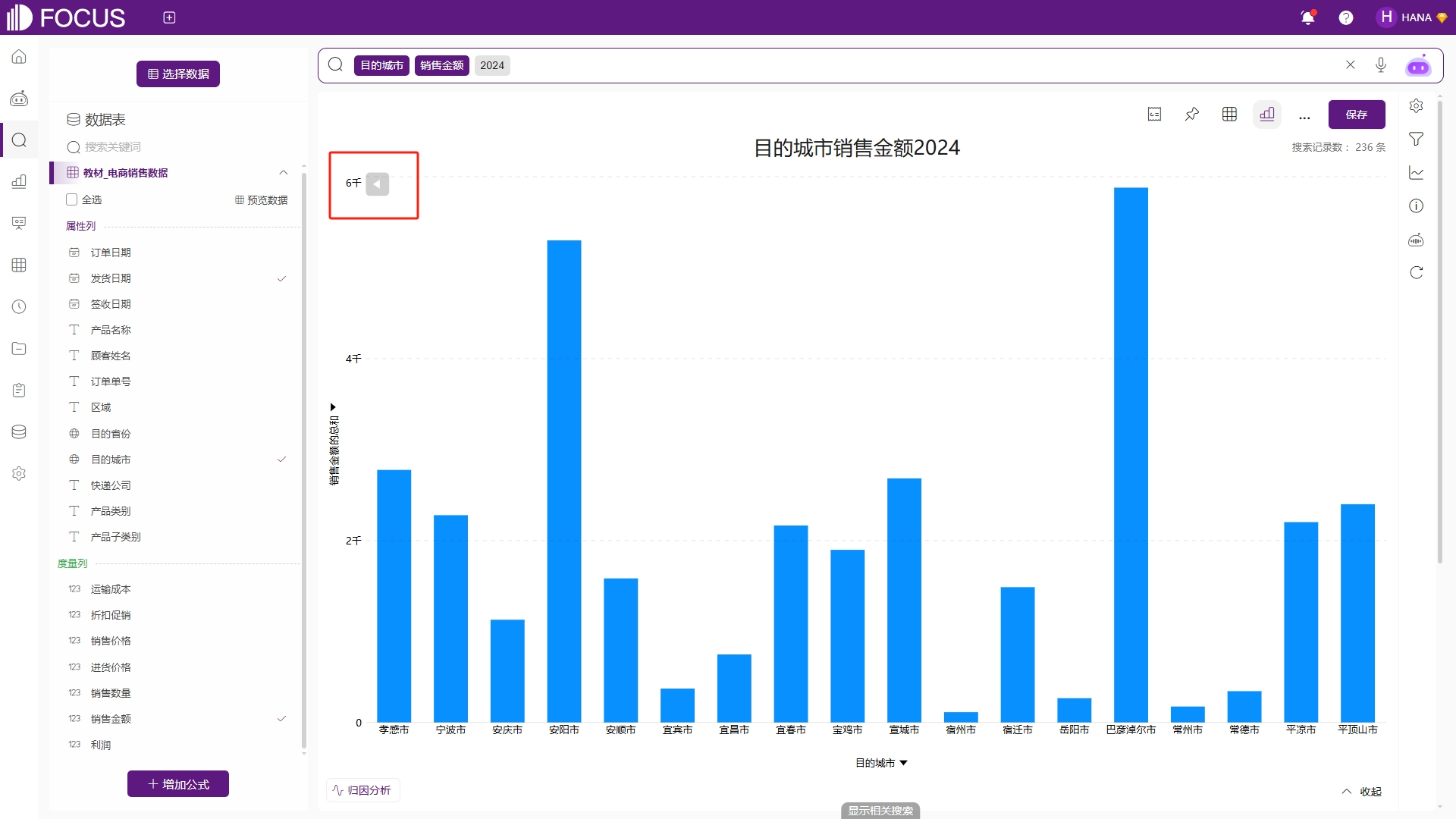
图2-30 放大显示
数据筛选
数据筛选有4种方式:
1. 在输入框用关键词进行筛选,如“销售额大于5000”;
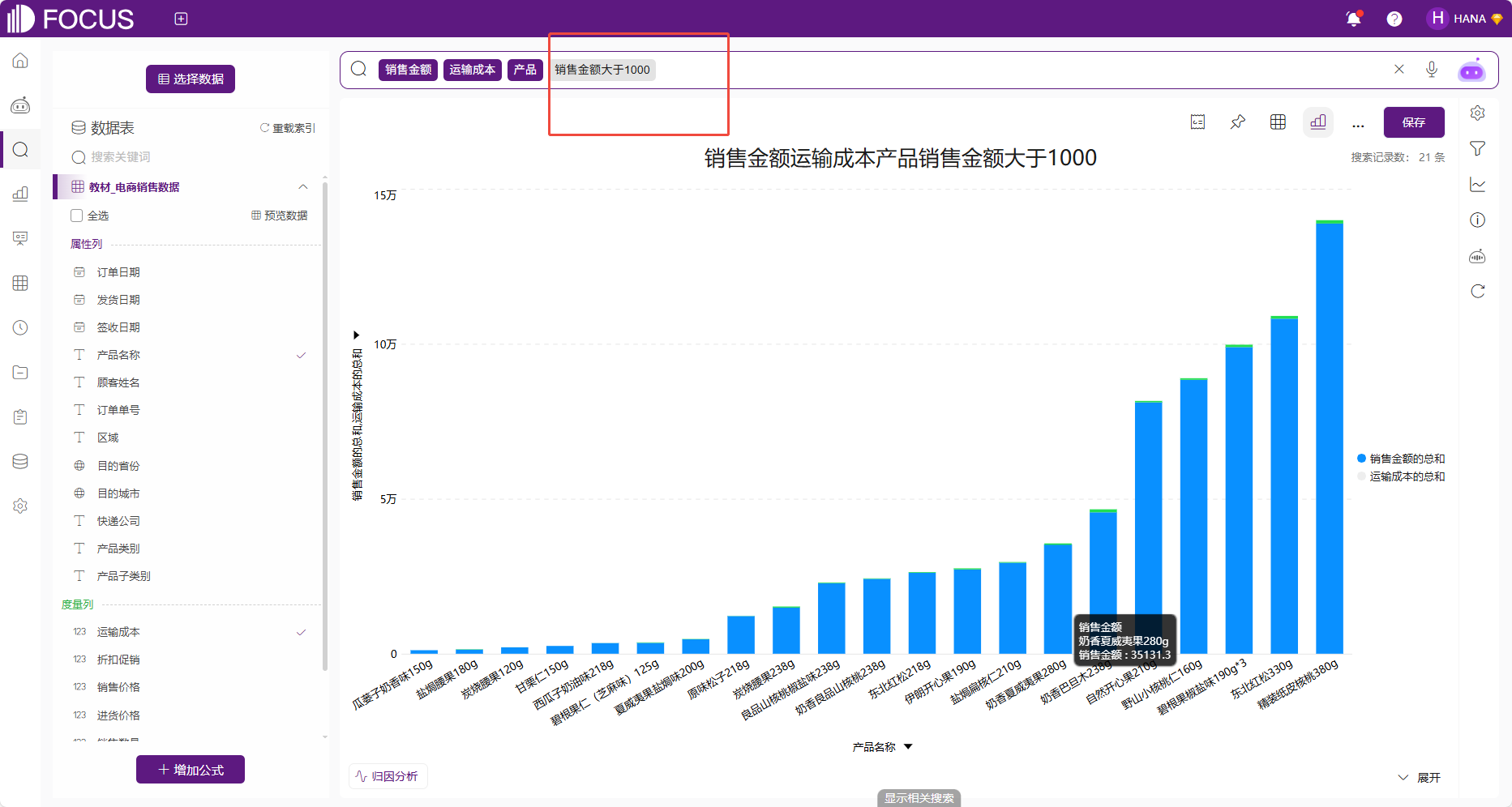
图 2-31关键词筛选
2.在数值表界面进行筛选。点击想要进行筛选的对象,点击后会弹出筛选条件的输入框。
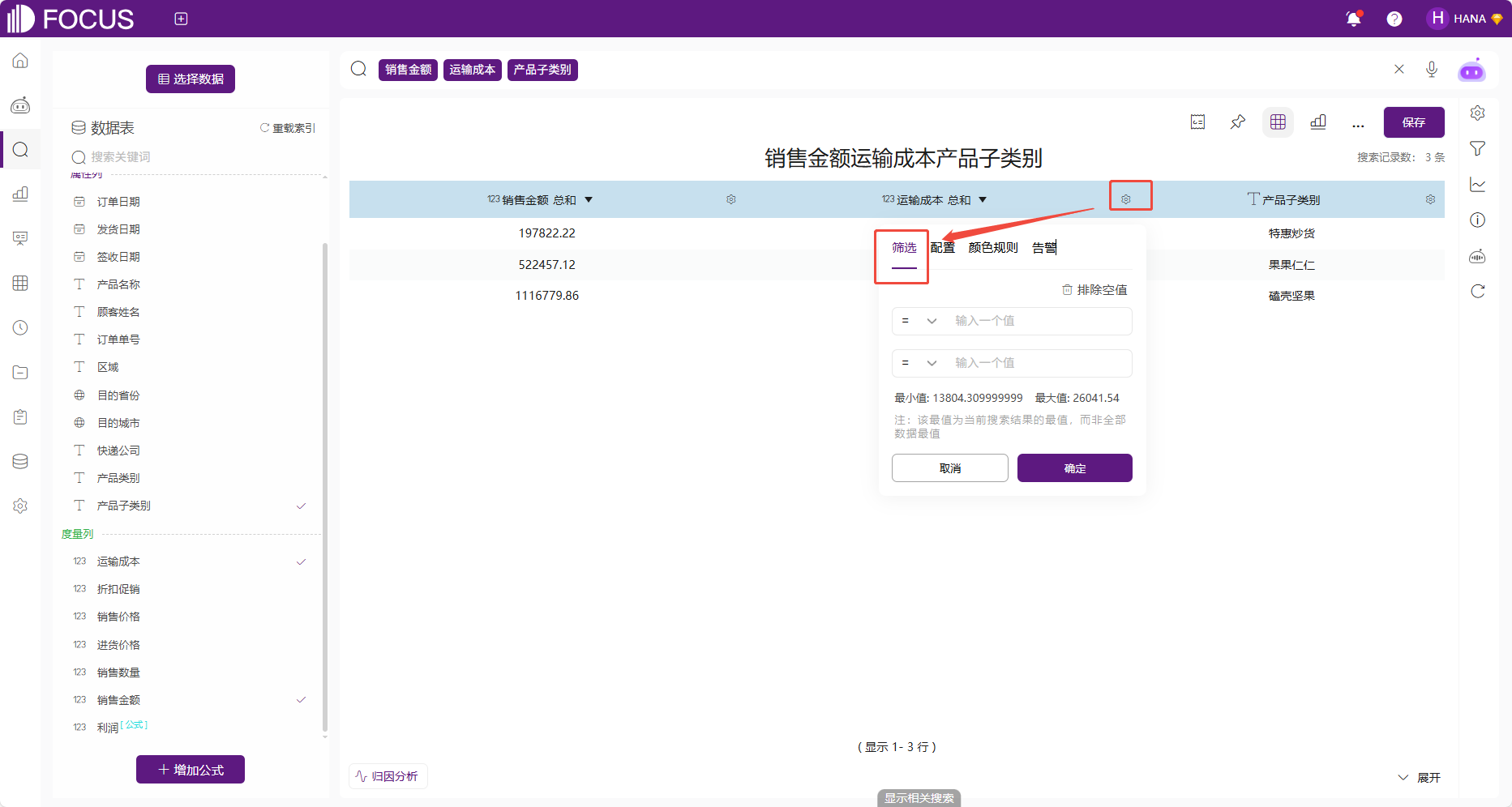
图 2-32数值表筛选
3.在图形界面的坐标轴进行筛选。点击想要进行筛选的对象的坐标轴,点击后会弹出筛选条件的输入框。
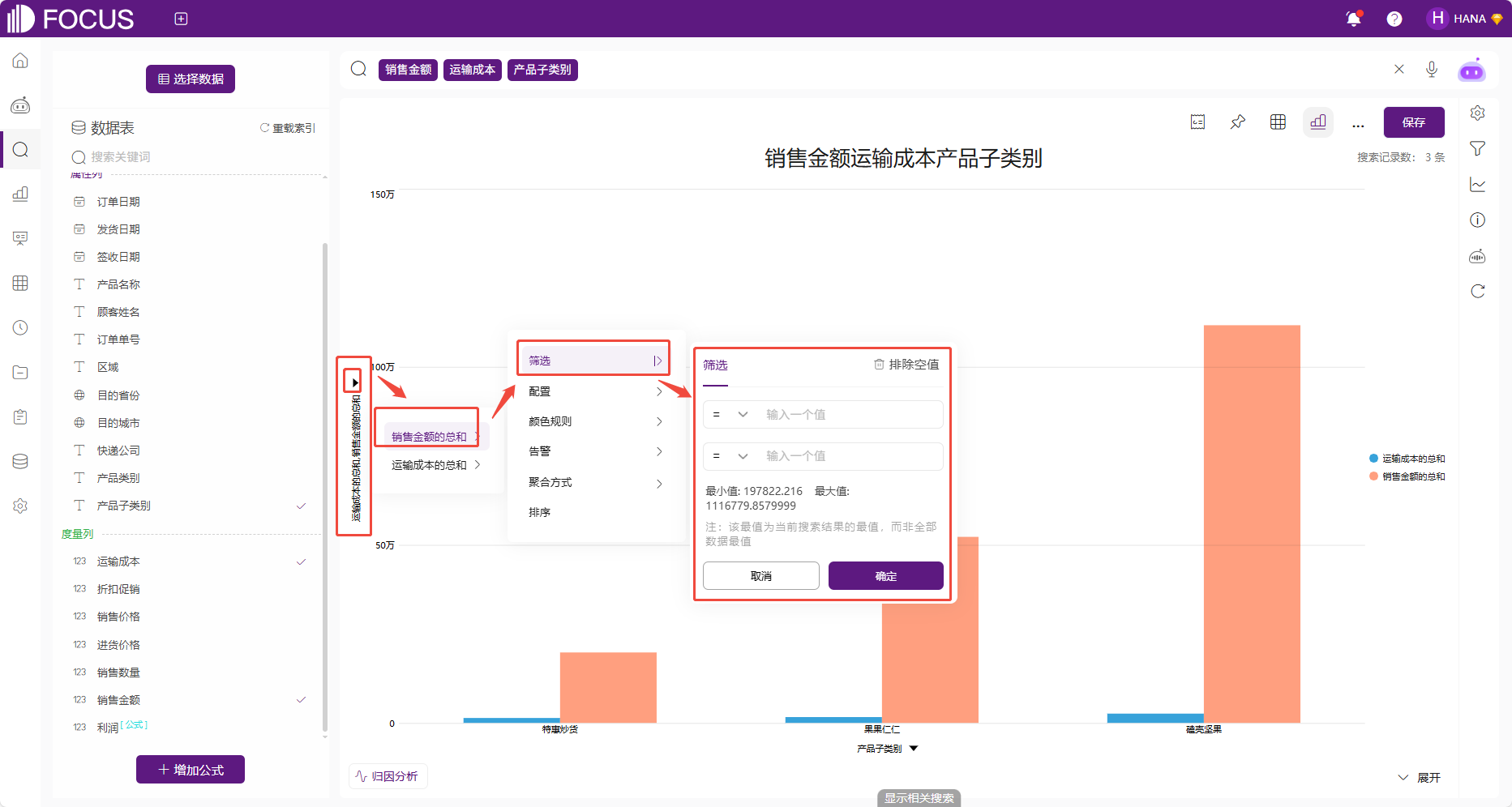
图 2-33坐标轴筛选
4.点击右侧的筛选按钮。点击右侧的筛选按钮,然后点击需要筛选的对象的筛选按钮即可弹出筛选框。
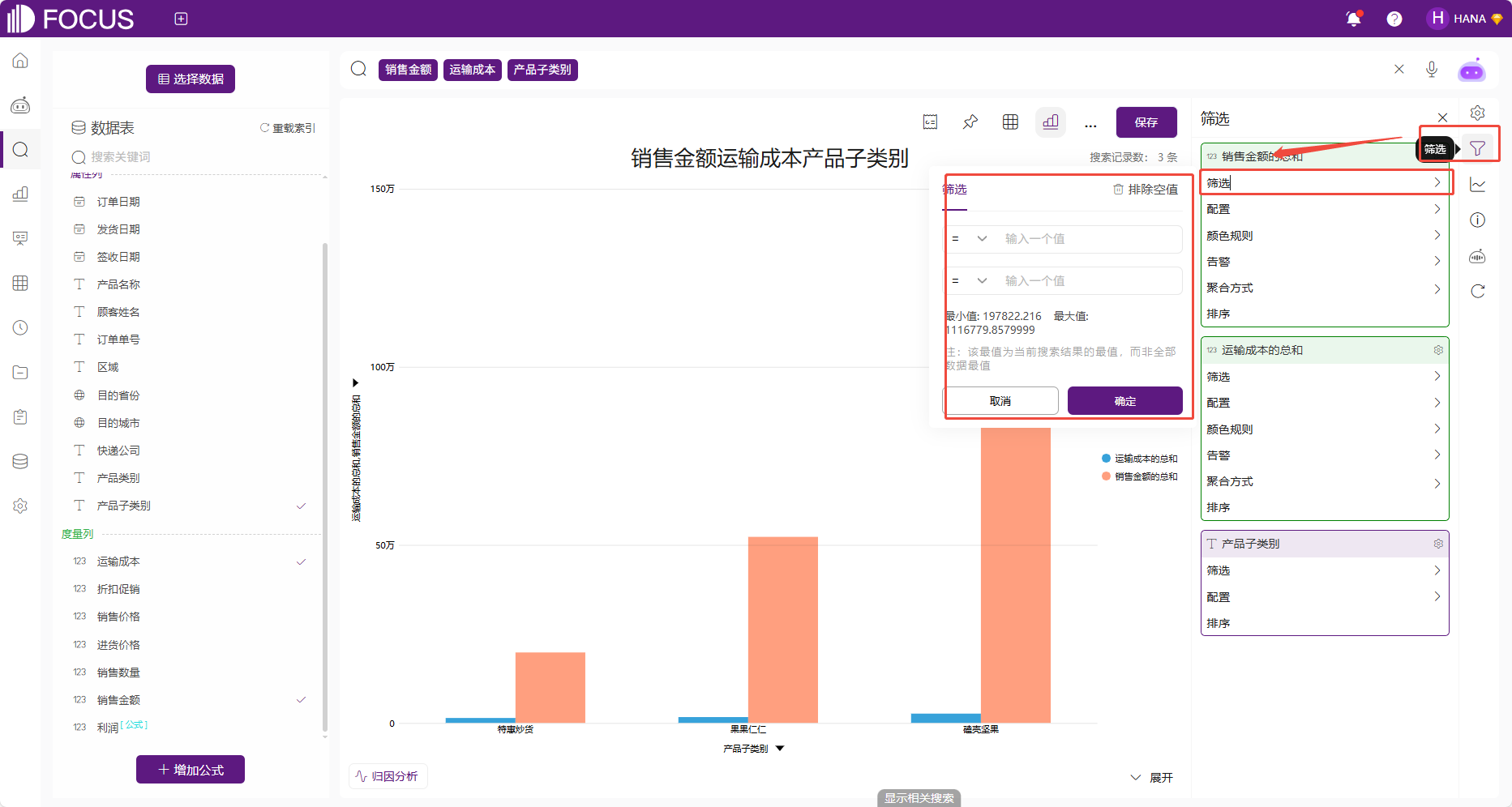
图 2-34筛选按钮
颜色规则
在DataFocus图表中,可以将自定义范围内的值在图表中设置为相同颜色显示。另外,在数值表和数据透视表中,可以将自定义范围内的值或文字设置为按图形形状显示。
配置颜色规则有3种方式,入口和数据筛选的后三种方式入口一致(数值表、坐标轴、筛选按钮),不再赘述。在颜色规则中,可设置自定义值和颜色后,内容可选中文本、形状、文本和形状。点击添加按钮则可添加下一条颜色规则。点击该颜色规则后面的“-”,即可删除该条颜色规则。
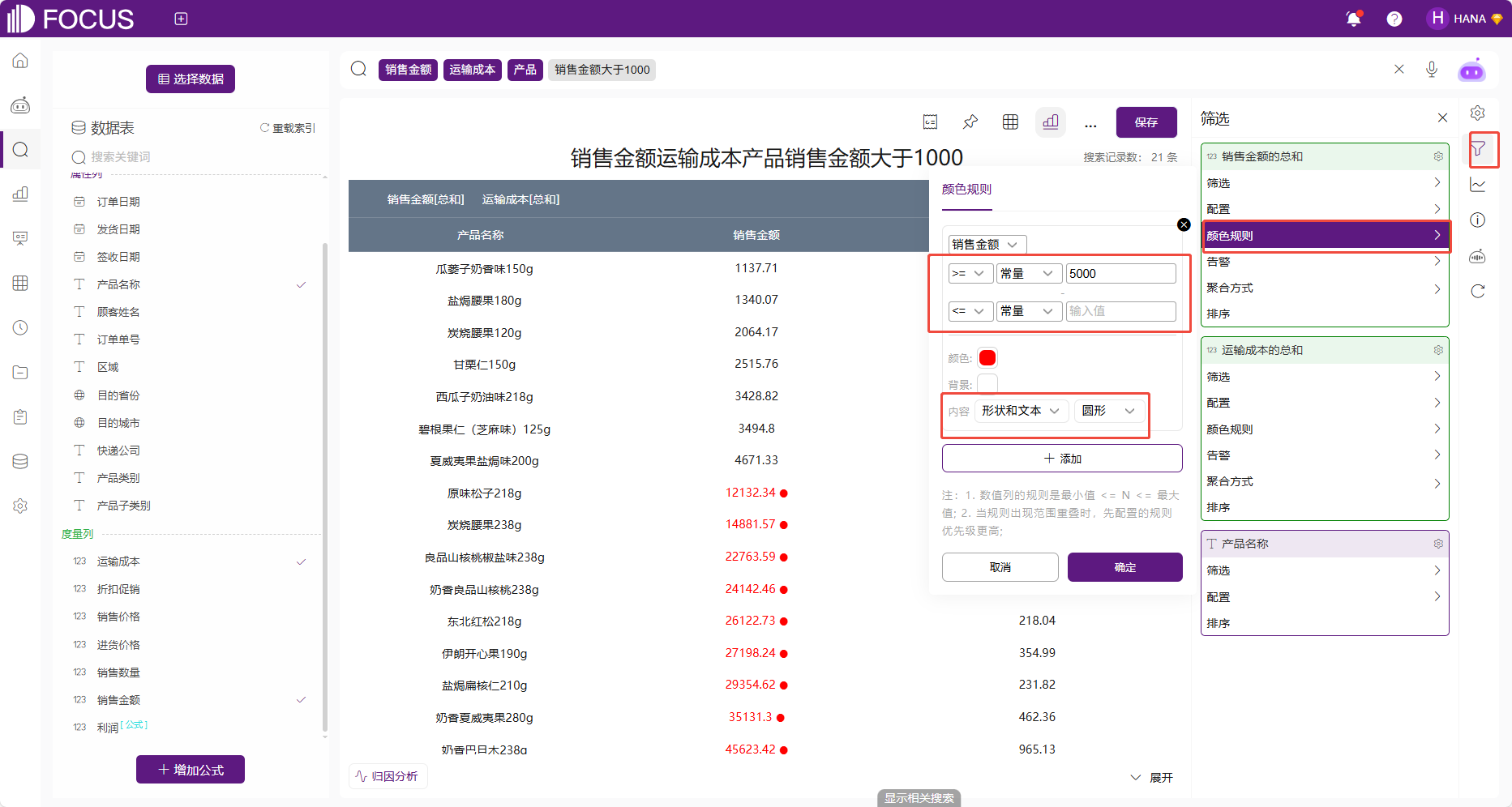
图 2-35颜色规则
配置
配置数据格式有3种方式,入口和数据筛选的后三种方式入口一致(数值表、坐标轴、筛选按钮)。以坐标轴修改配置为例,点击坐标轴,选择“配置”,在跳出的配置页面可以对当前轴的显示名进行特殊设置。当前轴为数值列时,可以对当前轴进行目标值的配置,令当前轴等于某一个数值的直线显示为橘色。除此之外,还可以设置数值数据格式,包括数字(可继续设置数量单位和保留小数位);货币(可继续设置货币类型、数量单位和保留小数位);百分比(可继续设置保留小数位);财务(可继续设置数量单位和保留小数位)。
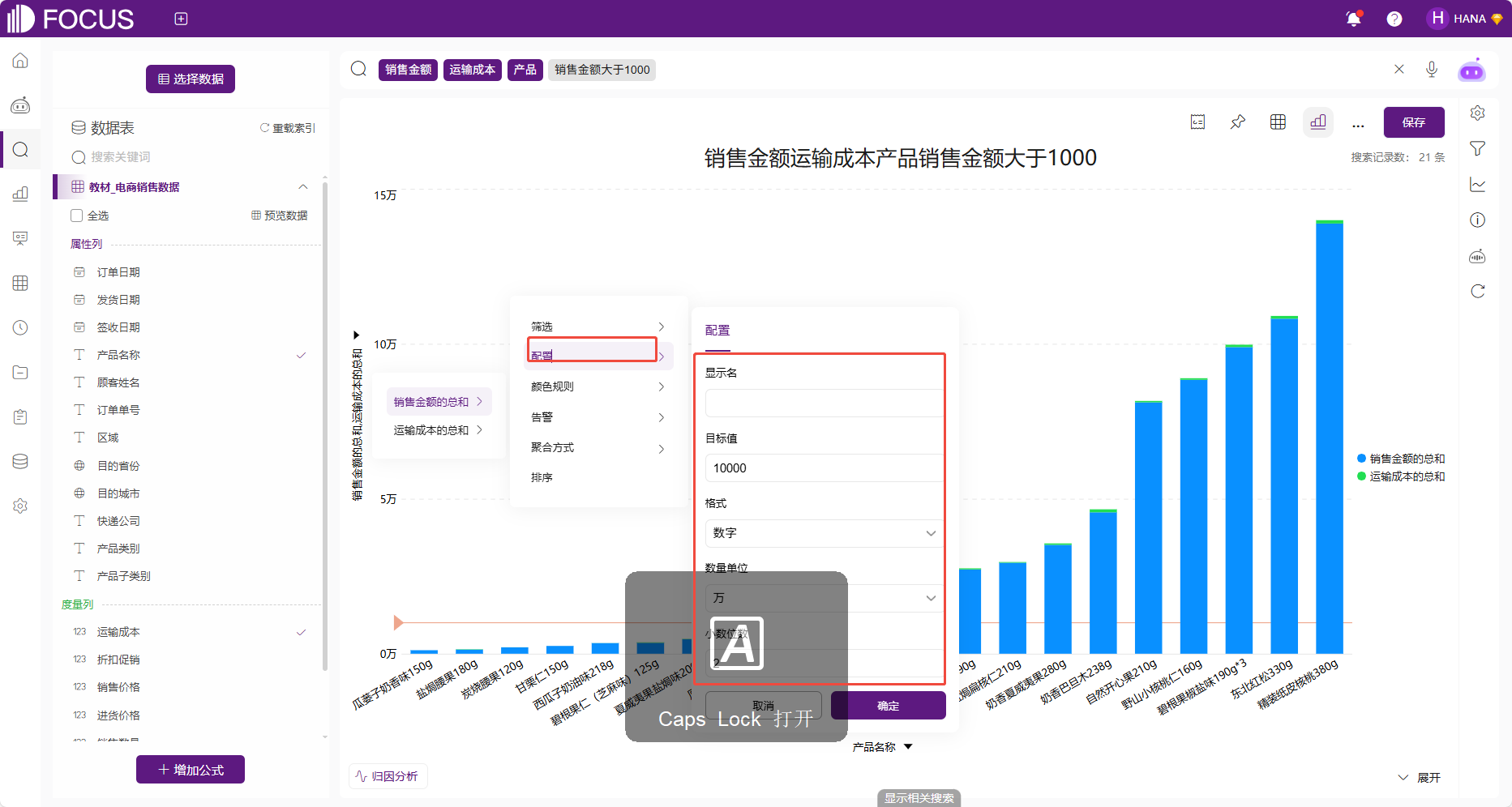
图 2-36配置
同时还可以设置日期列的格式:根据不同的日期格式对日期列的显示格式进行修改。
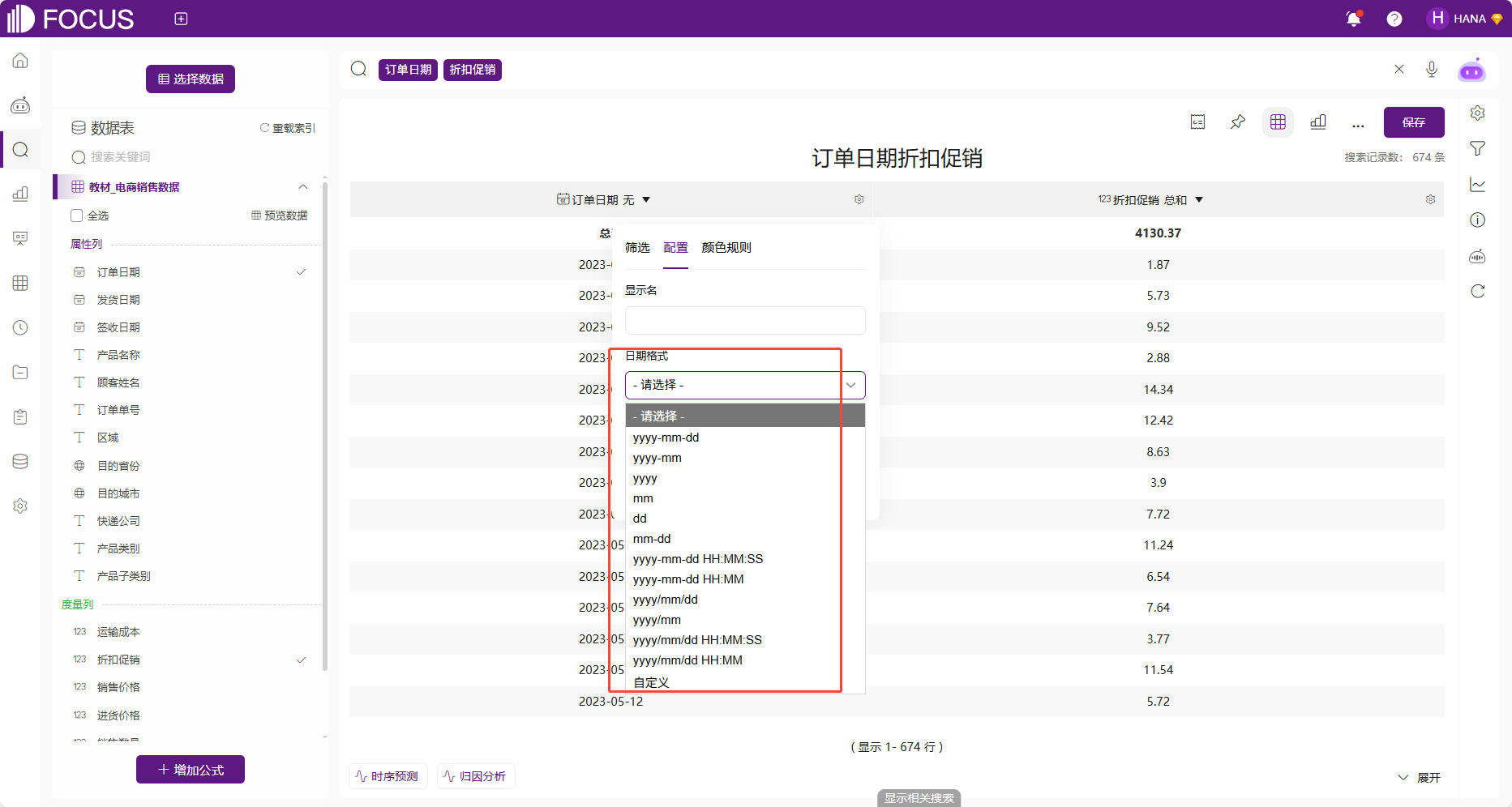
图 2-37日期格式
另外,数值表中,数值列的格式配置可以对总计行中显示的计算值进行设置。
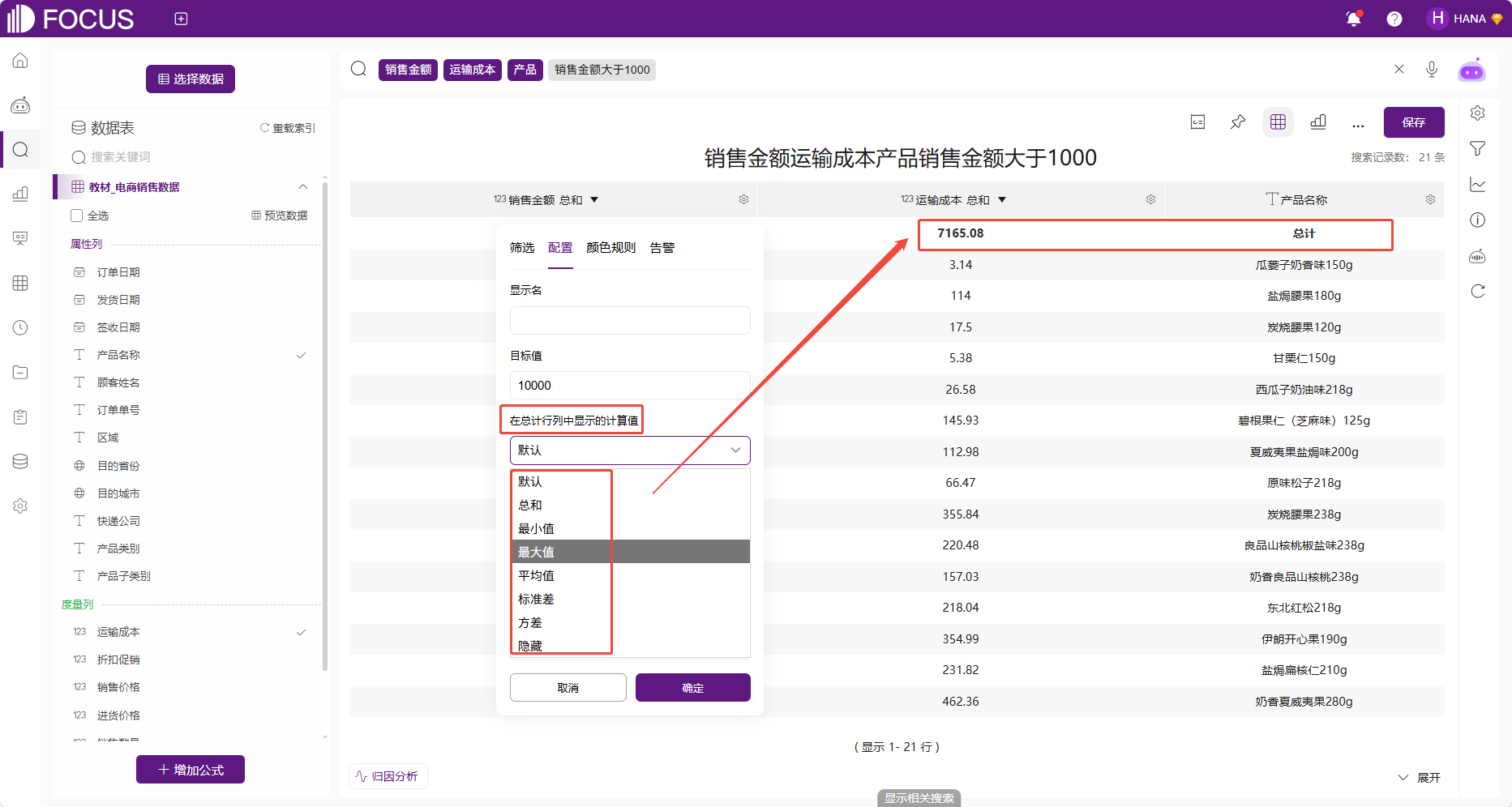
图 2-38总计行显示的计算值
归因分析
在DataFocus中,在搜索模块根据返回数据用户可进行归因分析,归因分析目前支持贡献度归因和夏普利归因。在搜索时,用户可以通过三种方式来触发归因,以便深入洞察数据背后的影响机制。接下来详细介绍这三种触发方式,帮助用户更好地利用这一功能来优化决策过程。
自动归因分析
自动归因指的是,如果查询结果包含符合有效日期区间数据则会触发贡献度归因。包括:年月(2024年7月)、年(2024年)、具体日期区间(2024-07-01至2024-08-01、2024年7月1日至2024年8月1日)。
举例如下,数据源选择《电商数据》,搜索“2024年7月1日至2024年7月15日销售金额”,符合自动归因条件,因此下拉滚动条在画图区域下面自动呈现了关于2024年7月1日至2024年7月15日销售金额的贡献度归因分析结果。
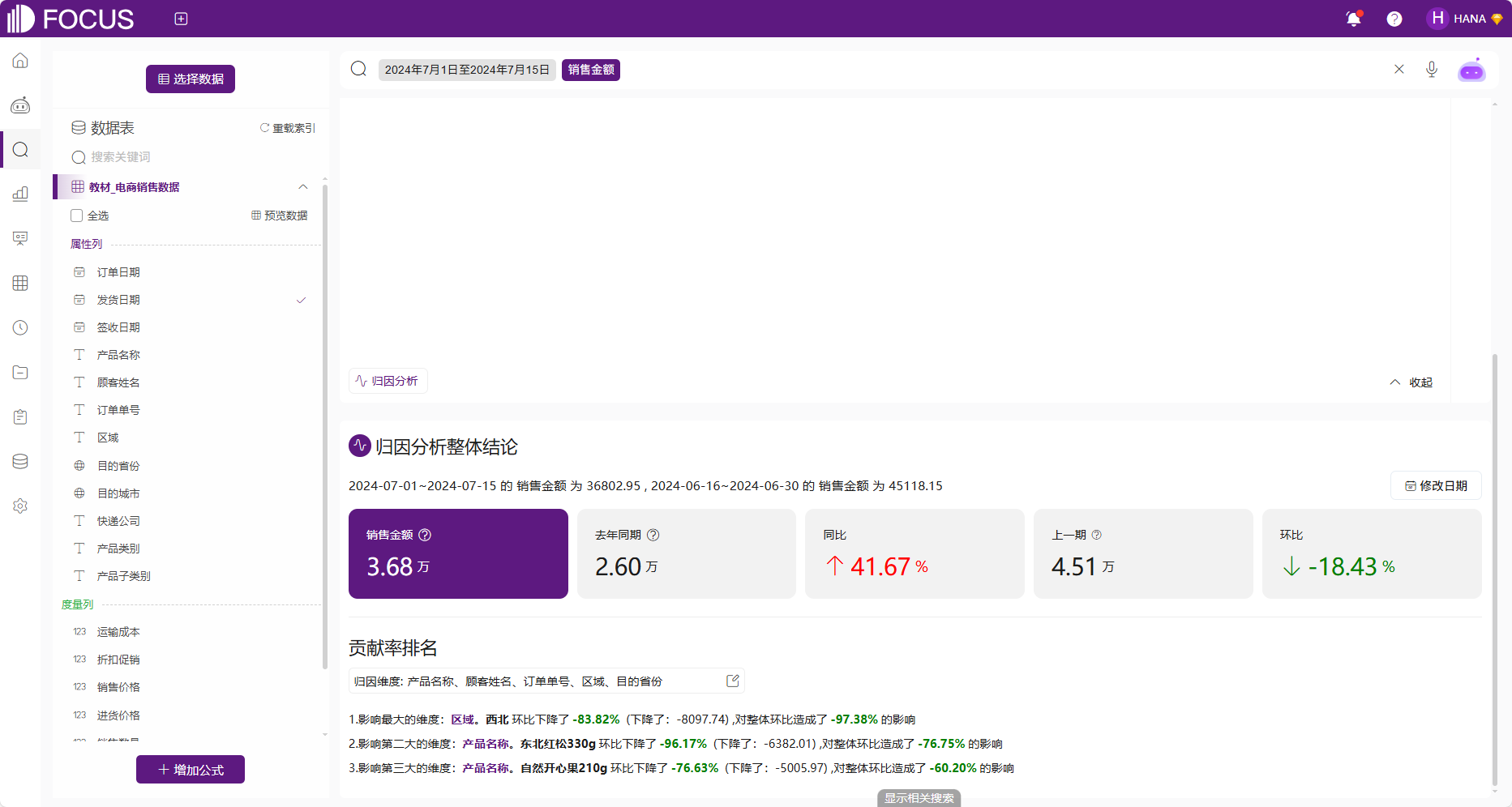
图 2-39自动归因分析
点击修改日期或者归因维度的编辑按钮,可查看当前的归因配置。自动贡献度归因日期为查询条件的日期区间,归因指标为查询结果的某一个数值列,而归因维度默认选取数据源前5个数据类型为字符串的列。
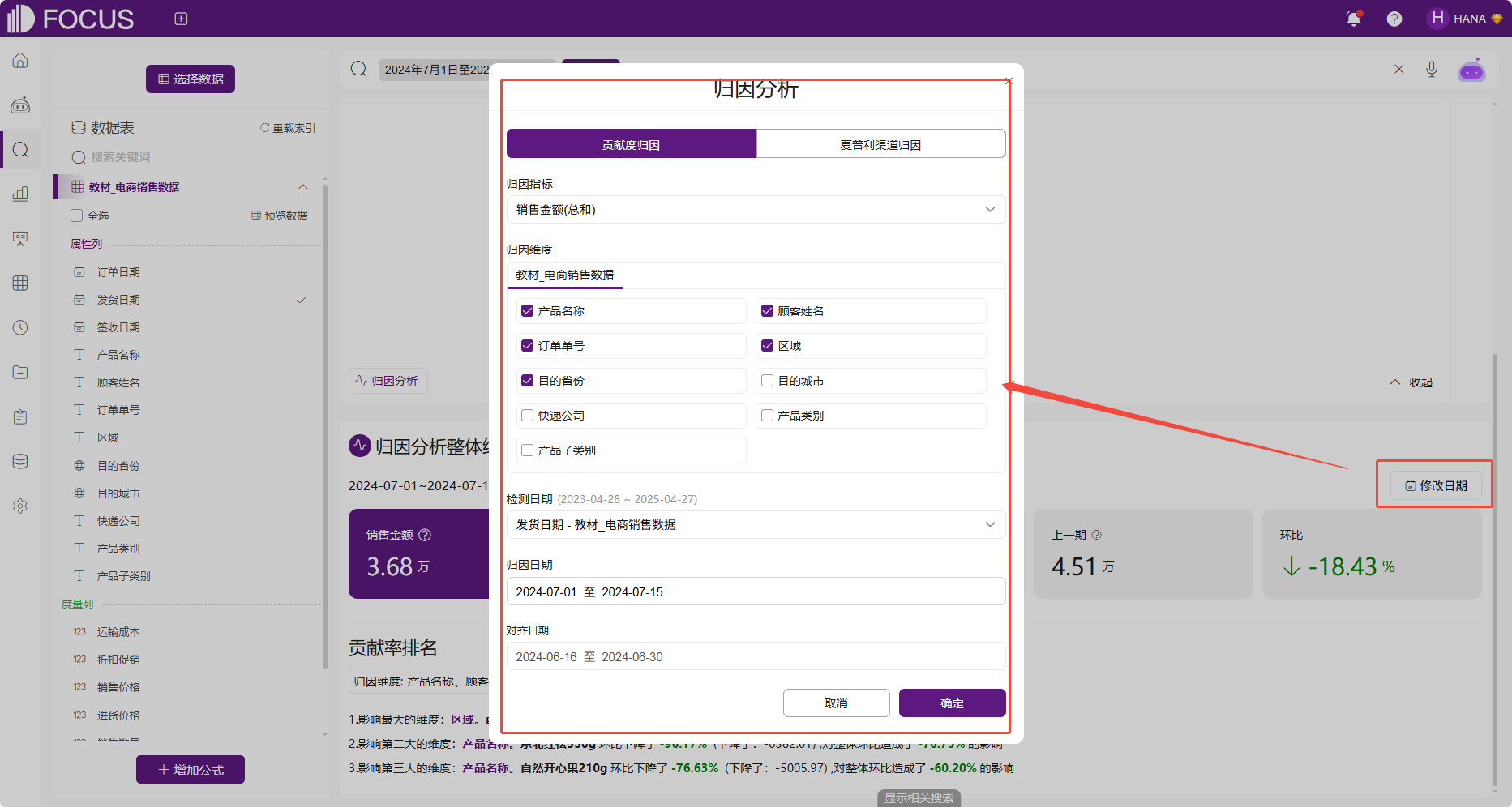
图 2-40自动归因默认配置
右键快速归因
归因还可以通过手动触发。第一种方式是在返回的结果图表中直接右键快速归因,此方法默认使用贡献度归因。例如输入“销售数量 每月”,此时鼠标右键点击堆积柱状图上特惠炒货的某一点,然后点击“归因分析”按钮,如图2-41。
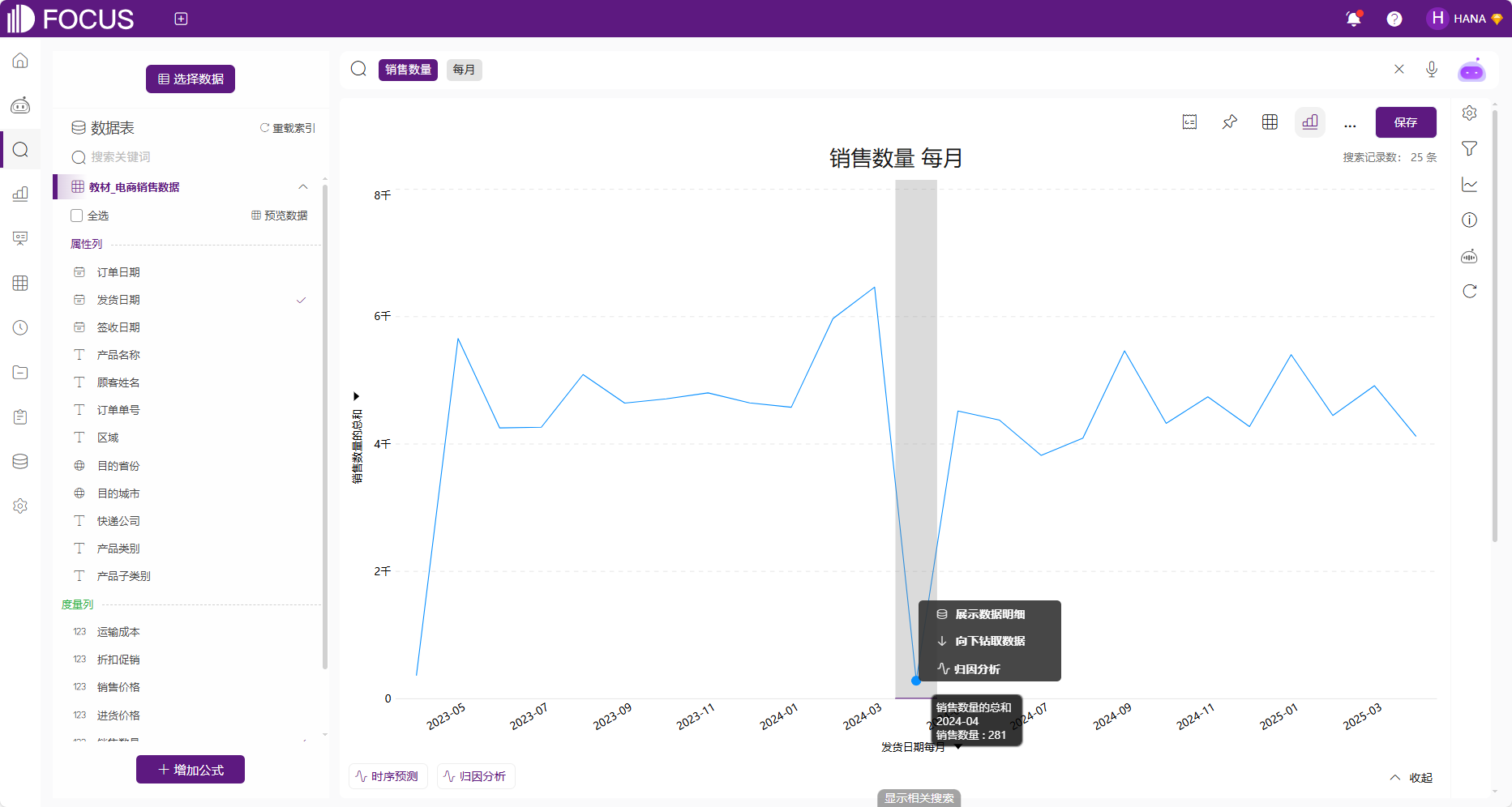
图2-41 右键归因
若系统能识别归因的日期范围无需手动配置归因参数即可完成贡献度归因,识别条件与自动贡献度归因分析相同。区别于自动归因,右键快速归因可以通过右键选中列中值直接将其作为筛选条件到贡献度归因分析中,如图2-42。
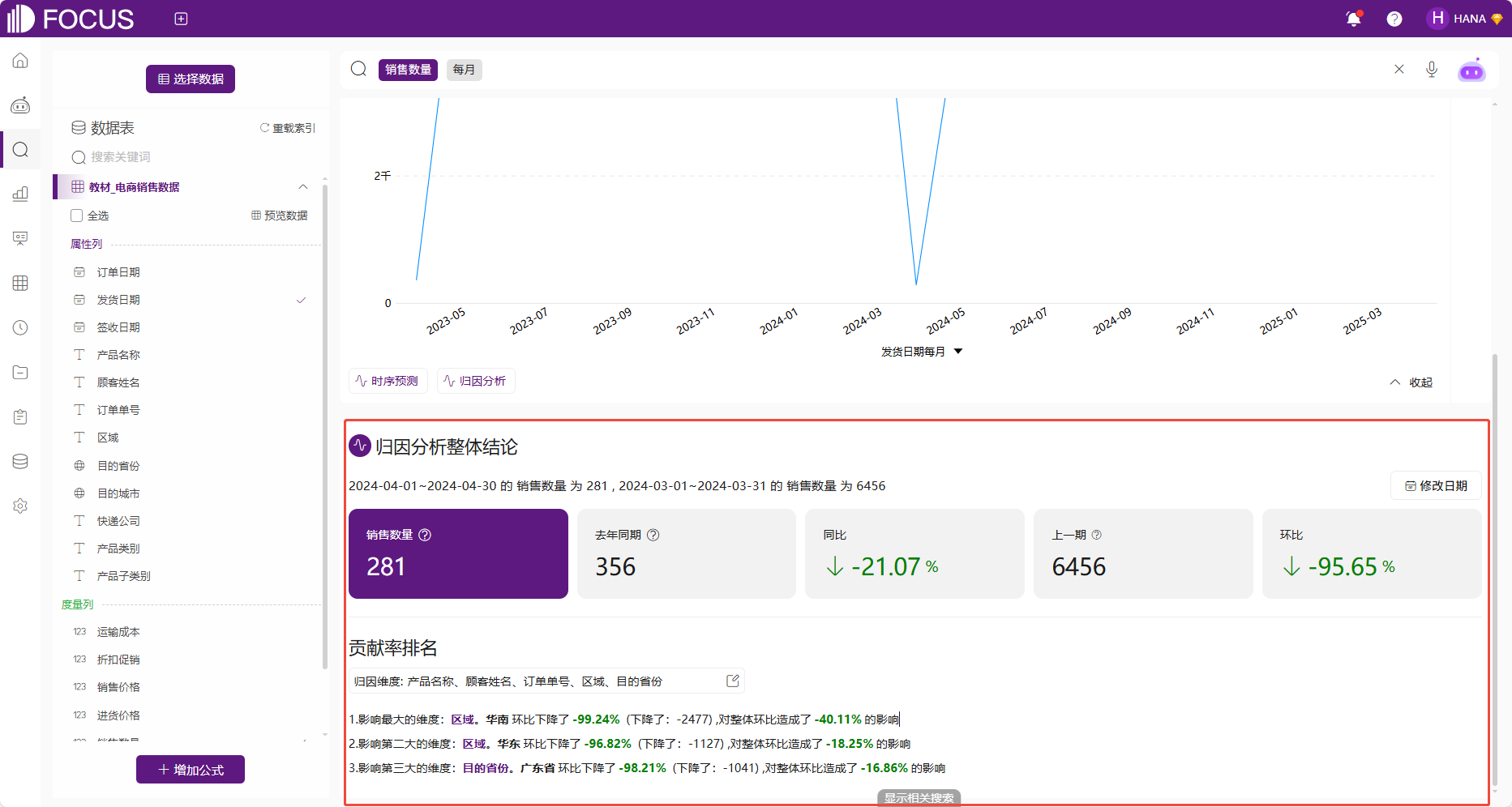
图2-42 快速归因结果
若不满足归因分析条件,此时系统会弹出“对不起 ,当前指标指定归因日期区间没有归因分析结果”。
手动配置归因分析
第二种方式是点击图表左下角的“归因分析”按钮,即通过纯手动配置归因分析参数触发归因分析,如图2-43。
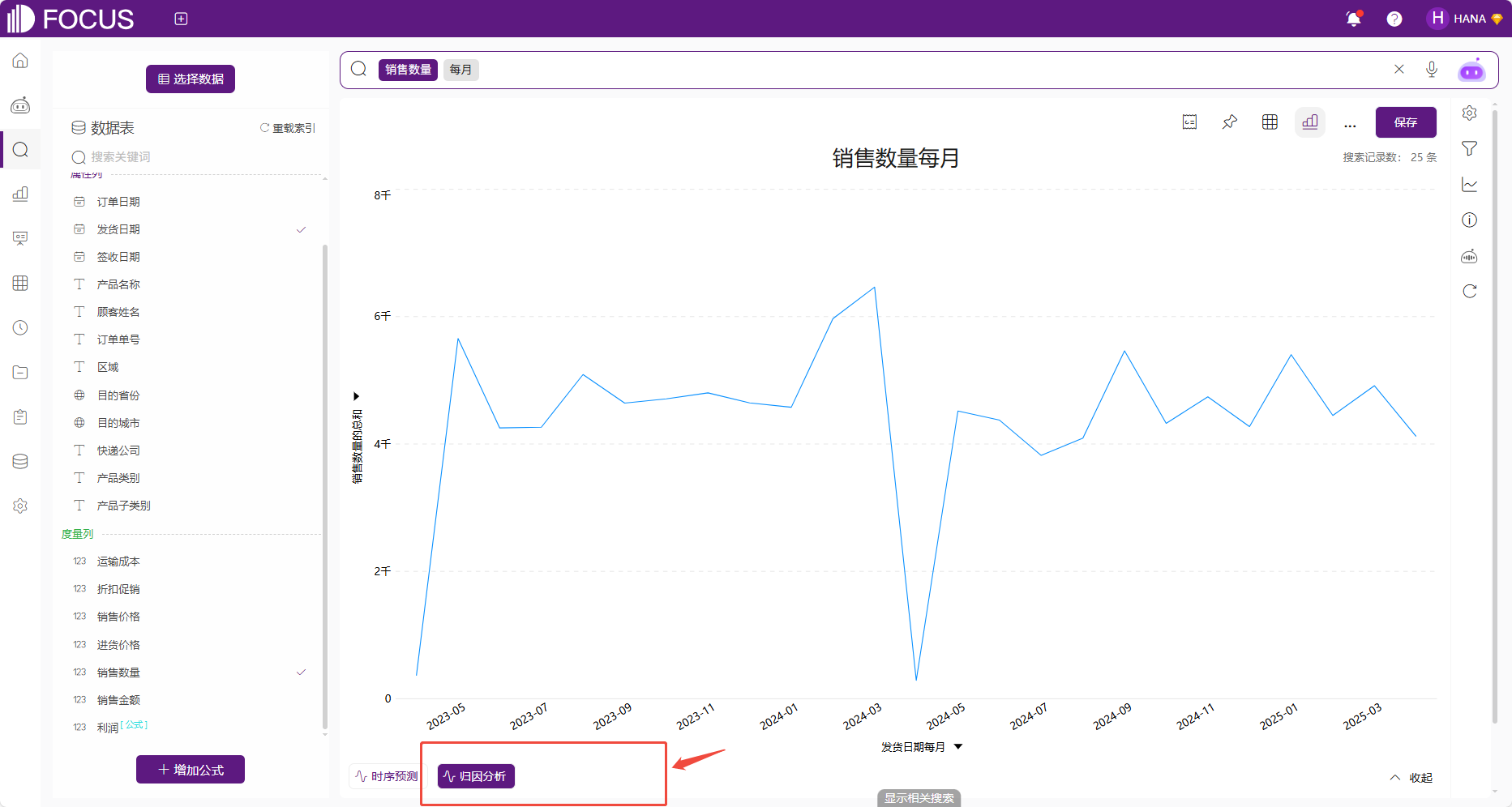
图2-43 手动归因
贡献度归因
贡献度归因运用的是Delta法,它是一种用于计算增量贡献率的方法,其核心原理在于通过对比两个不同时间区间的数据变化来量化各个维度对总体变化的贡献程度。具体来说,它关注于每个因素或维度在特定时间段内或特定条件下发生的变动,并量化这些变动对整体结果的影响。
最终,Delta法通过比较各因素或变量的变化量对总体指标变化量的贡献,来评估它们的相对重要性。这种方法广泛应用于数据分析和商业智能中,特别是在需要理解不同因素对整体业务绩效变化影响的情况下。这种评估有助于我们识别出对总体指标变化影响最大的因素或变量,从而为决策制定提供有力支持。

图 2-44贡献度归因公式
该公式表明,在同一维度下,所有子项的贡献率相加应该等于100%。这意味着,如果你有一个维度(比如产品类别),并且在这个维度中有多个子项(比如A类商品、B类商品等),那么这些子项各自的贡献率相加的结果应该是100%。
这个公式适用于分析某个指标(如销售额、用户数等)在不同维度上的分布情况,帮助我们了解哪些维度对整体变化产生了更大的影响。例如,你可以使用这个公式来分析不同地区、不同产品的销售贡献率,以便更好地理解业务的增长来源。
以下是系统中贡献度归因的配置参数:
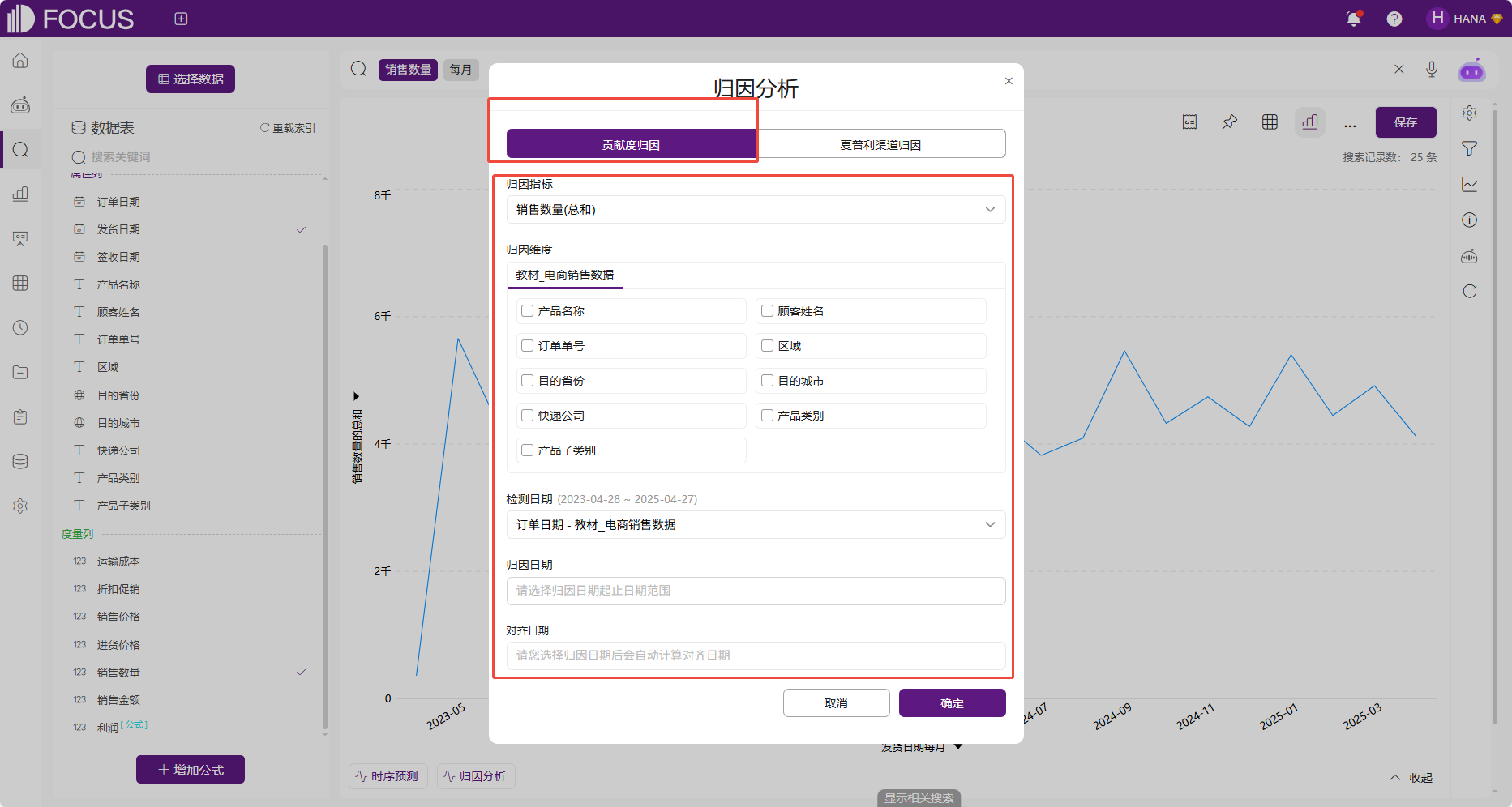
图 2-45贡献度归因参数
归因指标:可选择查询结果中的度量列。
归因维度:可选择数据源中的数据类型为字符串的列。最多可选5个。
归因日期:日期区间选择。若归因日期选择了无环比日期和同比日期将无法完成分析。
对齐日期:非选择项,根据归因日期自动计算。
除此之外,这里有几个关键点需要注意:
(1)归因分析的来源数据会受筛选条件影响;
(2)归因指标及归因维度不包含公式列;
(3)维度中只有归因日期有数据而对齐日期缺失,和只有对齐日期有数据而归因日期缺失,会当作无效值处理;
(4)日期区间内无有效的对比差值数据,将报错“指标指定归因日期区间没有归因分析结果”。
例如我们配置贡献度归因的指标为“销售数量”,维度选择“产品子类别”和“快递公司”,归因日期为“2024-09-01至2024-09-30”,如图2-46。
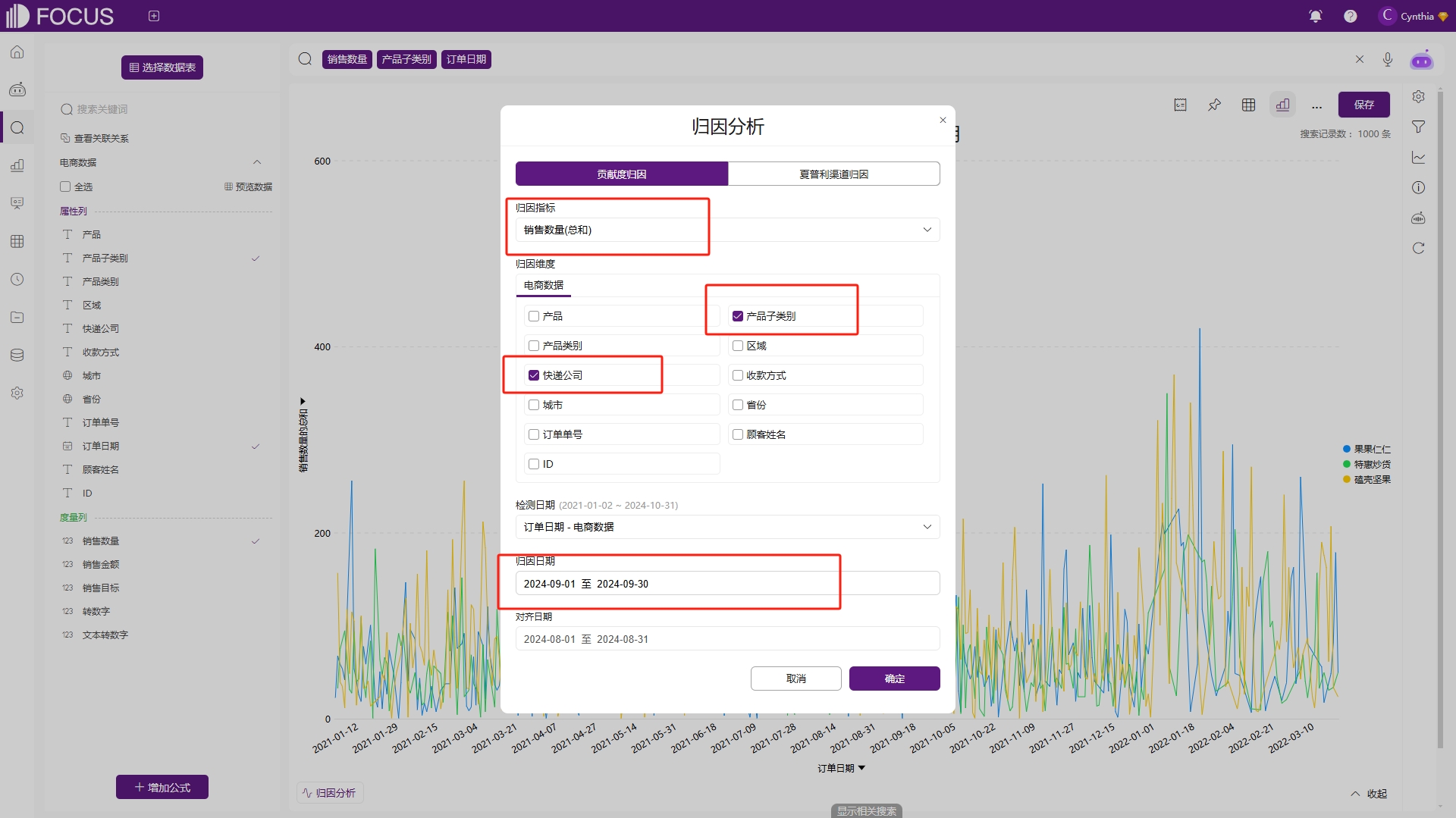
图2-46 贡献度归因配置示例
此时可得到归因结果,如错误!未定义书签。,2024-09-01至2024-09-30的销售数量4529,2024-08-01至2024-08-31的销售数量为4880,以及同环比情况。
影响最大的维度是快递公司。顺丰环比下降了-29.67%(下降了:-674),对整体环比造成了-192.02%的影响;影响第二大的维度是快递公司。韵达环比下降了-65.30%(下降了:-271),对整体环比造成了-77.21%的影响;影响第三大的维度是产品子类别。果果仁仁环比下降了-13.69%(下降了:-196),对整体环比造成了-55.84%的影响。
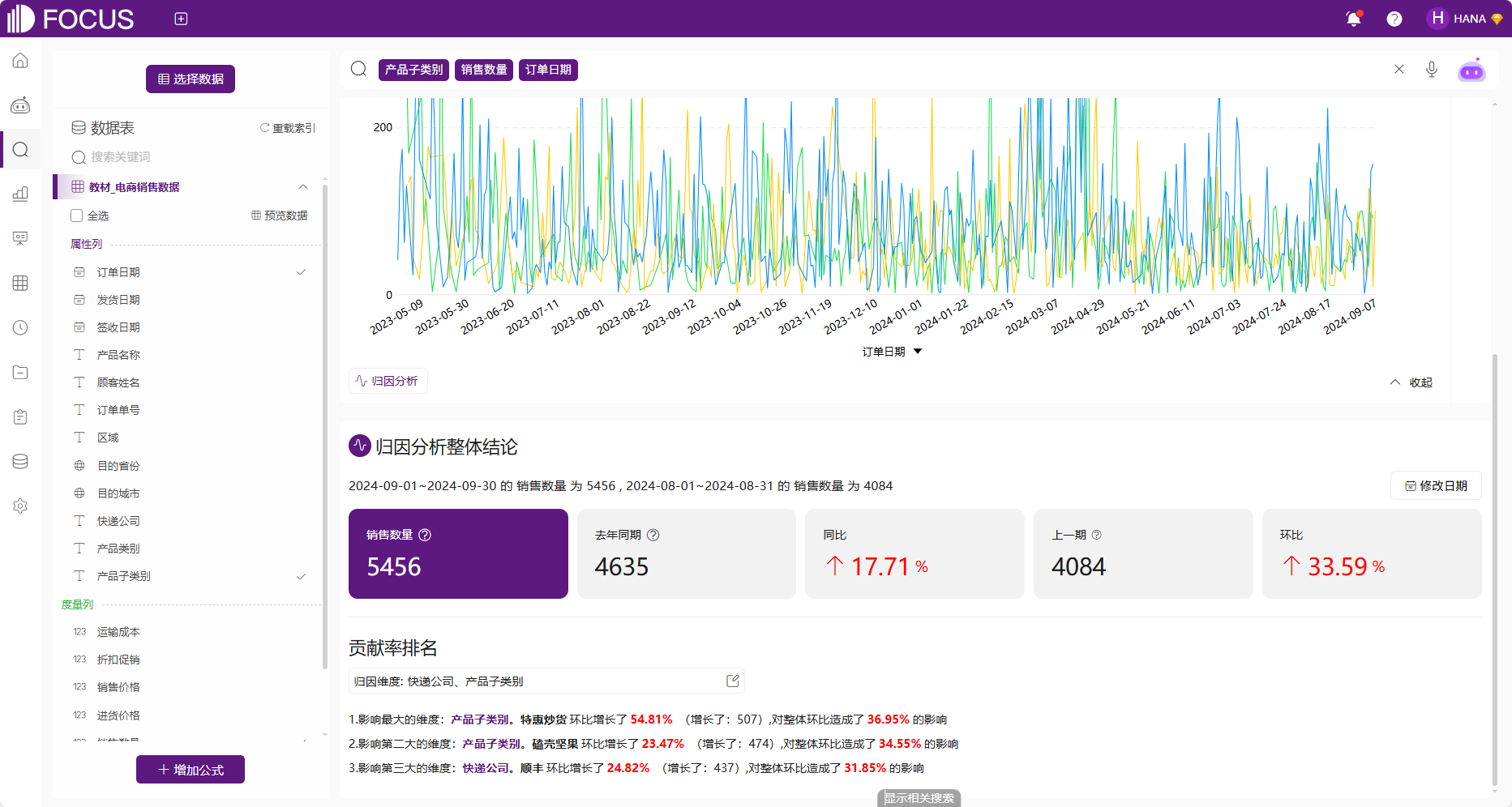
图 2-47贡献度归因分析
若想修改参数配置,同样是点击修改日期按钮或者点击归因维度的编辑按钮,如错误!未定义书签。。
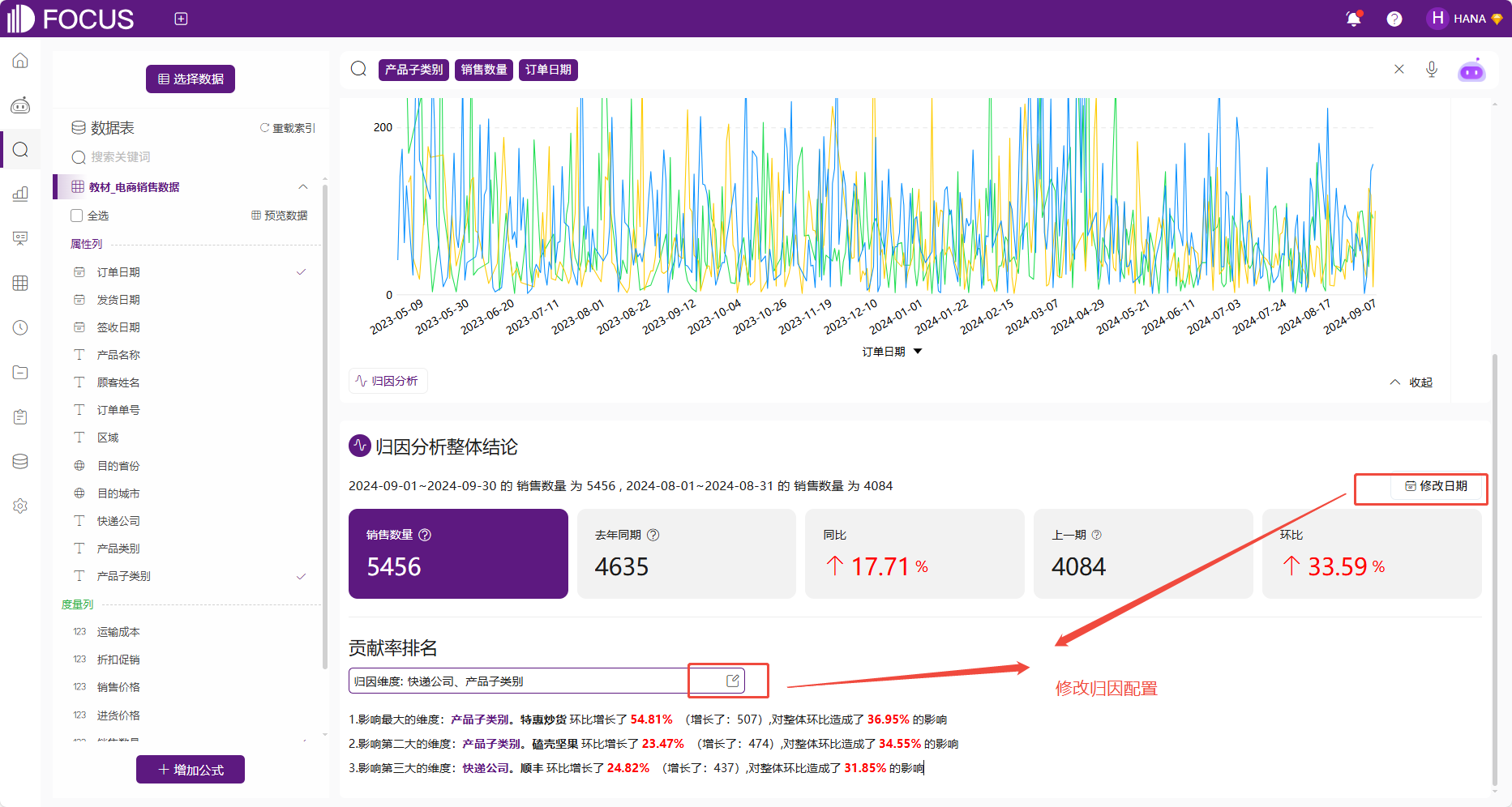
图 2-48修改归因配置
夏普利归因分析
不是所有类型的指标都适合使用Delta法进行贡献度归因。特别是当指标涉及复杂的相互作用或非线性关系时,就需要考虑其他方法,例如夏普利归因分析(Shapley value method)。
夏普利归因分析是合作博弈论中常用的一种信用分配方法。它是基于评估游戏中每个玩家的边际贡献,分配给每个个体参与者的信用值,即夏普利值Shapley value,是该边际贡献在所有可能的参与者排列上的期望值。
在市场营销中,夏普利值可以用来评估不同营销渠道在整个客户旅程中的贡献。传统的归因模型可能会将全部信用归给最后一个点击(Last Click Attribution)或者第一个接触点(First Click Attribution)。然而,这样的模型忽略了中间触点的重要性。夏普利值算法通过考虑所有触点的不同排列组合来提供一个更加公平的归因方法。

图 2-49夏普利归因公式
夏普利归因不像贡献度归因,在DataFocus系统中,夏普利归因只有一种触发方式,就是手动触发。同样简单介绍夏普利归因的触发方式和配置,帮助用户更好地学会利用这一功能。
点击图表左下角的归因分析后,再选择夏普利渠道归因。在参数配置页面,将左侧的属性列和度量列拖拽进对应的触发者列、转化渠道和转化结果中,如图2-50。这里可以看到,允许配置为参数的列需要先添加至搜索框,才可参与渠道归因。
触发者列:查询结果中的属性列
转化渠道:查询结果中的属性列
转化结果:查询结果中的度量列
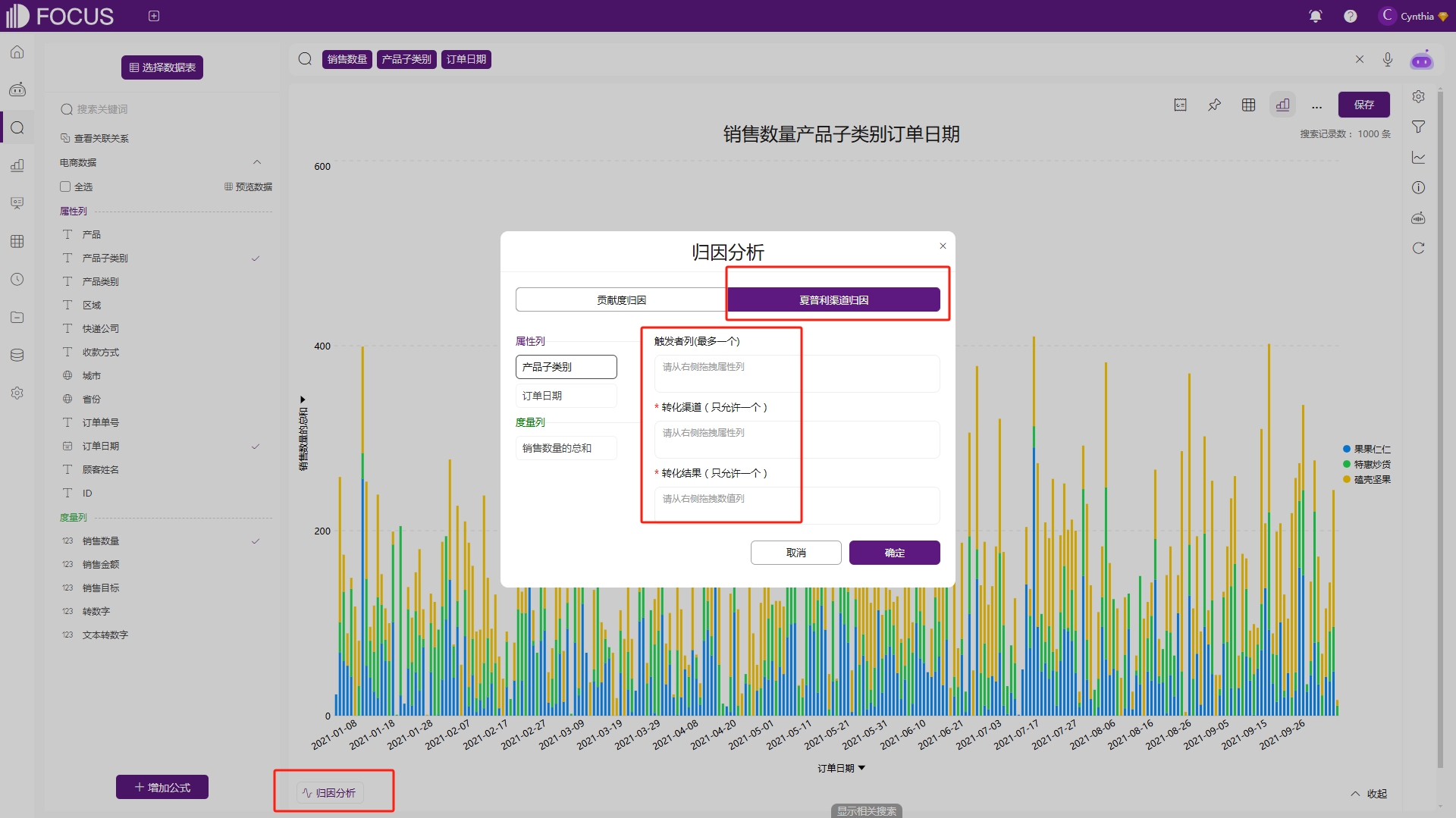
图2-50 渠道归因参数配置
同样的,有几个关键点需要注意:
(1)渠道归因分析的来源数据会受筛选条件影响;
(2)触发者列、转化渠道和转化结果都可以选择公式列;
(3)转化渠道选择的属性列的列中值不能超过15个。
时序预测
系统支持一键智能分析,只需点击左下角的“时序预测”按钮即可对当前时序数据进行智能预测,生成未来三个时间单位的趋势线。预测结果将以醒目的红色虚线在原有图表中延伸,直观展示未来走势。
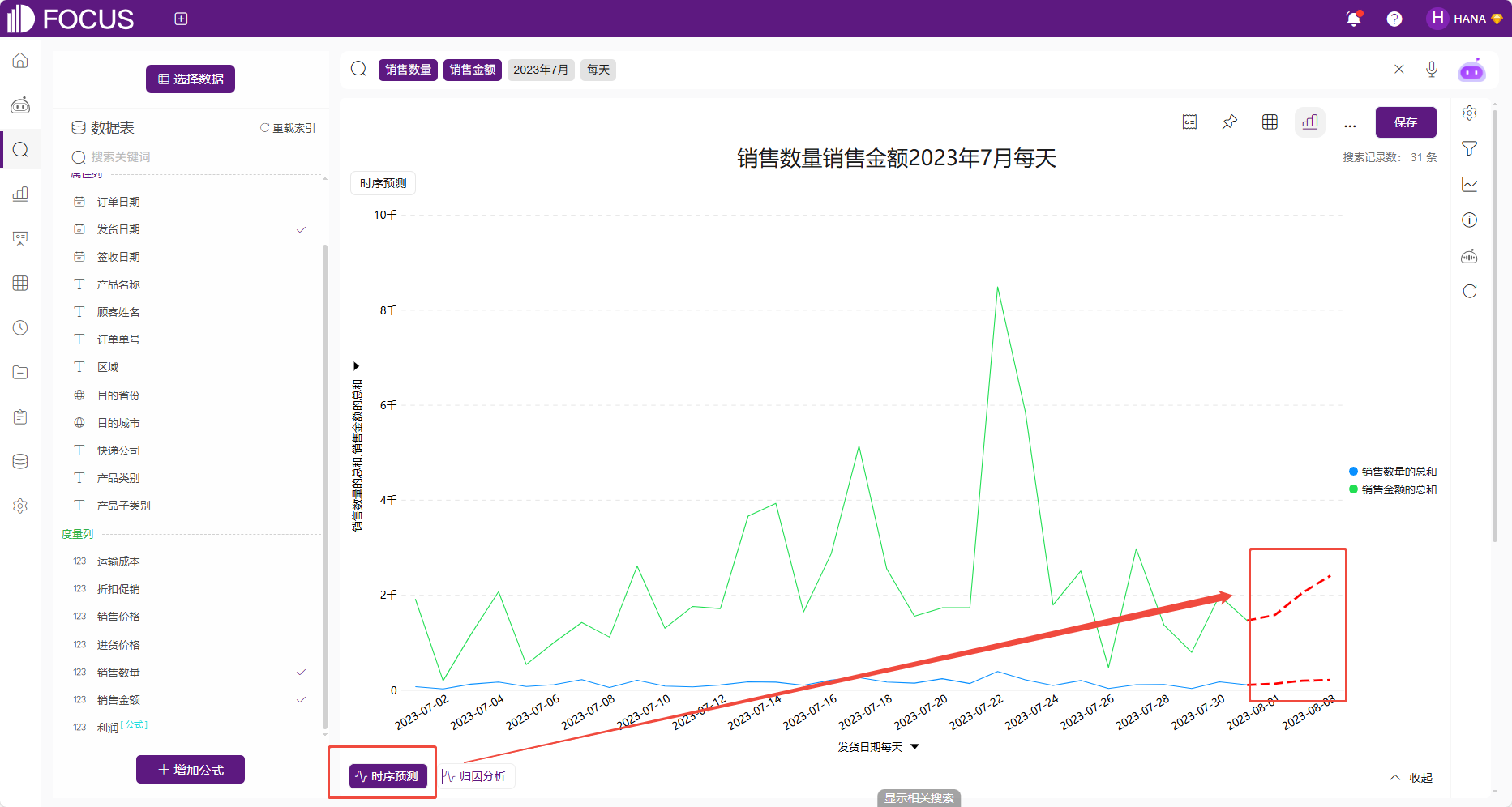
图 2-51时序预测
告警提示
日常业务中,我们需要监控很多指标信息,例如财务的各种专项能力分析,其实际就是各个不同的指标比率,如资产负债率、销售利润率、存货周转率等等。对于这种指标类型的数据,如何实时地监控,更好地掌握其变化情况,及时地将有效信息传递出去,是数据可视化的一个难点。
在DataFocus中,告警功能的出现,就是为了解决上述这些难点。可以对每月销售金额设置告警值,若低于该告警值,则图表中符合条件的数据将会红色闪烁以示警,同时还会发送一份告警消息通知有关人员该指标出现异常,需要重点关注,及时解决,如图2-52。
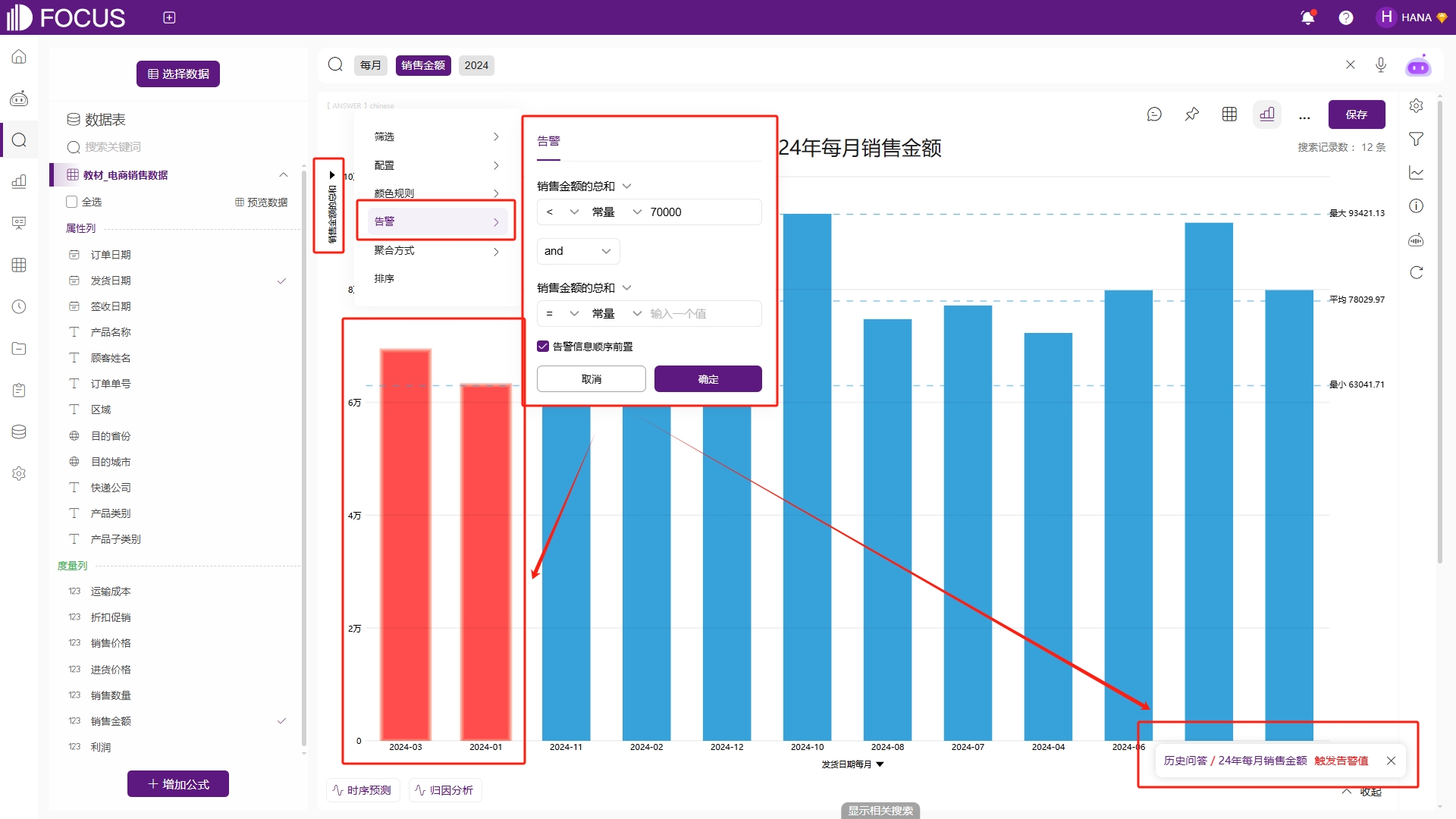
图2-52 告警配置
保存为历史问答
在搜索结束后,点击右上角“保存”按钮,可将当前搜索结果保存为历史问答,如图2-53。
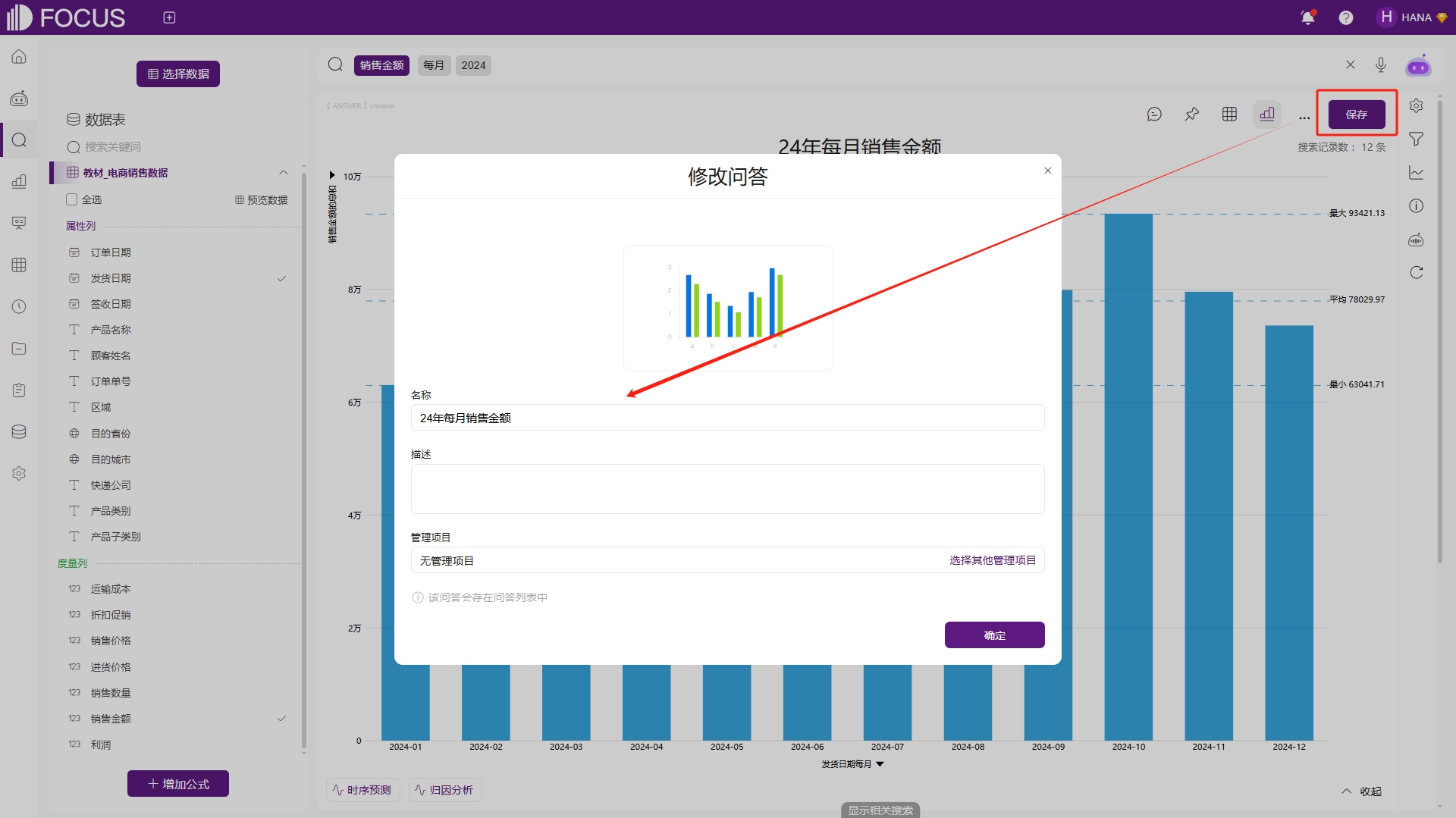
图2-53 保存为历史问答
后续想查看该图表时,只需在“项目”或者“历史问答”页面,通过命名的问答名称找到该问答,点击“编辑”按钮,重新回到搜索页面,对图表进行查看或更改,如图2-54。
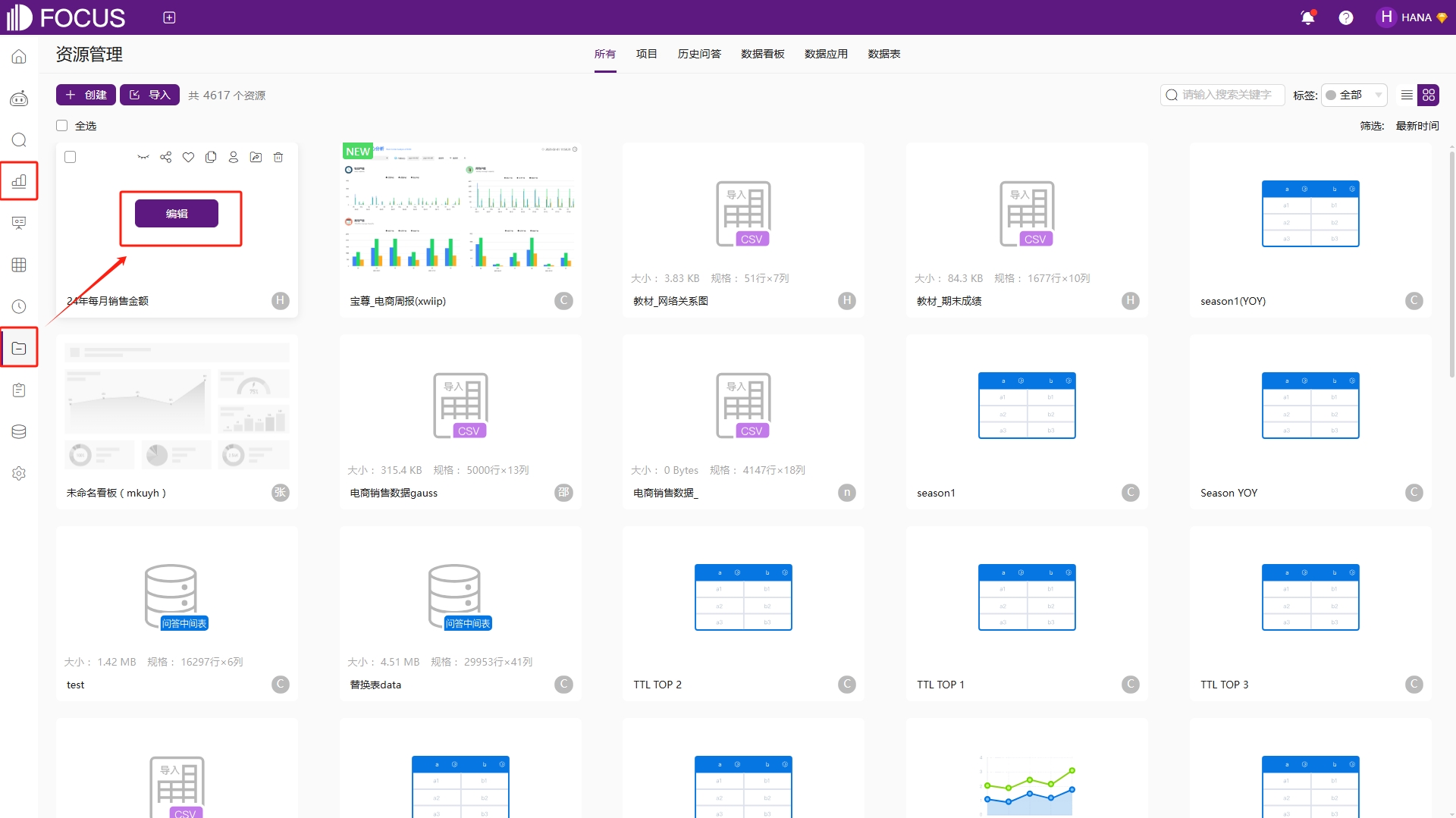
图2-54 重新编辑历史问答
保存为中间表
如果想把当前搜索结果保存一张数据表,后续可以在数据表上进行进一步分析,点击右上角的“…”按钮下的“保存为中间表”即可。后续可在资源管理或者数据表模块查看该数据表。
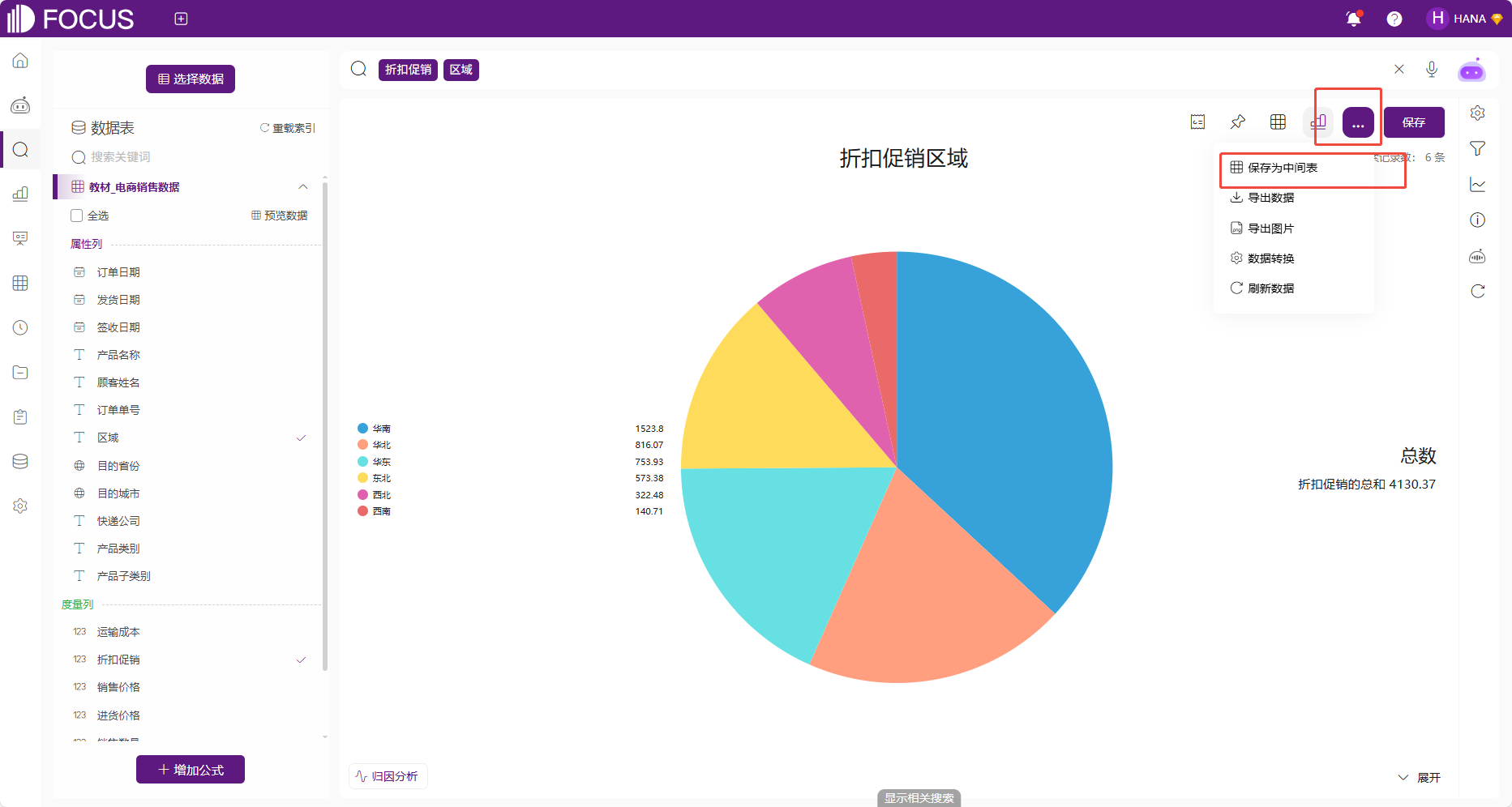
图 2-55保存为中间表
复制图表
查看问答时,点击右上角的“…”按钮下的“复制”按钮,即可复制该问答的图表,如图2-56。
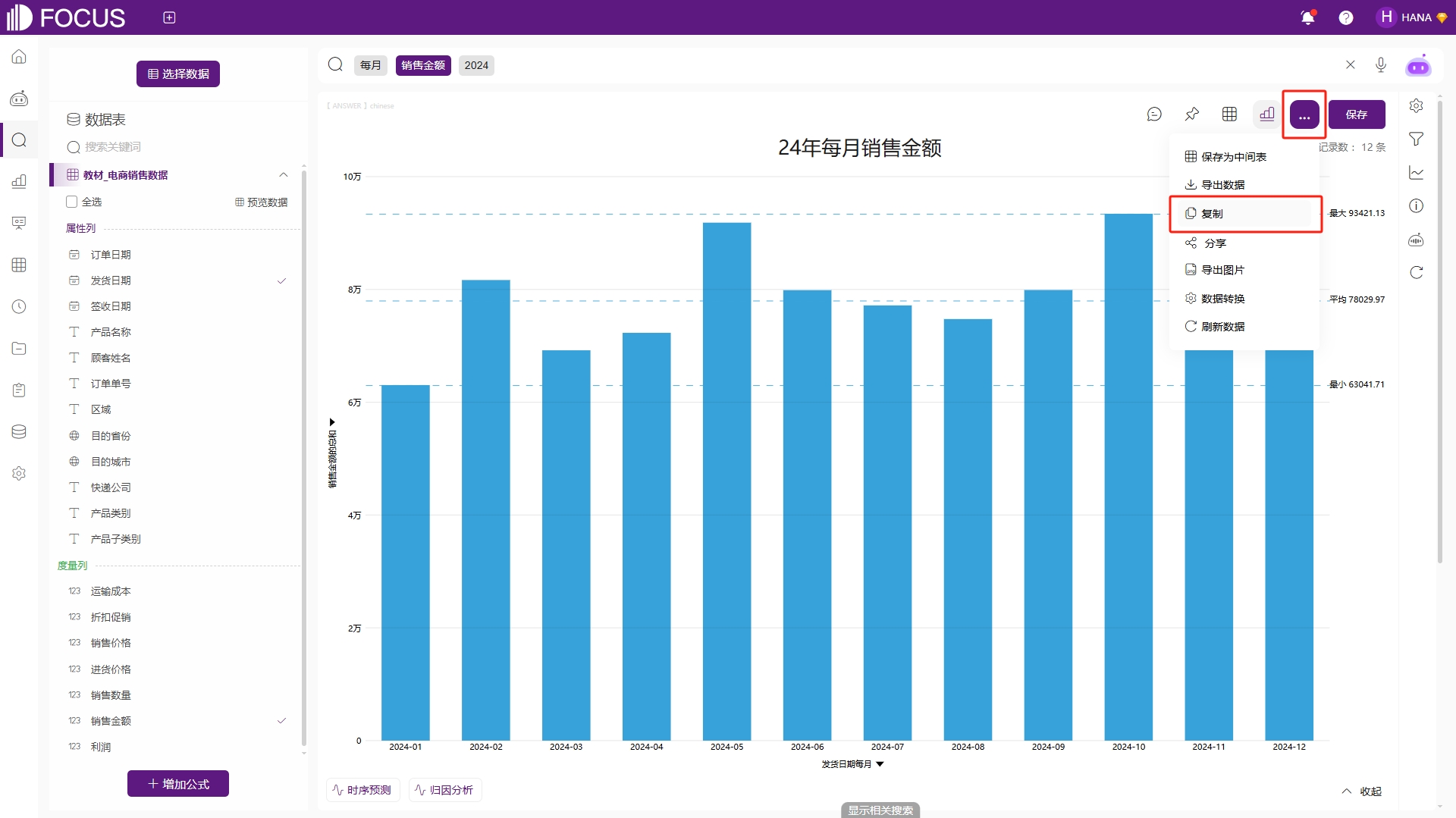
图2-56 复制问答
导出数据/图片
数据分析完成后,点击右上角的“…”按钮下的“导出数据”或“导出图片”即可进行单个图表的导出,如图2-57。
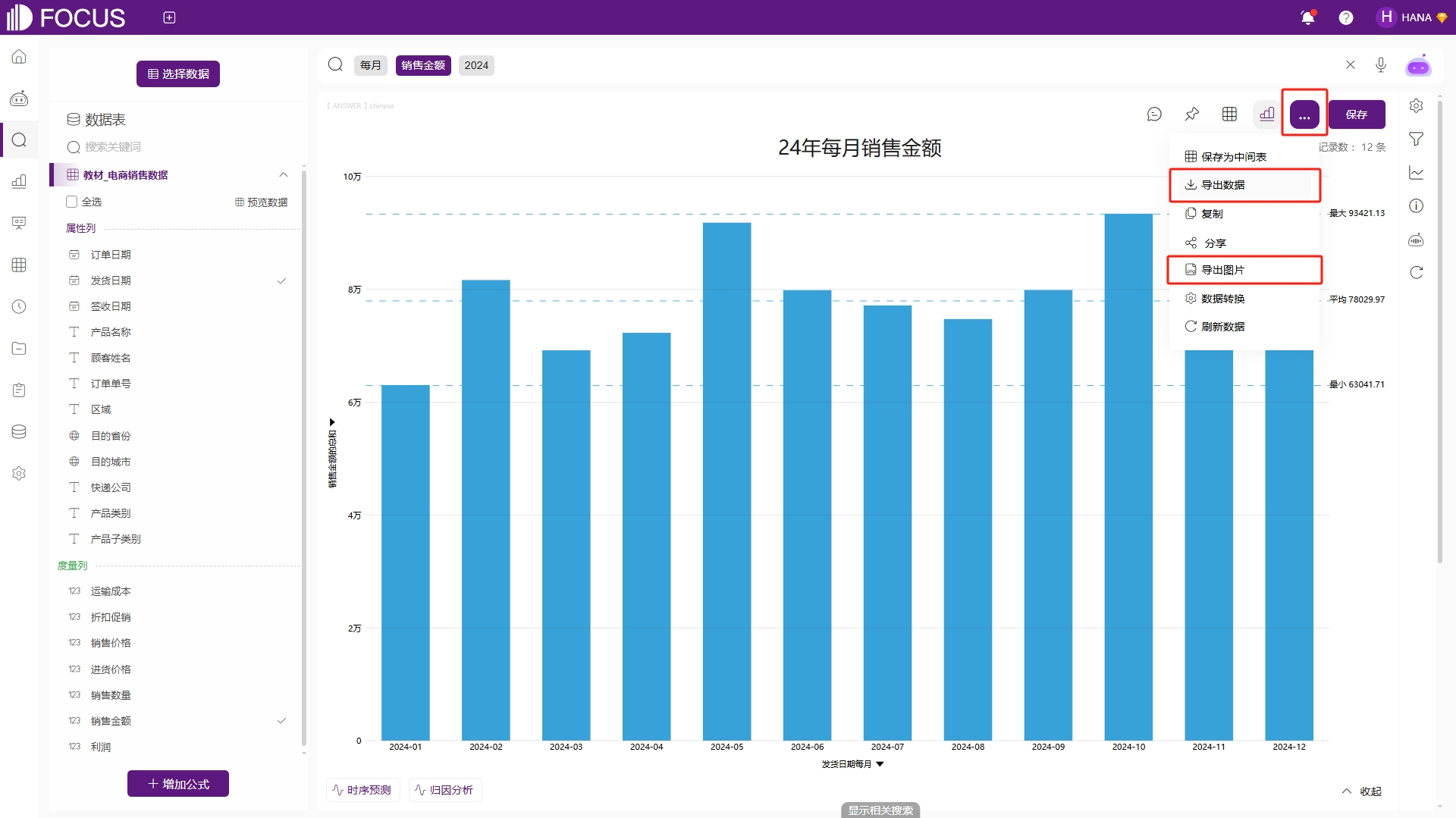
图2-57 单个图表导出
数据转换
DataFocus具备数据形式的转换功能,目前支持的数据形式转换有6种,分别是行转列、列转行、列错行、列合并、子查询、列拆分,如图2-58。
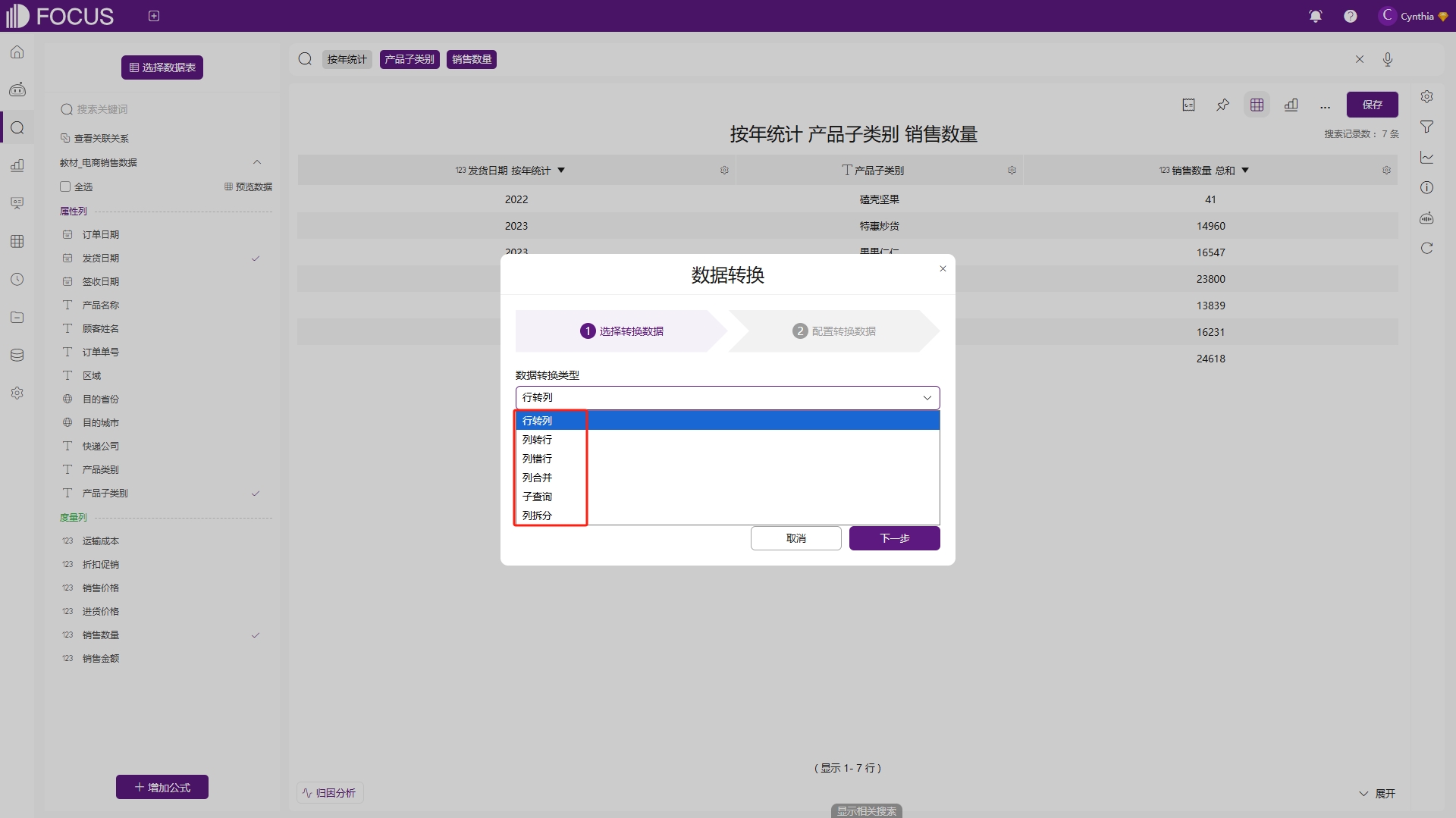
图2-58 数据转换类型
1. 行转列
行转列是将表中的行数据按照某些列的值重新组织成列数据的过程,可以将数据从行方向转换为列方向。其目的通常是为了方便数据分析和比较,通过行转列操作,可以将分散在多个行中的相关数据聚合到一列中实现多维度的数据分析,从而帮助企业更好地理解业务情况。举例如下,各科老师在查询学生成绩时,记录的数据如表2-2所示。将其通过行转列的操作后,得到的数据结果如表2-3所示。
表2-2 学科原始数据
| Student**_ID** | Subject | S****core |
| 0001 | 语文 | 90 |
| 0001 | 数学 | 100 |
| 0001 | 英语 | 85 |
| 0002 | 语文 | 88 |
| 0002 | 数学 | 92 |
| 0002 | 英语 | 95 |
表2-3 行转列效果
| Student**_ID** | 语文 | 数学 | 英语 |
| 0001 | 90 | 100 | 85 |
| 0002 | 88 | 92 | 95 |
2. 列转行
列转行功能可以被视为行转列的逆操作,对应的是数据从列方向转换为行方向。这两种数据转换是数据处理和分析中很常见的两种基础操作,当需要将原本分散在多个列中的数据合并到一起时,就很适合使用列转行功能。
例如,想了解职工的薪酬结构情况,选择基本工资、绩效工资、固定补贴、加班费、奖金或提成、其它补贴,得到如下图2-59原始2行6列的数据,该数据在DataFocus系统中仅支持仪表盘图、水位图等简单图形可视化。
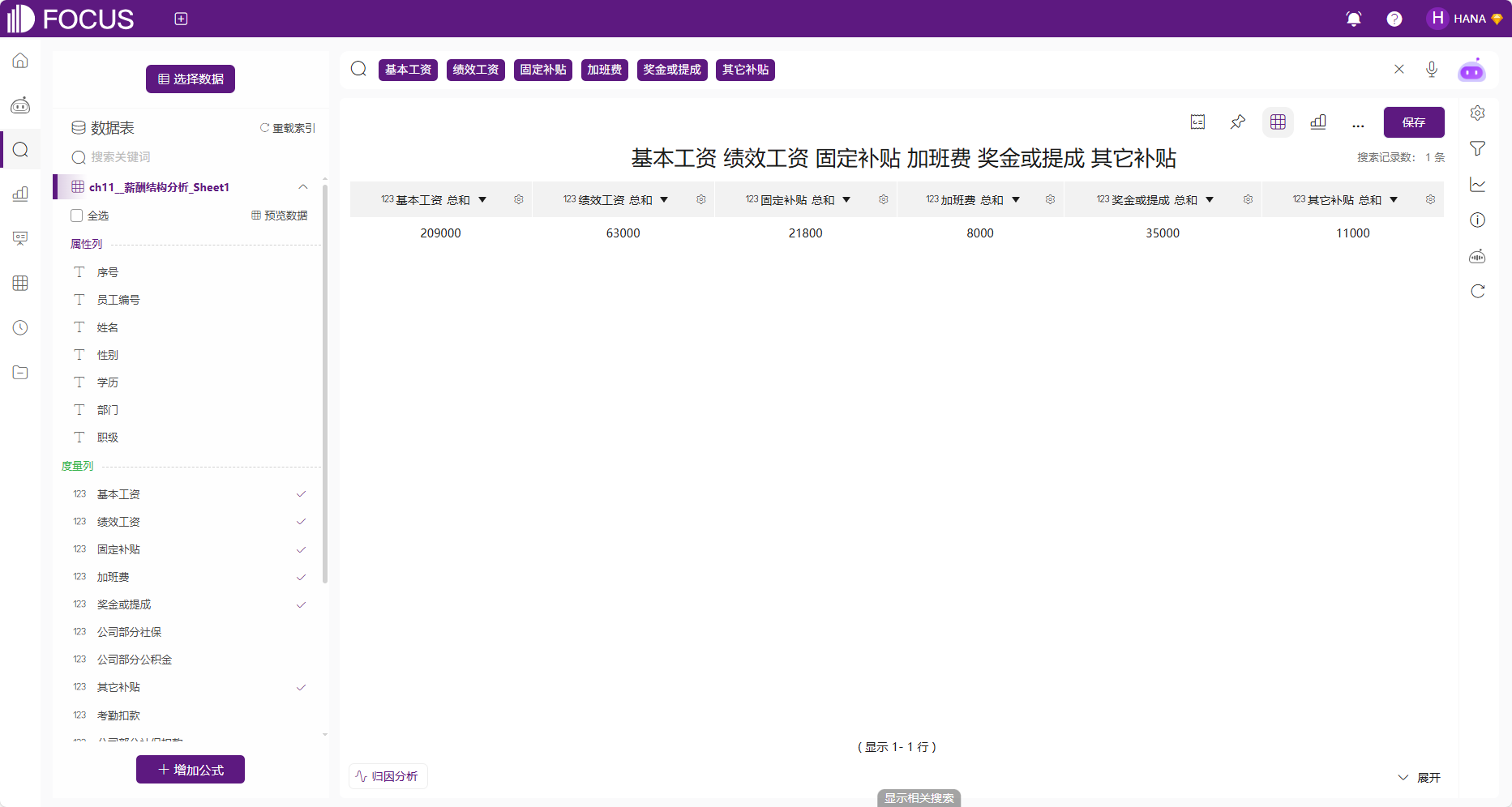
图2-59 薪酬结构原始数据
在数据转换界面选择“列转行”,如图2-60所示,点击“下一步”,进行列转行的配置。这里,需要给两列的列名定义新的名称,同时可以对转换后的列中值的名称进行修改,如图2-61所示。
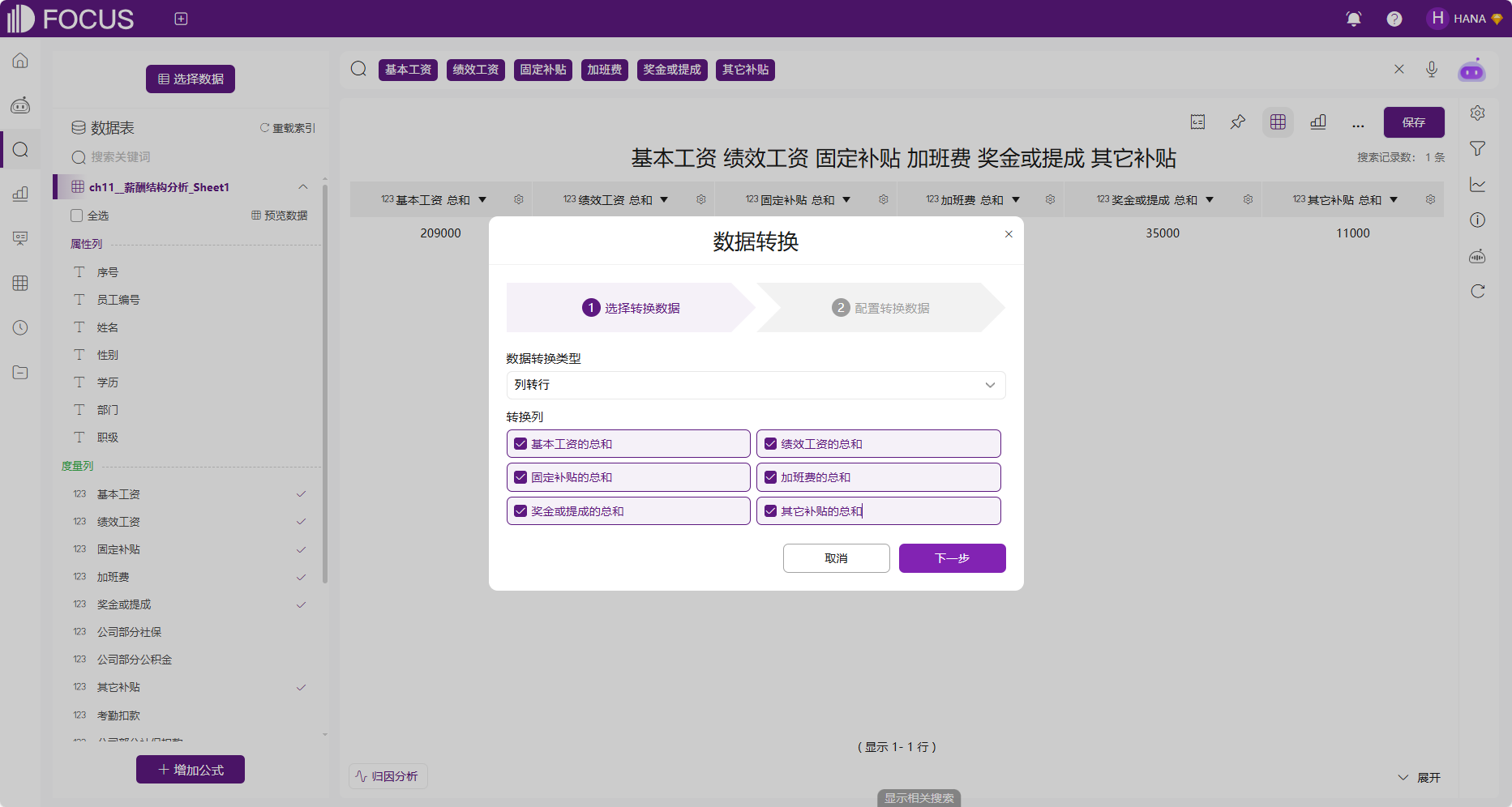
图2-60 薪酬结构数据转换界面
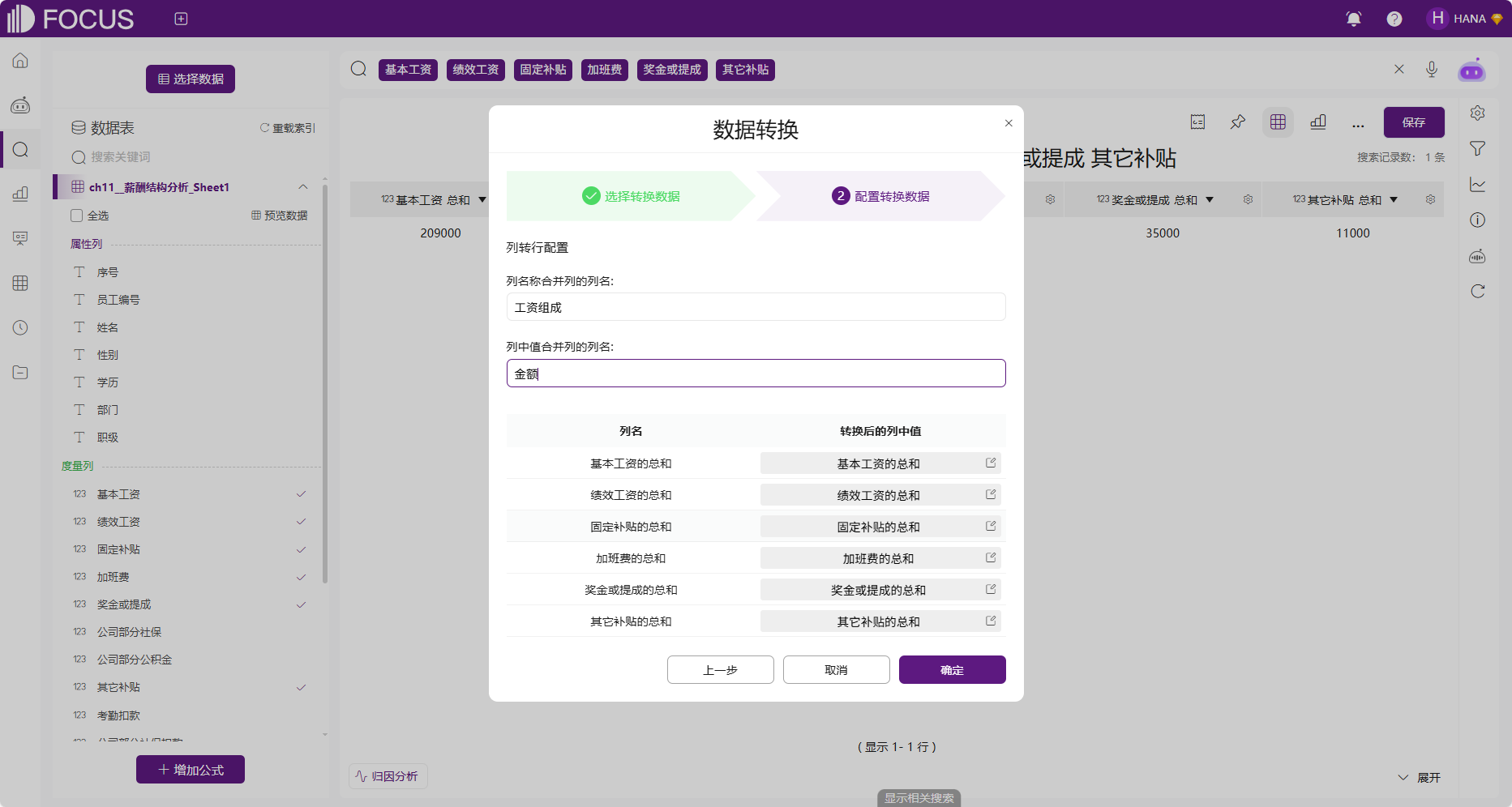
图2-61 薪酬结构数据列转行配置
在完成配置后点击“确定”按钮,就得到了新列名下的数据,该数据在DataFocus系统中支持柱状图、折线图等多种图形可视化方式,如下图2-62所示。
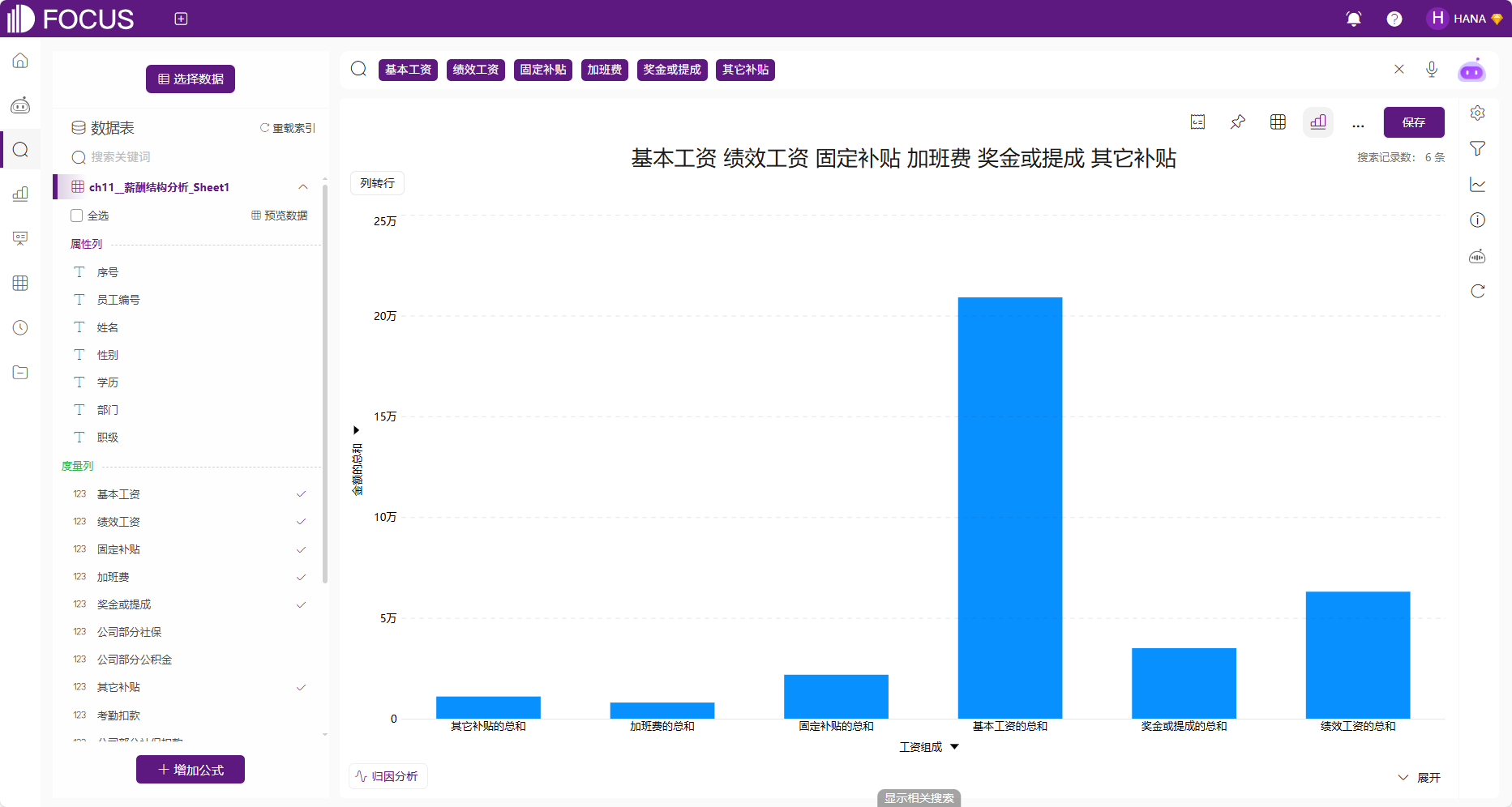
图2-62 薪酬结构新数据
3. 列错行
列错行是系统新增的数据转换功能,专为处理复杂数据排列需求及实际业务场景中的特殊情况设计。例如,表2-4是一份按月统计的销售额数据,当用户需要在同一行中同时查看当月与上个月的销售额数据,以便快进行同比计算时,就可以用到列错行功能。通过该功能,用户可以轻松地将上个月的销售额数据“错行”至本月数据的旁边,从而在视觉上实现数据的并置,数据结果如表2-5所示。
表2-4 销售额原始数据
| 月份 | 销售额 |
| 1月 | 43858.22 |
| 2月 | 155303.17 |
| 3月 | 51495.57 |
| 4月 | 36484.55 |
| 5月 | 35065.19 |
| 6月 | 43713.73 |
| 7月 | 9521.53 |
| 8月 | 13903.2 |
| 9月 | 14764.27 |
| 10月 | 11943 |
| 11月 | 62460.8 |
| 12月 | 74116.46 |
表2-5列错行效果
| 月份 | 销售额 | 上月销售额 |
| 1月 | 43858.22 | Null |
| 2月 | 155303.17 | 43858.22 |
| 3月 | 51495.57 | 155303.17 |
| 4月 | 36484.55 | 51495.57 |
| 5月 | 35065.19 | 36484.55 |
| 6月 | 43713.73 | 35065.19 |
| 7月 | 9521.53 | 43713.73 |
| 8月 | 13903.2 | 9521.53 |
| 9月 | 14764.27 | 13903.2 |
| 10月 | 11943 | 14764.27 |
| 11月 | 62460.8 | 11943 |
| 12月 | 74116.46 | 62460.8 |
此外,列错行功能还支持用户自定义错行的列数、参与错行的列以及排序的顺序。如图2-63所示,在错行行数处选择执行列错行的行数,勾选参与的字段并且设置排序方式为升序还是降序,设置完成后,会新增一列数据用于展示列错行后的数据。
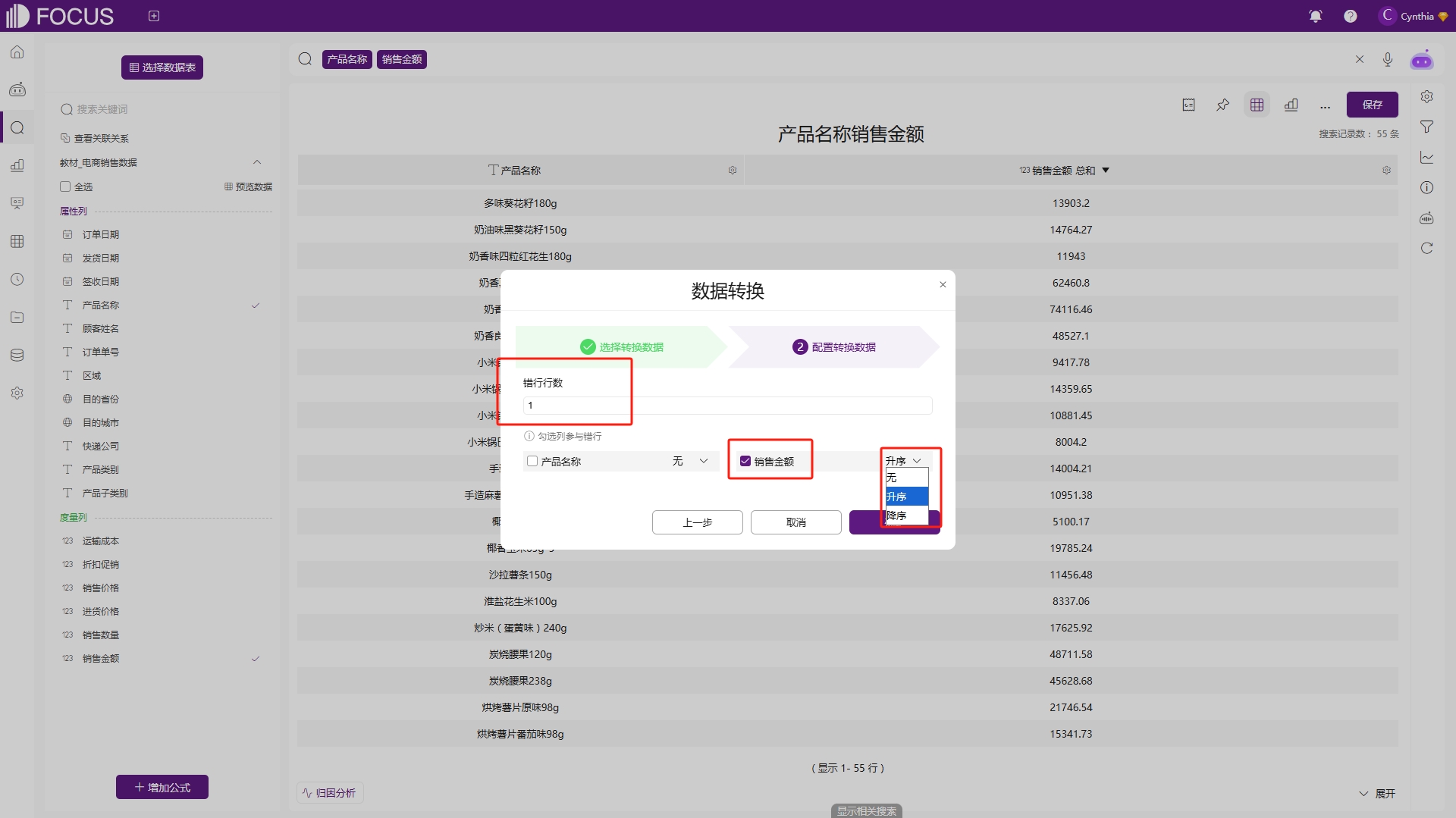
图2-63 列错行配置
4. 列合并
列合并功能的含义和合并中间表是类似的,通过将选中的字段进行数据聚合后实现上下合并的效果。区别在于,合并中间表是将具有相同字段(列)的多个数据表,按照行的顺序合并成一个数据表的过程,通常用于整合结构相同但来源不同的多个数据表。列合并则是强制合并功能,允许字段的数据类型不同。
列合并功能是将多列数据整合为一个新的列输出,在查询结果中同时显示多个字段值,便于用户查看,还可以优化索引,减少索引中的段数量,提高搜索性能。虽然这不是直接的数据合并,但可以从数据组织和优化的角度理解为一种“合并”操作。假设有一张员工表,其中包含员工ID、性别、年龄、学历、籍贯等基础信息如表2-6,现需要查询某学历以上的全体员工信息,则可以用到列合并功能,结果如表2-7所示。
表2-6 员工信息原始数据
| 填表人****ID | 性别 | 年龄 | 学历 | 籍贯 |
| ID001 | 女 | 27 | 硕士 | 北京 |
| ID002 | 男 | 44 | 博士及以上 | 浙江 |
| ID003 | 女 | 41 | 大专 | 黑龙江 |
表2-7 列合并效果
| 员工信息 |
| 27 |
| 44 |
| 41 |
| 女 |
| 男 |
| 女 |
| 浙江 |
| 黑龙江 |
| 北京 |
| ID002 |
| ID003 |
| ID001 |
| 博士及以上 |
| 大专 |
| 硕士 |
5. 子查询
子查询又可以叫嵌套查询,是一种嵌套在其他语句中的查询,即为基于一个查询结果进行进一步查询。举例说明,如表2-8是一份商品销售数据,其中通过公式“销售金额/订单数”,计算得到了各区域的不同产品子类别的客单价。其中,客单价在DataFocus系统中可以直接通过在搜索框输入“销售金额的平均值”实现。
表2-8 商品销售数据
| 区域 | 产品子类别 | 销售金额 | 订单数 | 客单价 |
| 东北 | 磕壳坚果 | 158334.3 | 251 | 630.81394 |
| 东北 | 特惠炒货 | 29697.24 | 155 | 191.59510 |
| 东北 | 果果仁仁 | 77274.483 | 170 | 454.55578 |
| 华东 | 特惠炒货 | 33581.622 | 201 | 167.07275 |
| 华东 | 果果仁仁 | 81760.752 | 220 | 371.63978 |
| 华东 | 磕壳坚果 | 207105.183 | 344 | 602.04995 |
| 华北 | 果果仁仁 | 101710.505 | 225 | 452.04669 |
| 华北 | 特惠炒货 | 41674.255 | 231 | 180.40803 |
| 华北 | 磕壳坚果 | 219721.932 | 360 | 610.33870 |
| 华南 | 果果仁仁 | 197821.005 | 468 | 422.69446 |
| 华南 | 磕壳坚果 | 394466.195 | 664 | 594.07559 |
| 华南 | 特惠炒货 | 70000.959 | 398 | 175.88181 |
| 西北 | 磕壳坚果 | 95449.963 | 144 | 662.84697 |
| 西北 | 特惠炒货 | 15654.261 | 84 | 186.36025 |
| 西北 | 果果仁仁 | 48333.783 | 97 | 498.28642 |
| 西南 | 果果仁仁 | 15556.591 | 41 | 379.42905 |
| 西南 | 磕壳坚果 | 41702.285 | 59 | 706.81839 |
| 西南 | 特惠炒货 | 7213.879 | 35 | 206.11083 |
通过子查询可以添加不同维度的聚合方式,在弹出的数据转换对话框中选择“添加子查询”,选择查询字段“销售金额”并命名为“平均销售额”后配置聚合方式为“平均值”,再删除一个属性列“产品子类别”,如图2-64所示,得到如图2-65的查询结果。这里的平均销售额是按照产品子类别对区域汇总的销售金额求平均值,即同一区域的销售金额求和除以产品子类别的去重后的数量(这里是数值3)。区别于客单价,两列数据的聚合方式都是平均值,但数据结果完全不同,客单价的平均值是按照产品子类别对区域汇总后的客单价求平均。
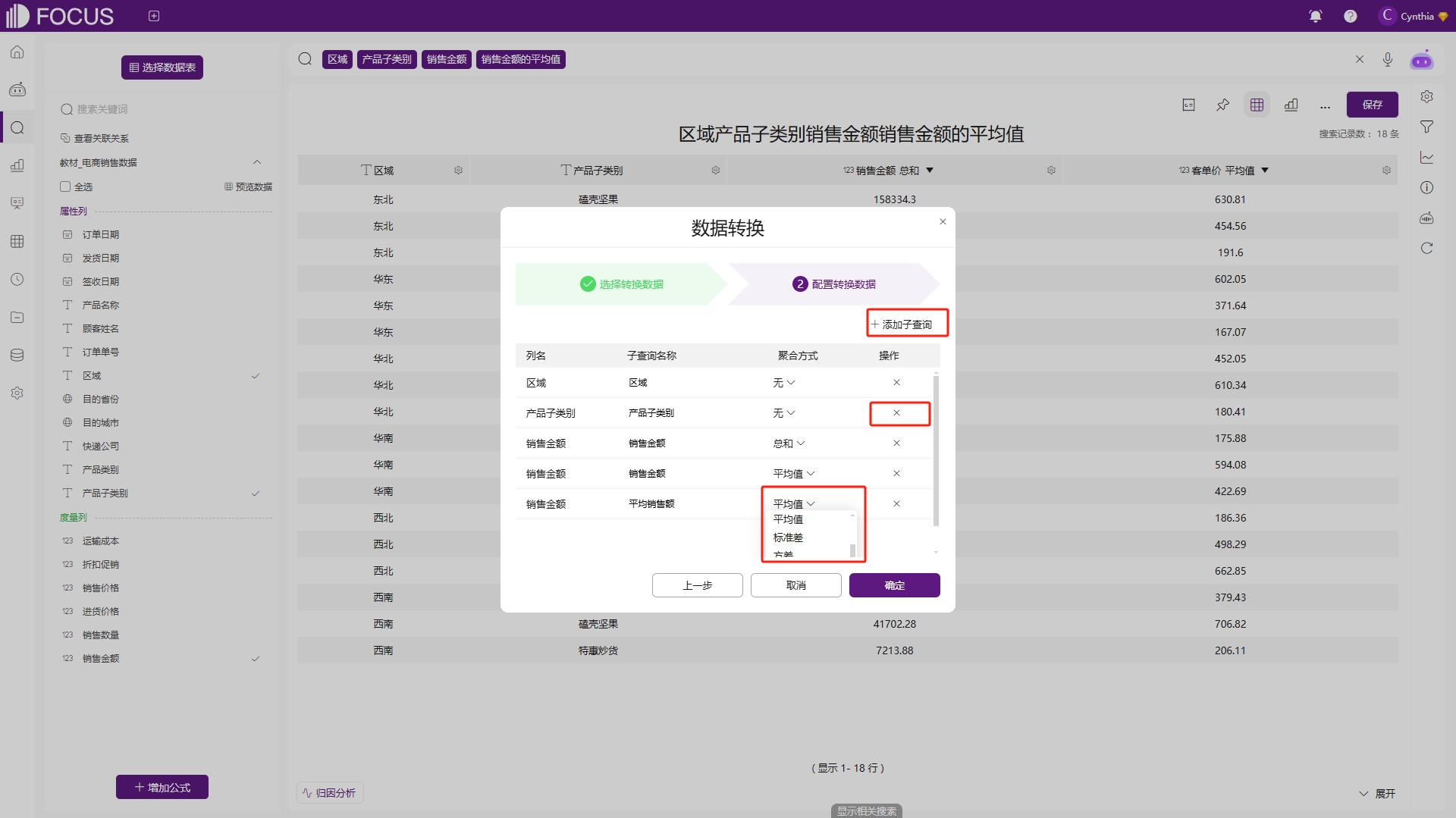
图2-64 子查询配置
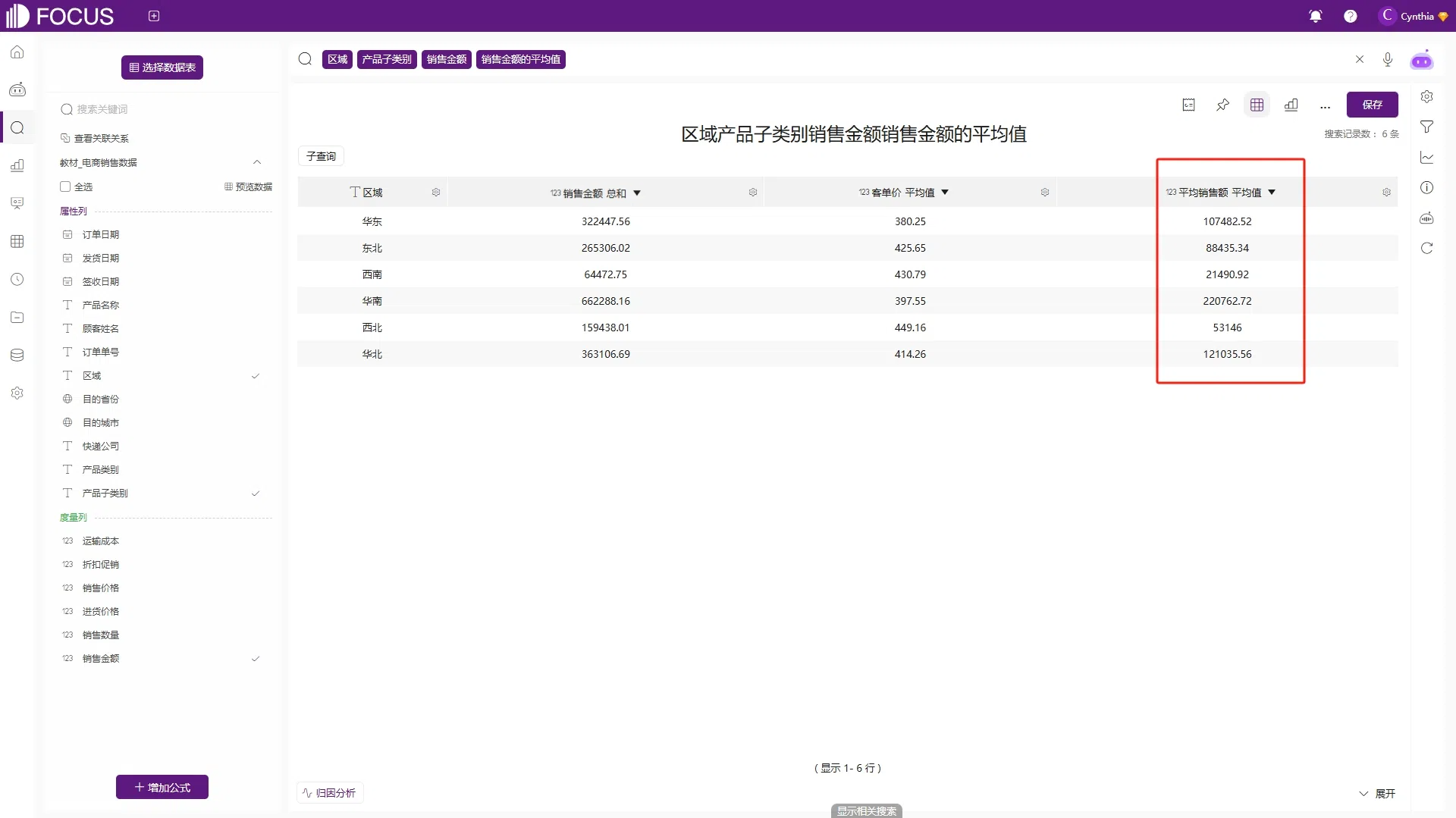
图2-65 子查询效果
6. 列拆分
列拆分数据是Excel等电子表格软件中常用的数据处理功能,它允许用户根据特定的分隔符或拆分列数将一列数据拆分成多列。假设有一张店铺分布表如表2-9,现需要将其按照“-”符号拆分成四列,参照图2-66配置列拆分的拆分列数和分隔符,并为拆分后的字段列命名,即可完成列拆分,拆分结果如图2-67。
表2-9 拆分前原始数据
| 数据**_**ID |
| 华北销售1部-飞跃店-张飞-20170211 |
| 华南销售1部-隆回店-曹操-20130319 |
| 华南销售2部-五洲分店-刘备-20200506 |
| 华北销售2部-大夏会分店-孙权-20160801 |
| 华南销售3部-鱼跃分店-诸葛亮-20190916 |
| 华北销售3部-三本分店-司马懿-20150618 |
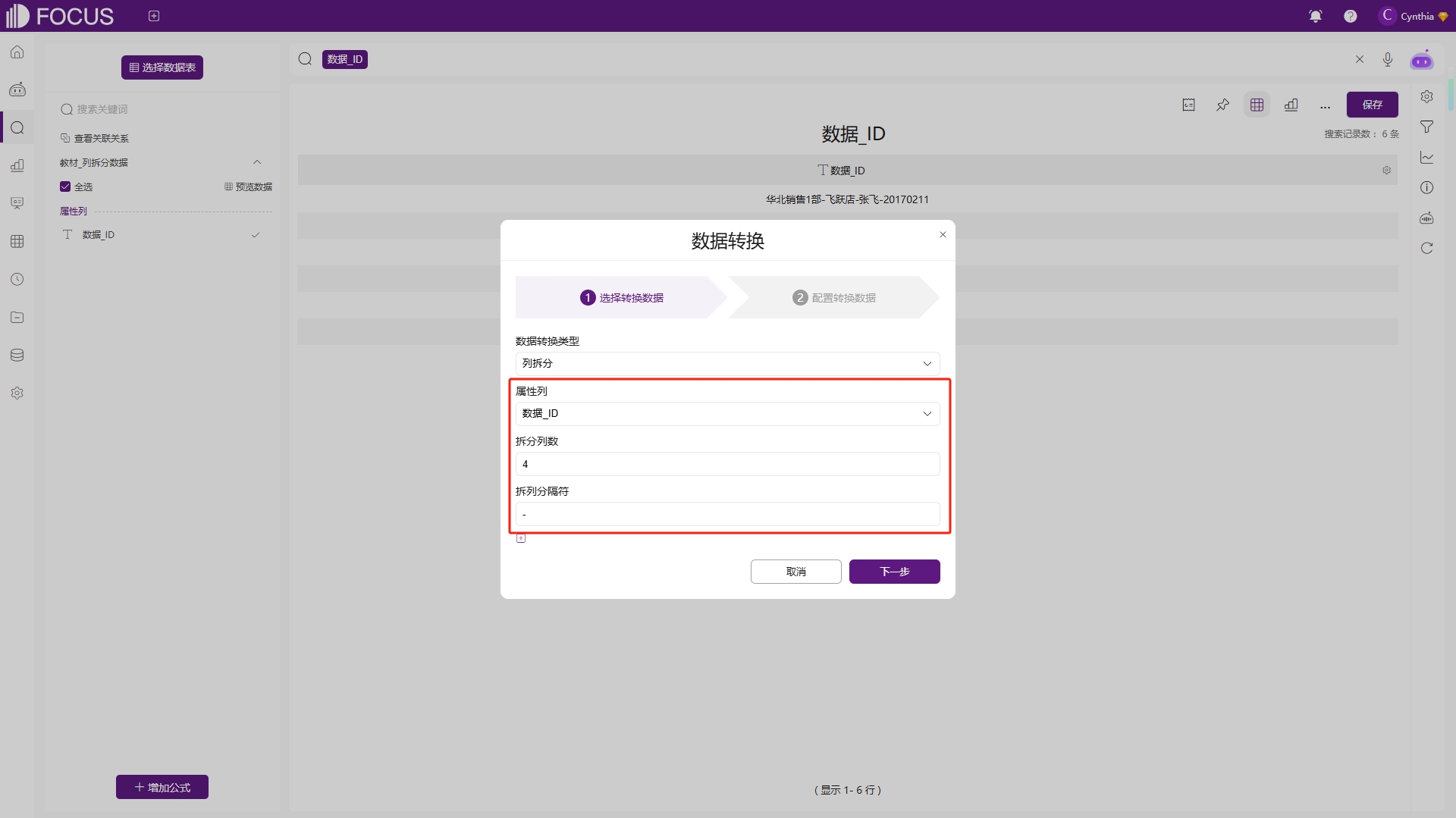
图2-66 列拆分配置
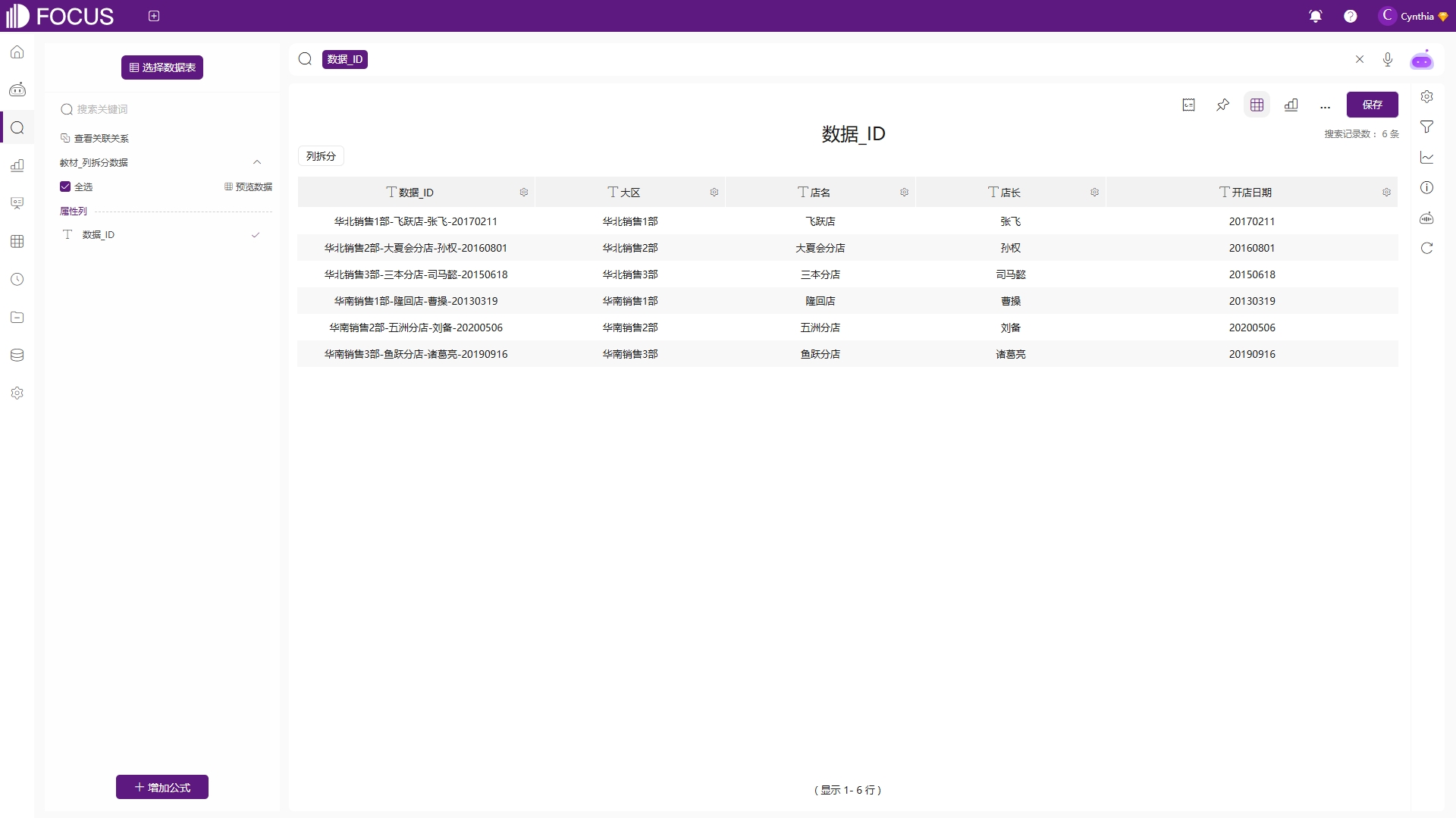
图2-67 列拆分效果
以上介绍了多种数据转换的方式,在实际应用中,用户可以根据具体的需求和数据结构来选择合适的功能进行数据实现。