数据表管理
数据表管理模块支持查询和管理DataFocus系统内的全部数据表。在数据表管理界面,用户可以执行数据表的导入、中间表的创建、视图的创建以及数据表字段详情等,同时还可以根据数据表不同的导入或创建类型进行区分筛选。
数据的导入与导出
从本地导入表
DataFocus目前支持四种数据表连接方式,即从本地导入、从数据源导入、从API导入和从HTTP接入数据表。通过左侧“数据表管理”功能界面点击“导入表”,之后可以根据数据表的具体位置选择合适的连接方式。
点击“从本地导入表”,可导入CSV、XLS、XLSX以及JSON等本地数据文件,单次导入的数据量需要小于50兆字节,如图6-1。当大于50兆字节时,可以选择多次导入。选中后点击上传,并确认行列属性是否正确。若行列属性不正确,如某些数值列被识别成string格式,则会导致这些数值列无法进行“求和、平均值、最大值”等操作。同时,某些字符串列,如编号、产品号等,被识别成数值列,也会导致出现对这些列进行聚合运算等无意义的结果。
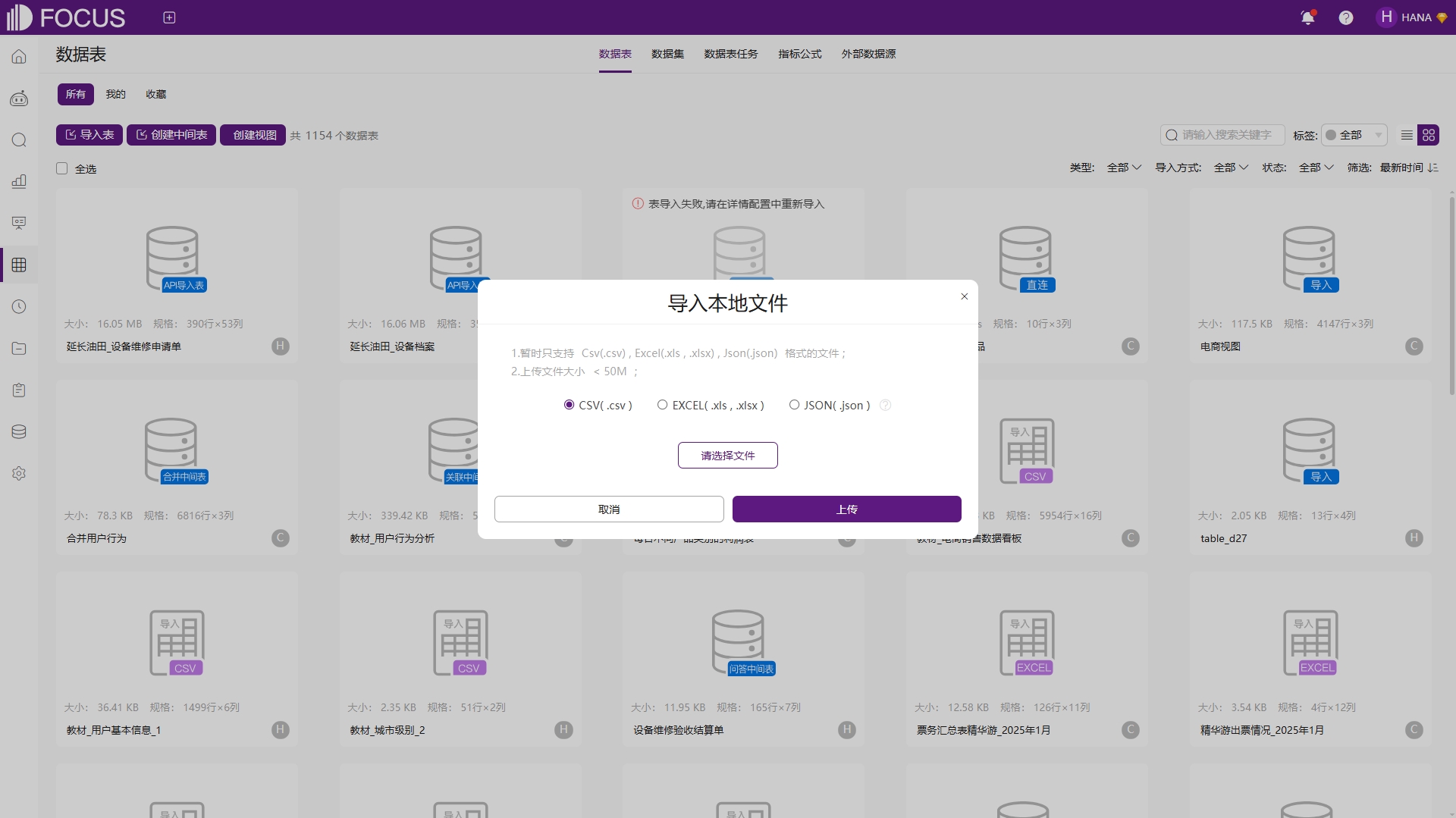
图6-1 本地导入
当选择的数据表文件包含多个Sheet时,系统会提供所有表格供使用者挑选合适的Sheet同时导入,每个表格的数据列的相关配置和单表的配置相同,如图6-2。
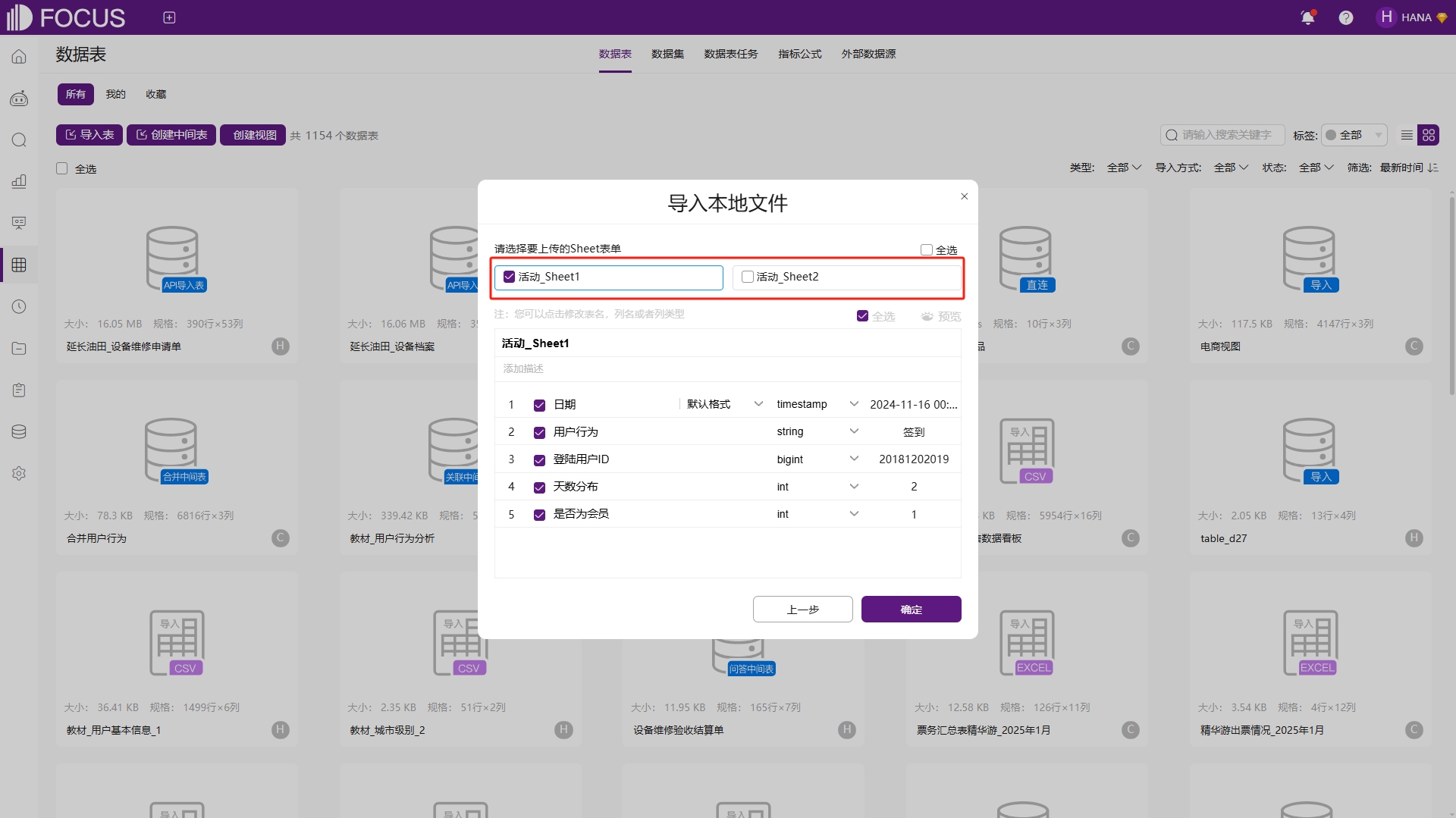
图6-2 本地数据表多个表格导入界面
从数据源导入表
点击左侧“数据管理”模块,然后点击左上方“导入表”按钮,点击“从数据源导入表”,跳转到选择数据源界面,此时可以选择已添加的数据源,或者新增数据源,如图6-3。
图6-3 选择数据源
选择数据源之后,点击下一步,选择需要从该数据源导入的表和数据列,导入方式可以选择“直连”和“导入”,如图6-4。需要注意的是,导入操作会将数据导入并存储到DataFocus自带的数据仓库;直连操作仅读取元数据,不会将数据存储到DataFocus中,分析时系统会临时链接数据源进行查询计算。若是操作大数据集进行分析,建议使用导入数据,DataFocus数据仓库性能可保障分析顺畅;直连数据分析则依靠对方设备的数据库性能,仅在数据量不大且即时性要求较高时建议使用。
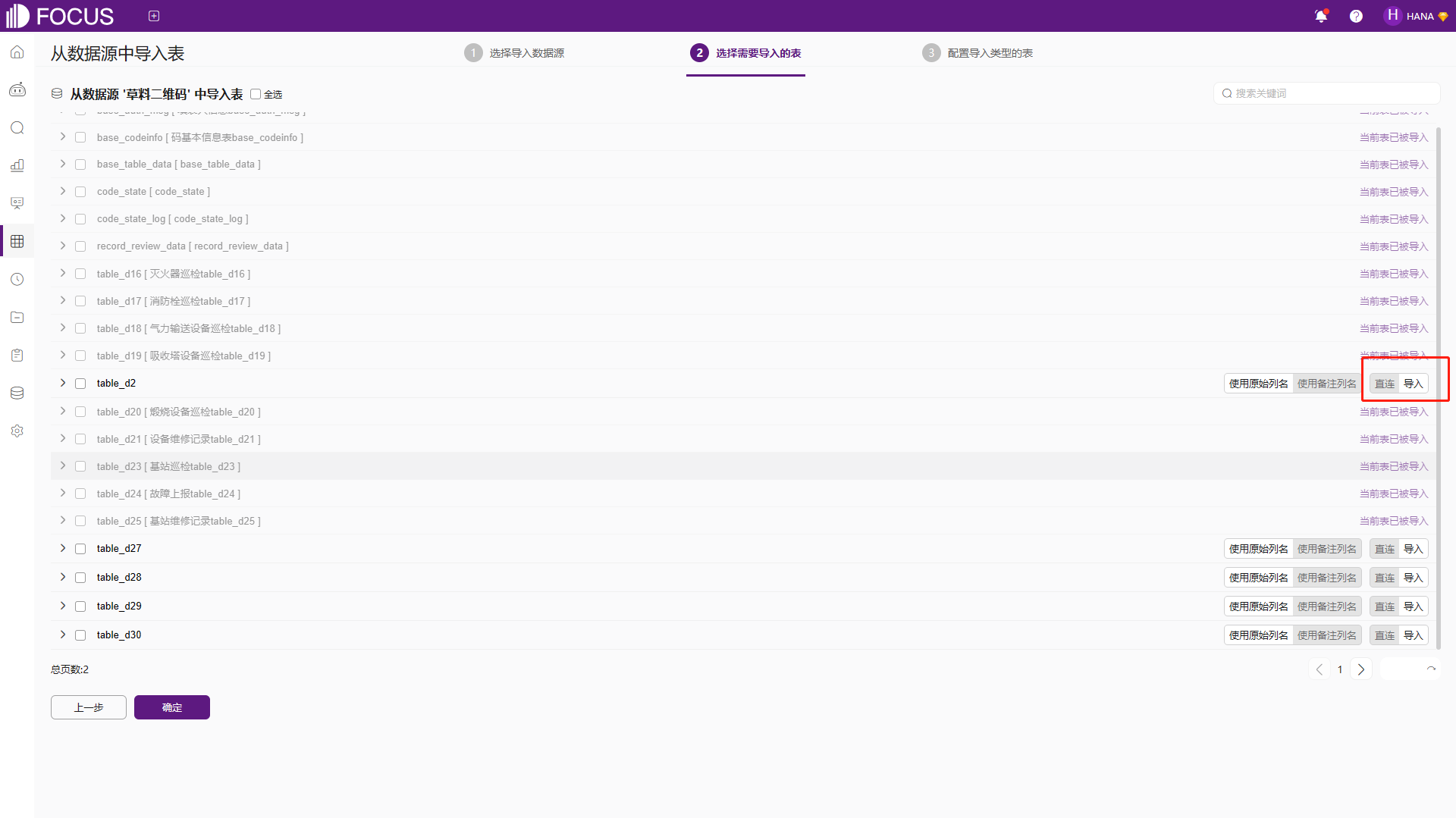
图6-4选择导入表
选择导入表和导入方式后,点击“确定”按钮,直连数据即可配置完成,返回列表可查看导入状态。直连数据支持实时更新,数据库中数据有变化时,DataFocus中直连的这些表,以及依赖这些表制作的中间表都能实时更新。
导入数据支持定时更新,如果选择的数据表存在“导入”方式则会进入第三步,“配置导入类型的表”,可以配置表过滤条件以及配置数据表的简单重复或者明细频率的定时导入,点击“开始导入”按钮,返回列表可查看导入状态。
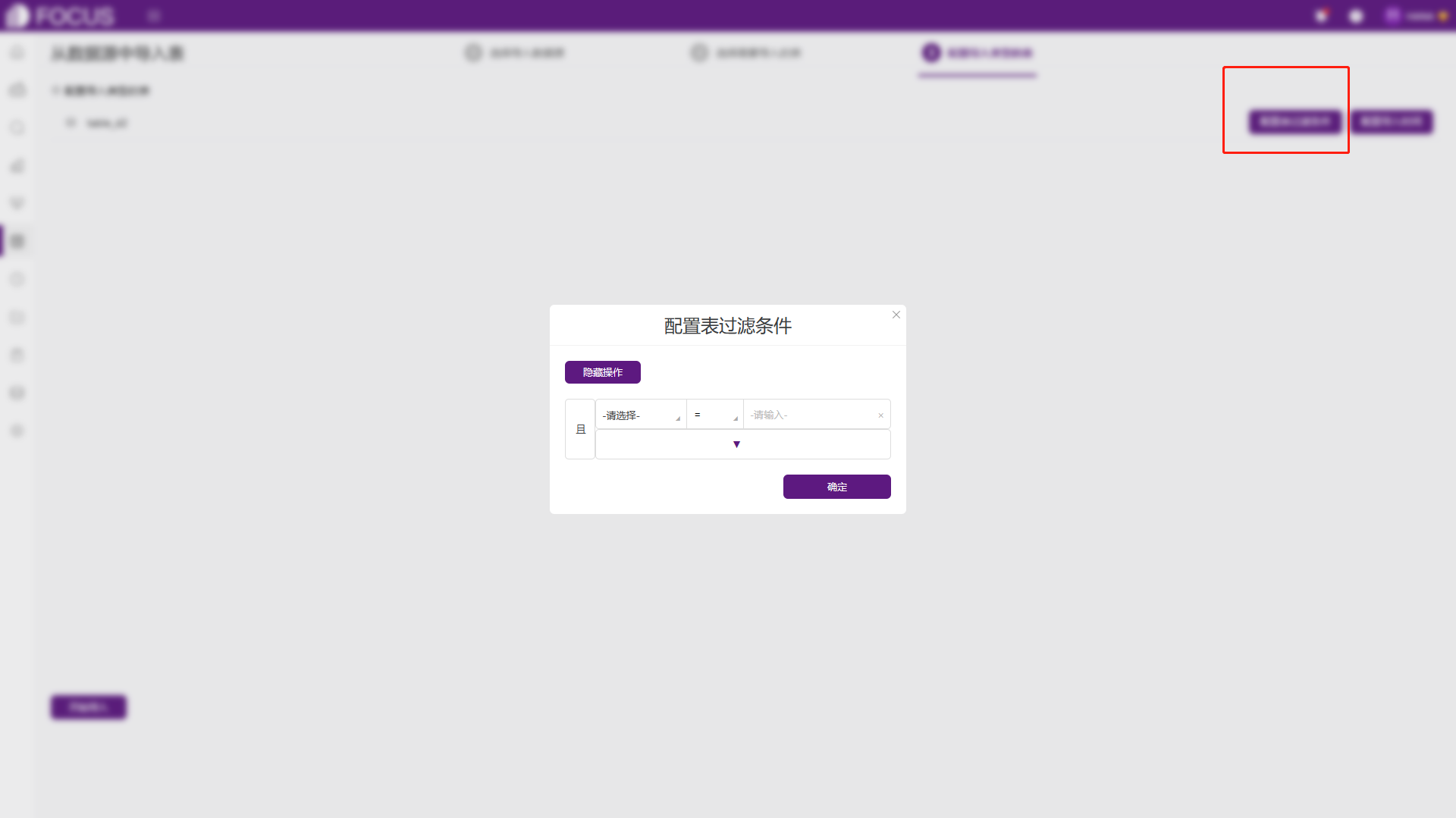
图6-5 配置表过滤条件
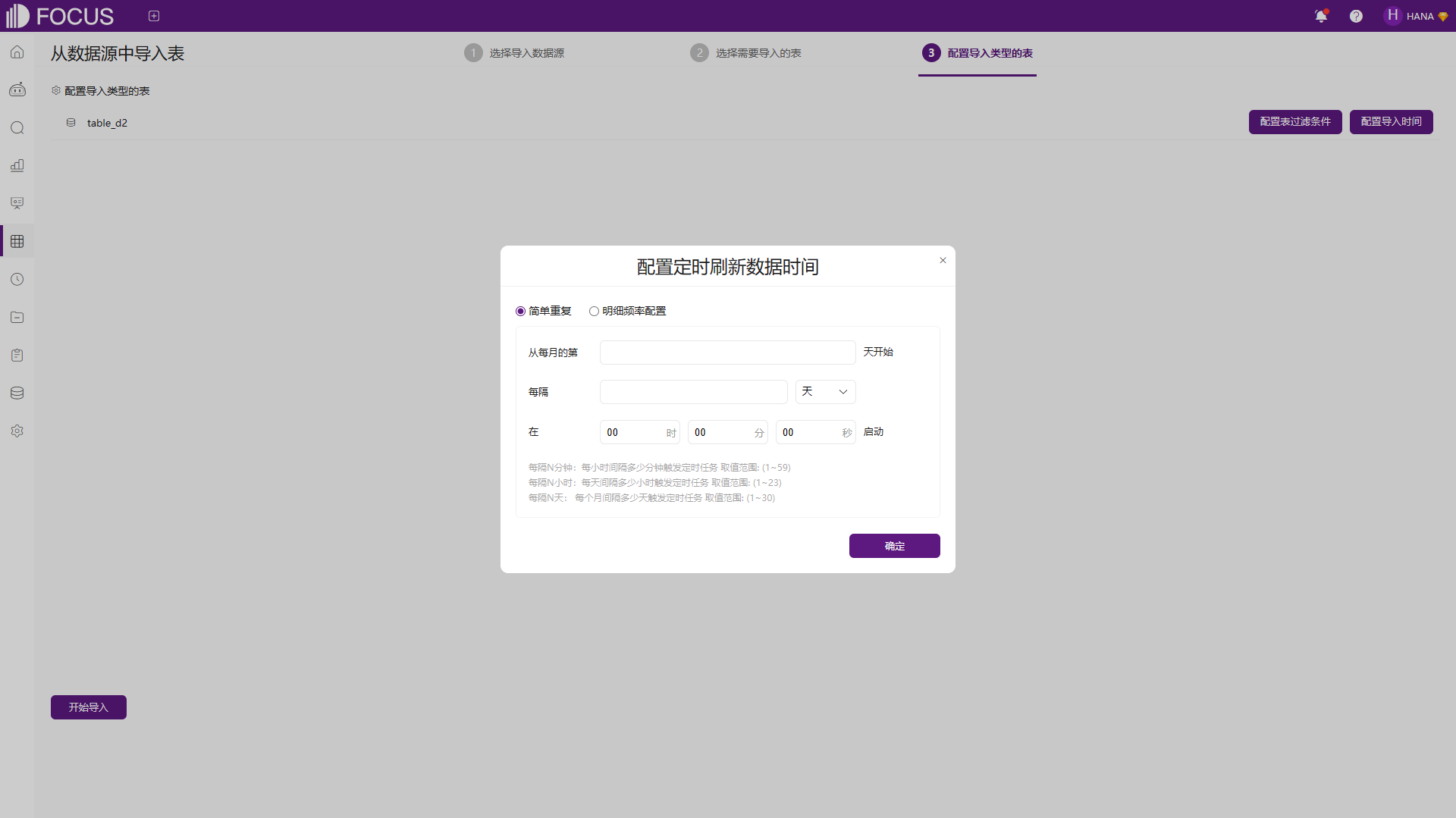
图6-6 配置定时导入时间
新增数据源选项中目前支持PostgreSQL,MySQL,Oracle,GaussDB 100,SQL Server,IBM DB2等20余种类型的数据库,这些数据源涵盖了主流的关系型数据库和常用的分析型数据库,能够满足不同场景下的数据导入需求。在新增数据源的过程中,用户需要配置以下关键信息:选择数据源类型,并输入数据源名以便识别。接着,填写服务器地址、端口、数据库名,以及可选的Schema(不填则使用默认)。此外,用户还需提供JDBC参数(如连接属性)、用户名及对应密码。为确保配置正确,建议使用测试连接功能进行验证。一旦信息核实无误,点击确定即可完成数据源添加,如图6-7。
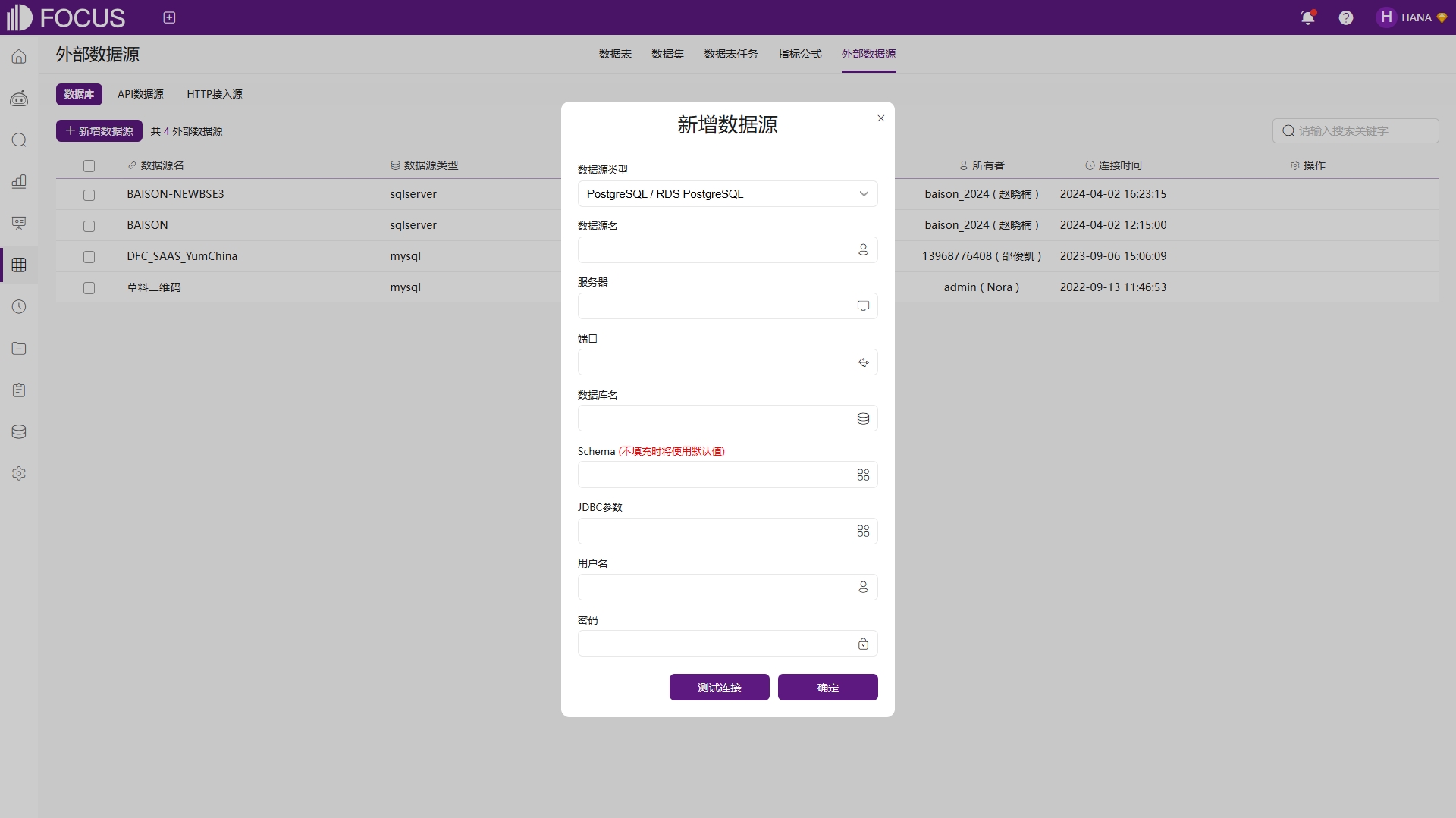
图6-7 新增数据源
从API导入表
点击左侧“数据管理”模块,然后点击左上方“导入表”按钮,点击“从API导入表”,跳转到选择数据源界面,此时可以选择已添加的API数据源,如图6-8。
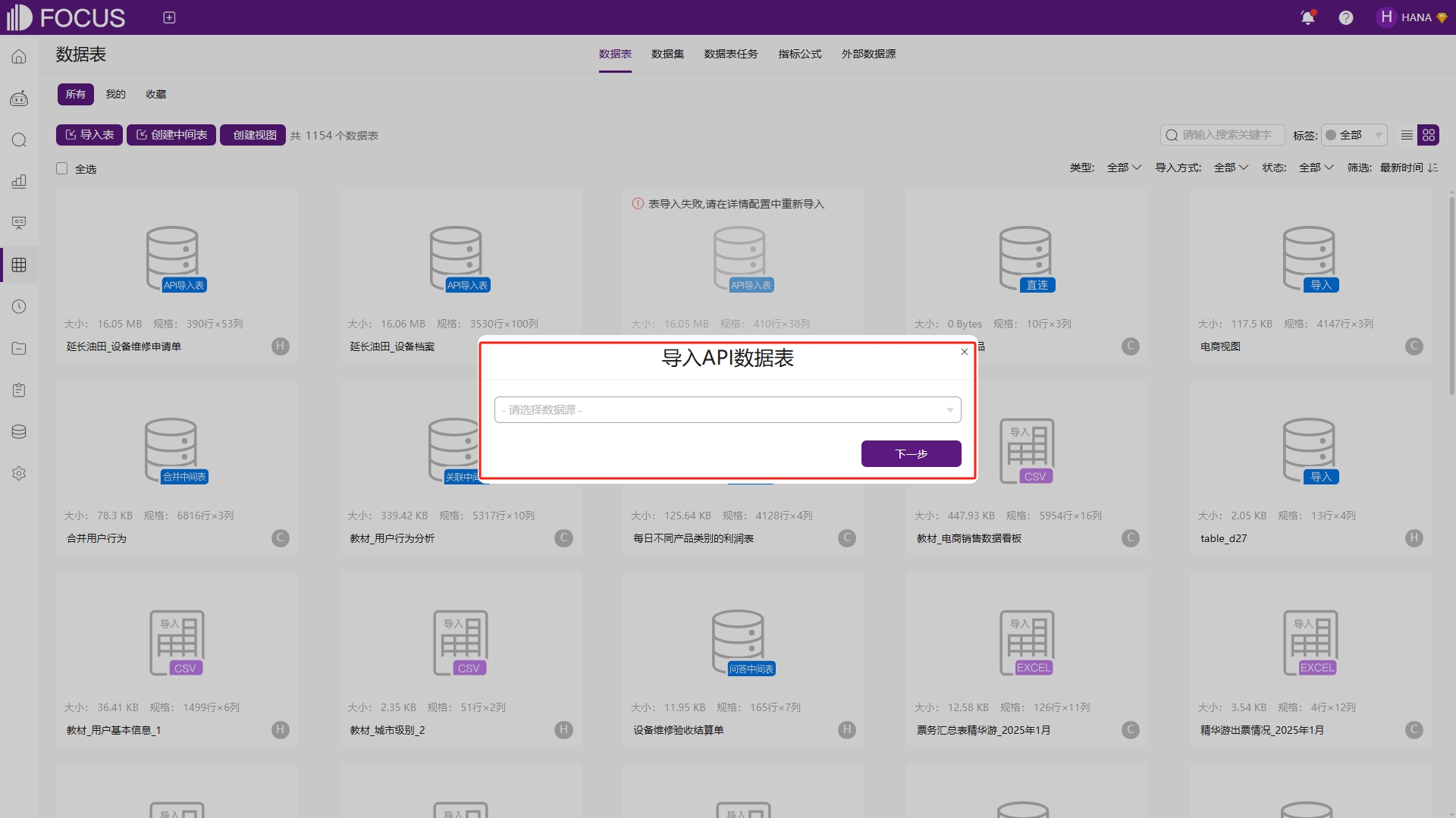
图6-8 从API导入表
选择数据源之后,点击下一步,选择需要从该数据源导入的表和数据列,如图6-9。
图6-9 选择API数据表
从HTTP导入表
点击左侧“数据管理”模块,然后点击左上方“导入表”按钮,点击“从HTTP导入表”,进入HTTP配置界面,如图6-10。用户可以配置基础的请求方式、设置URL、配置Params、Body请求体、Headers请求头、Cookies这些基础功能配置。认证方式Auth目前支持两种认证方式Basic Auth和Digest Auth。基础配置项中的键值对可以使用JavaScript变量动态赋值,只需要使用双中括号包括需要使用的变量,如,即可在基础配置中动态赋值变量。
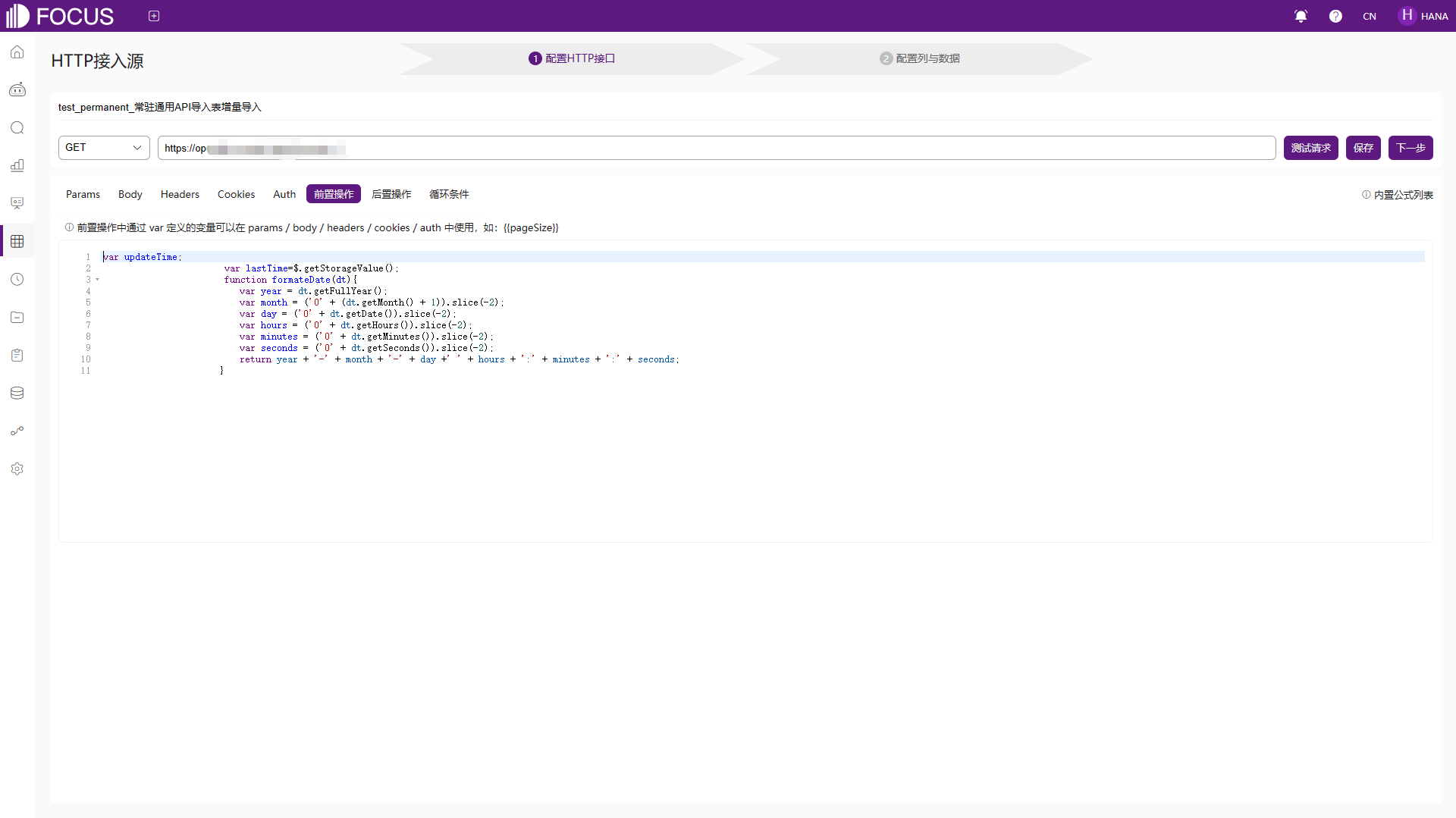
图6-10 配置HTTP接口
HTTP接口配置完成,下一步即可配置导入的列与数据,如图6-11。
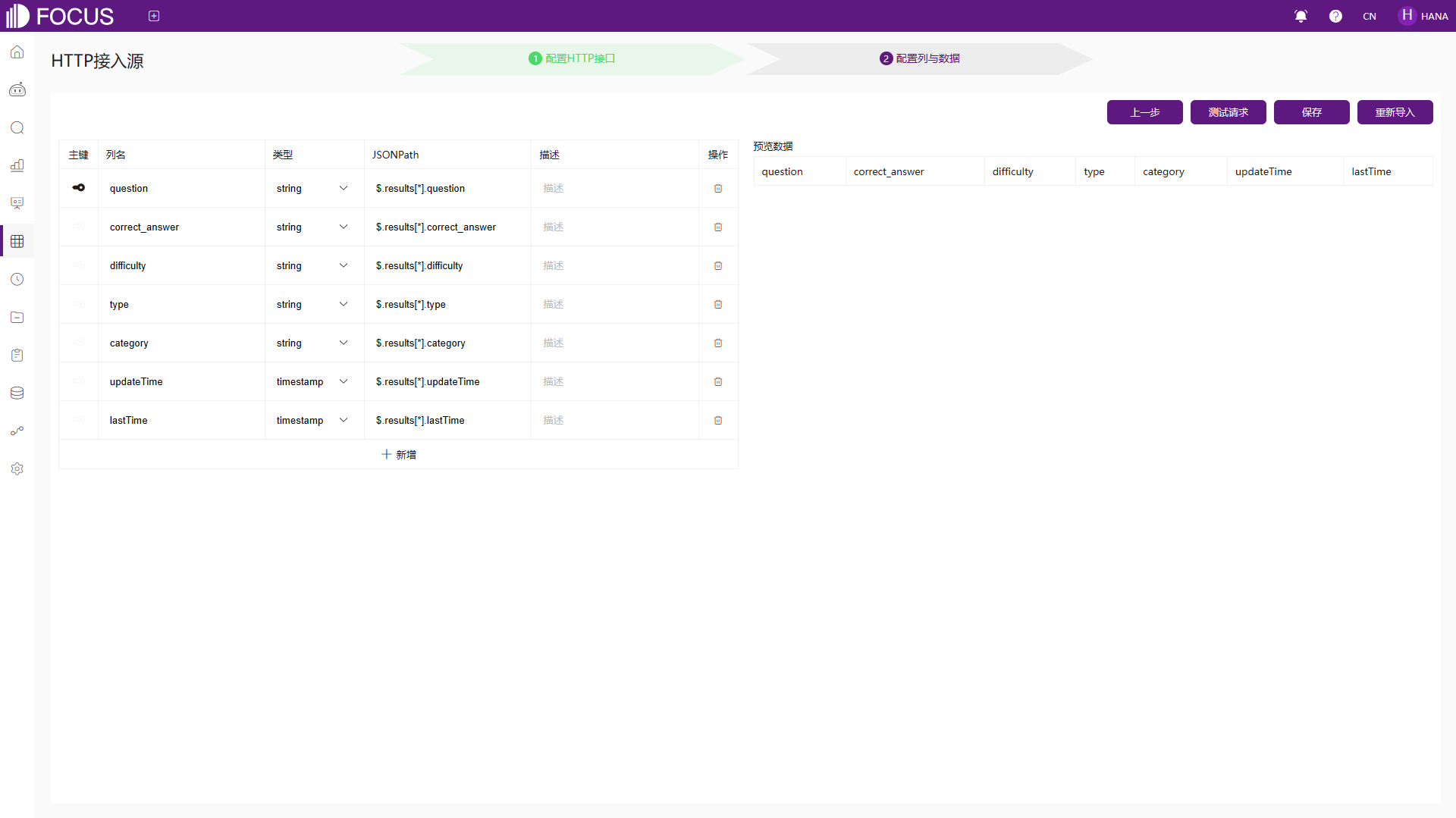
图6-11 配置列与数据
导出数据
若需要将数据导出本地,可在搜索界面,将查询结果导出为CSV文件或PDF文件,如图6-12。
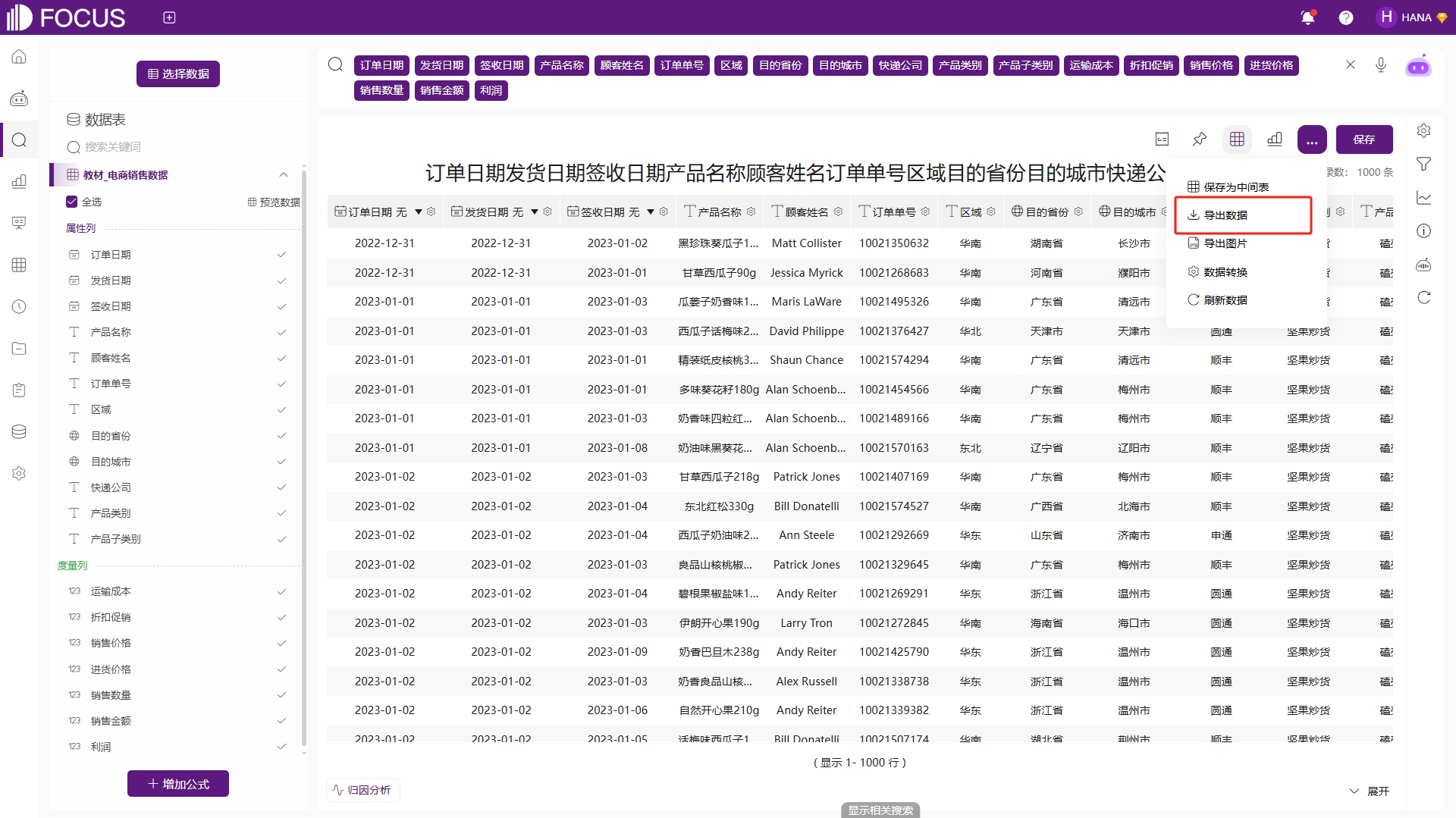
图6-12 导出数据
多表关联
在实际业务中,我们常常需要从多个不同的表里调取字段进行数据分析,所以跨表查询是非常重要的功能。
跨表查询的前提是所需表之间有相应的关联关系。DataFocus可以在数据表管理模块的表详情页中进行关联关系的建立,我们在数据表的关联关系页面,点击增加关联即可将当前表作为主表开始进行关联关系的配置。用户需要选择关联的维度表,并选择连接类型(内连接、左连接、右连接、全关联),最后确认两表之间的关联列(可多个)即可,如果有必要,也可以添加连接筛选条件进行筛选关联。当然,你可以对某张表创建多个关联关系,只要符合关联关系不闭环的条件即可,如图6-13所示。
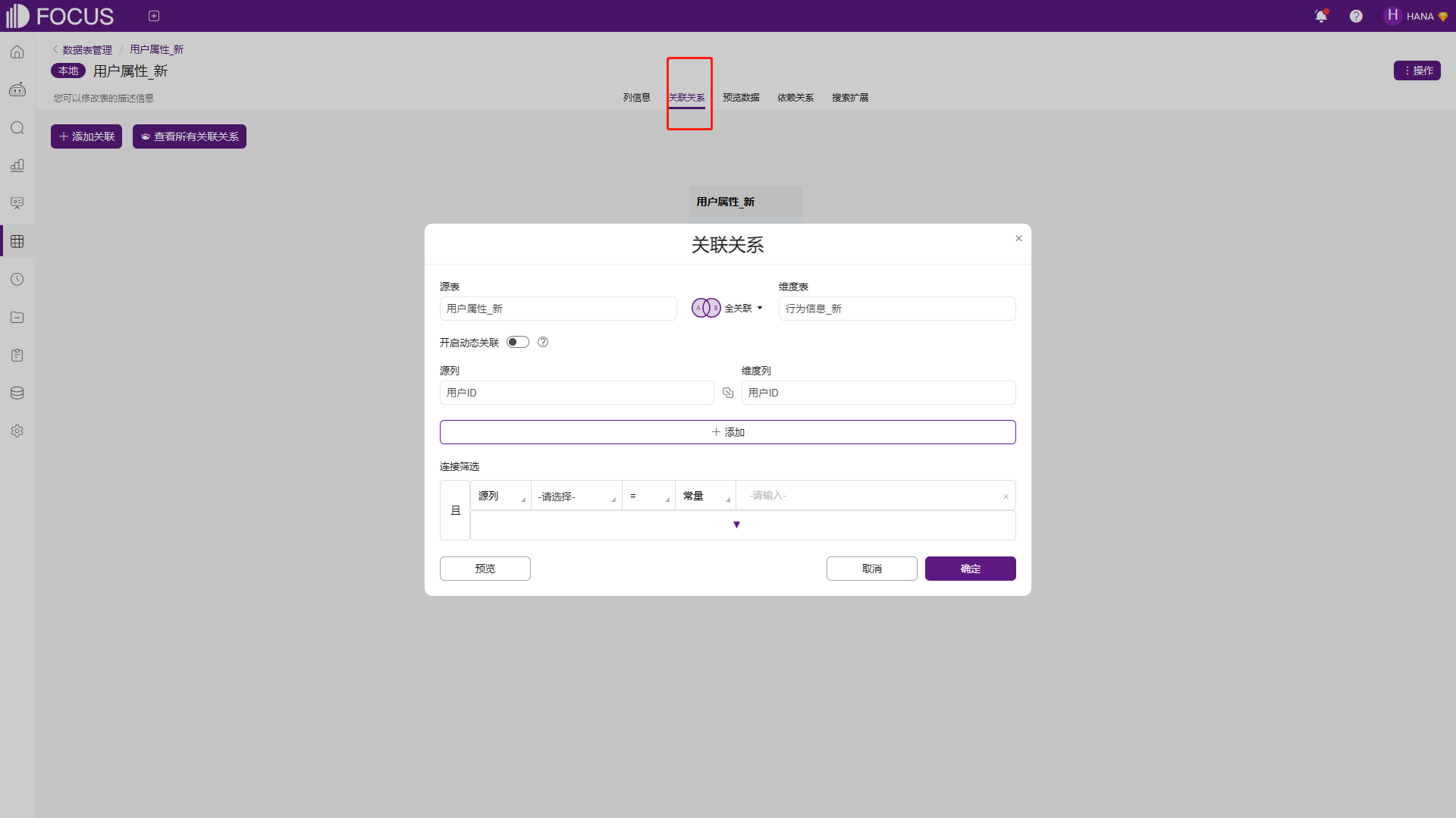
图6-13 关联关系配置页
其中四种关联关系,将以Student和Course示例数据表进行简单的讲解,如表6-1所示。内连接是最常见的连接类型,它返回两个表中满足连接条件的所有记录。换句话说,只有那些在两个表中都有匹配值的记录才会被返回。左连接返回左表中的所有记录,以及右表中与左表匹配的记录。如果左表中的某行在右表中没有匹配行,则结果集中该行右表的部分会包含空值(NULL),如表6-2所示。右连接与左连接相反,它返回右表中的所有记录,以及左表中与右表匹配的记录。如果右表中的某行在左表中没有匹配行,则结果集中该行左表的部分会包含空值(NULL)。全连接返回左表和右表中的所有记录,以及它们之间匹配的记录。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值(NULL),如表6-3所示。
表6-1 连接类型示例数据表
| Student | Course | |||
| ID | Name | ID | Cname | |
| 1 | 张三 | 1 | 足球 | |
| 2 | 李四 | 2 | 音乐 | |
| 3 | 王二 | 4 | 美术 |
表6-2 内连接和左关联
| 内连接 | 左连接 | |||||||
| ID | Name | ID | Cname | ID | Name | ID | Cname | |
| 1 | 张三 | 1 | 足球 | 1 | 张三 | 1 | 足球 | |
| 2 | 李四 | 2 | 音乐 | 2 | 李四 | 2 | 音乐 | |
| 3 | 王二 | NULL | NULL |
表6-3 右连接和全关联
| 右连接 | 全关联 | |||||||
| ID | Name | ID | Cname | ID | Name | ID | Cname | |
| 1 | 张三 | 1 | 足球 | 1 | 张三 | 1 | 足球 | |
| 2 | 李四 | 2 | 音乐 | 2 | 李四 | 2 | 音乐 | |
| NULL | NULL | 4 | 美术 | 3 | 王二 | NULL | NULL | |
| NULL | NULL | 4 | 美术 |
除此之外,系统还支持动态关联,适配更灵活的业务场景。动态关联是一种智能化的数据连接方式,通过动态适配分析需求调整关联规则,而非依赖固定的静态关联规则。其核心流程分为两步:预聚合处理以及动态维度匹配。如表6-4,接下来将使用这两张示例表对比展示动态关联和非动态关联的区别。
表6-4 动态关联示例表
| sales_data | order_data | |||||||
| ID | Province | City | Sales | ID | Province | City | Amount | |
| 1 | 上海 | 上海 | 100 | 1 | 上海 | 上海 | 50 | |
| 1 | 上海 | 上海 | 200 | 2 | 上海 | 上海 | 150 | |
| 4 | 浙江 | 杭州 | 300 | 4 | 浙江 | 杭州 | 200 | |
| 5 | 浙江 | 衢州 | 300 | 6 | 苏州 | 江苏 | 100 |
我们将两张示例表导入系统,进行动态关联关系的添加。和普通关联一样动态关联也需要选择源表和维度表,以及配置关联字段,关联字段设置为ID、Province、City,这两步是表间逻辑关系的基础,无论普通关联还是动态关联,都需要通过它们建立数据连接。然后单击“开启动态关联”按钮,如图6-14。
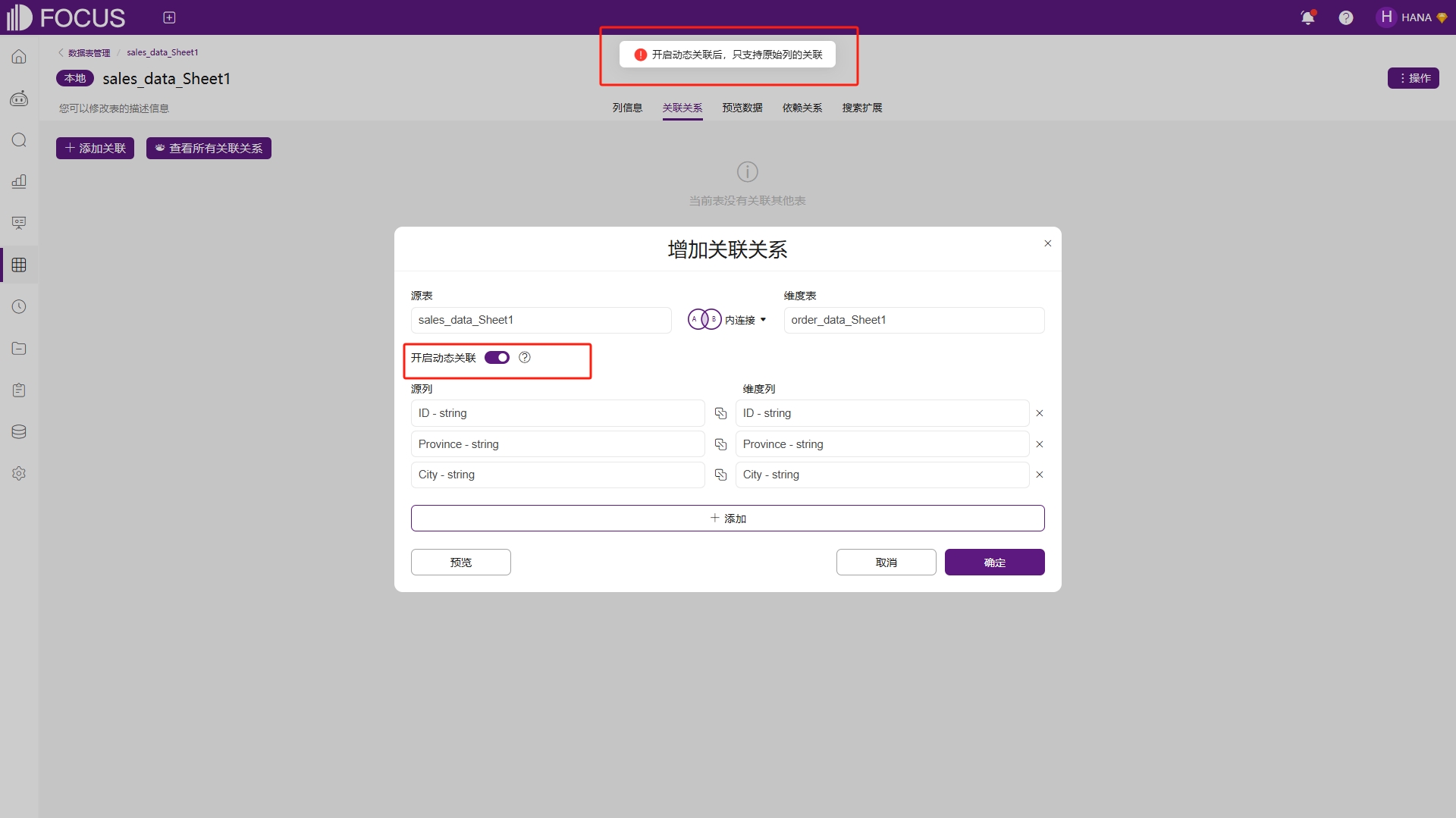
图6-14 开启动态关联
关联关系创建完毕并生效后,会在数据表的关联关系页面中显示相应的视图,如图6-15所示。将鼠标移至两表之间的连线上,可以激活关联关系的“详情”按钮,查看当前关联关系的详细内容。
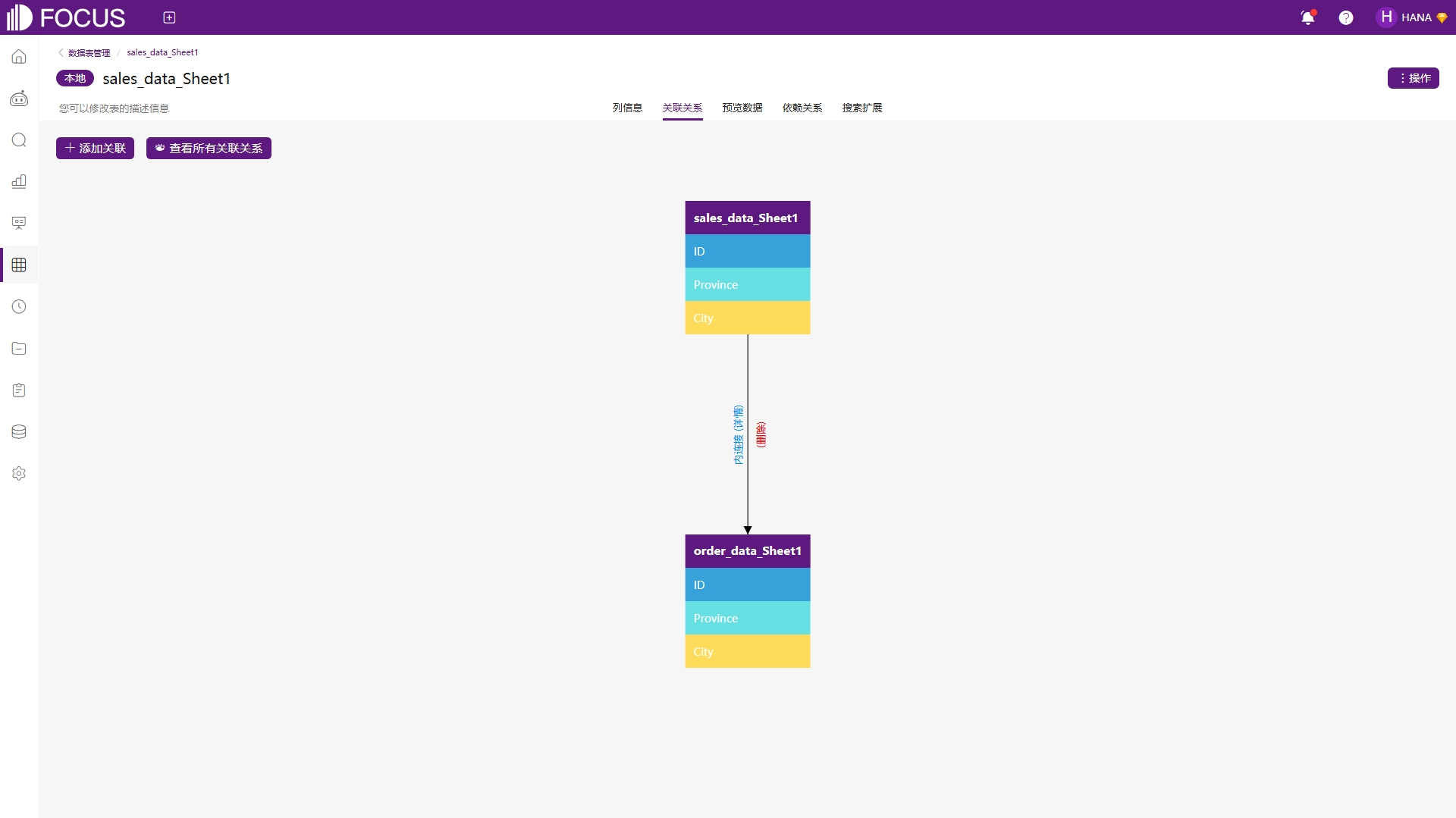
图6-15 关联关系视图
在成功根据分析需求构建多表间恰当的关联关系后,用户就能够在搜索界面或中间表页面中,利用这些已关联的表作为数据源,执行多表联合查询操作。此时,查询“Province Sales Amount”。查询结果为“上海 300 200、浙江 600 200”两条数据。同时我们可以通过右侧工具栏的“查询SQL语句”按钮来帮助理解动态关联表的查询过程,如图6-16。
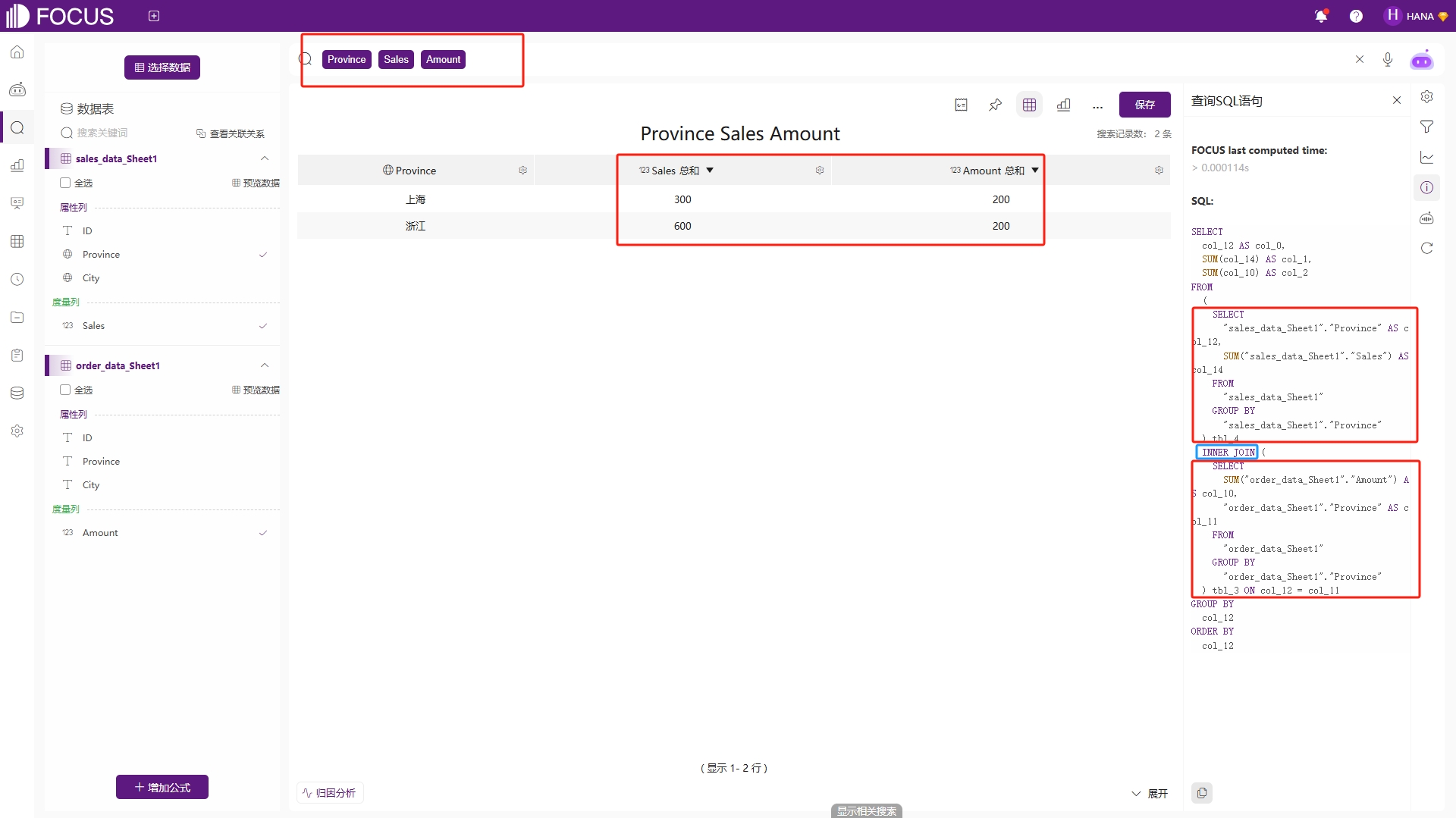
图6-16 动态关联查询
在处理该动态关联的查询时,各表先独立按查询维度聚合,即《sales_data》 按照Province Sales聚合,而《order_data》 按照Province Amount聚合,如表6-5。在聚合过程中,会忽略ID和City不同,《sales_data》聚合后得到两条数据,《order_data》聚合后得到三条数据。
表6-5 聚合过程示例
| sales_data | sales_data | ||||||
| ID | Province | City | Sales | Province | Sales | ||
| 1 | 上海 | 上海 | 100 | → | 聚合→ | 上海 | 300 |
| 1 | 上海 | 上海 | 200 | → | |||
| 4 | 浙江 | 杭州 | 300 | → | 聚合→ | 浙江 | 600 |
| 5 | 浙江 | 衢州 | 300 | → | |||
| order_data | order_data | ||||||
| ID | Province | City | Amount | Province | Amount | ||
| 1 | 上海 | 上海 | 50 | → | 聚合→ | 上海 | 200 |
| 2 | 上海 | 上海 | 150 | → | |||
| 4 | 浙江 | 杭州 | 200 | → | 聚合→ | 浙江 | 200 |
| 6 | 江苏 | 苏州 | 100 | → | 聚合→ | 江苏 | 100 |
然后将聚合后的数据进行关联,由于查询的是“Province Sales Amount”,因此关联时舍弃关联字段ID和City,仅按照关联字段Province进行关联。 由于“江苏 100”无匹配的数据被丢弃,最后得到了“上海 300 200、浙江 600 200”两条数据。由此可见,该动态关联示例在数据查询时,自动仅按Province聚合和关联,ID和City被丢弃,实现跨城市/ID的省级统计。
此时若关闭动态关联,其余保持不变,得到的结果是:查询时严格按照所有关联字段(如 ID+City+Province)进行行级精确匹配,任一关联字段未匹配的数据都将直接丢弃。匹配后的结果再按查询要求进行聚合(如Province Sales和Province Amount),如图6-17。它的结果数据为“上海 300 100、浙江 300 200”,与动态关联结果完全不同。
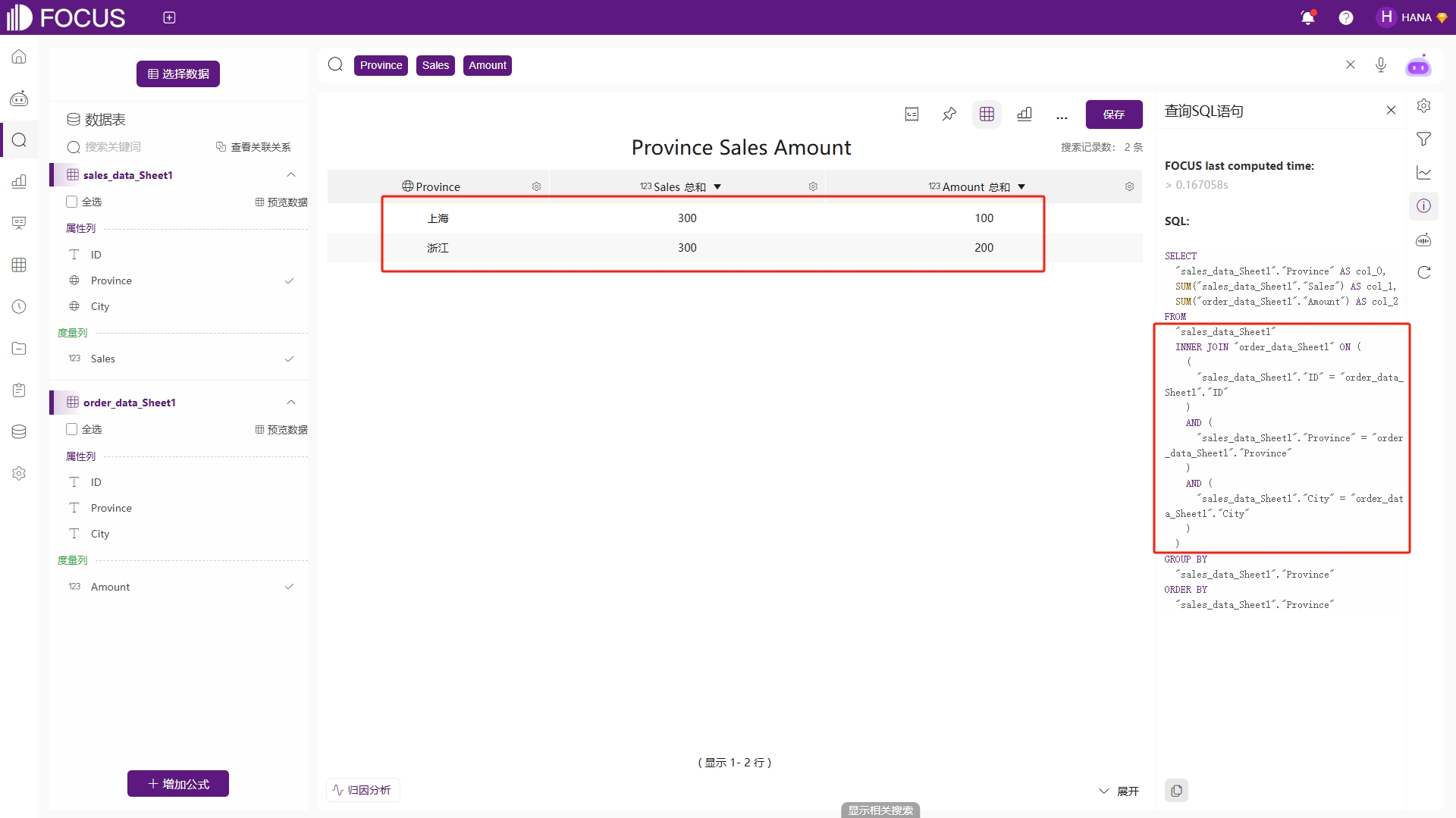
图6-17 非动态关联查询
总而言之,动态关联查询时各表先独立按查询维度聚合(如Province Sales和Province Amount),再根据查询需求自动筛选关联字段进行关联(如 province),确保维度数据完整性。动态关联与普通关联的选择取决于业务需求和数据特性。若分析目标需要精确追踪具体业务实体(如订单、用户),且关联字段(如ID、编码)在跨表中完全一致,应优先使用普通关联,通过严格的行级匹配确保数据准确性,典型场景包括订单详情对账或用户行为追踪。反之,若侧重宏观维度统计(如地区销售额对比),或关联字段可能存在不一致(如ID错位但地区等维度可信),则需选择动态关联,其通过先聚合维度指标再关联的方式,规避实体匹配问题,尤其适合海量数据下的性能优化。简单来说,实体级分析用普通关联,维度级统计用动态关联,当数据量大或字段可信度存疑时,动态关联在确保结果完整性和执行效率上更具优势。
数据集
数据集允许用户创建和管理若干个有关联或无关联的数据表,这些数据表可以来自不同的数据源,如本地导入、外部数据源导入、API导入等,通过数据集功能,用户可以轻松地将特定主题的数据表整合在一起,形成一个统一的数据视图。数据集的意义在于,它为用户提供了一个按主题集中、有序管理数据的环境。在这个环境中,用户可以方便地查看、编辑、分析数据,从而更高效地利用数据资源。
在数据表模块的数据集页签,点击“创建数据集”,如图6-18。
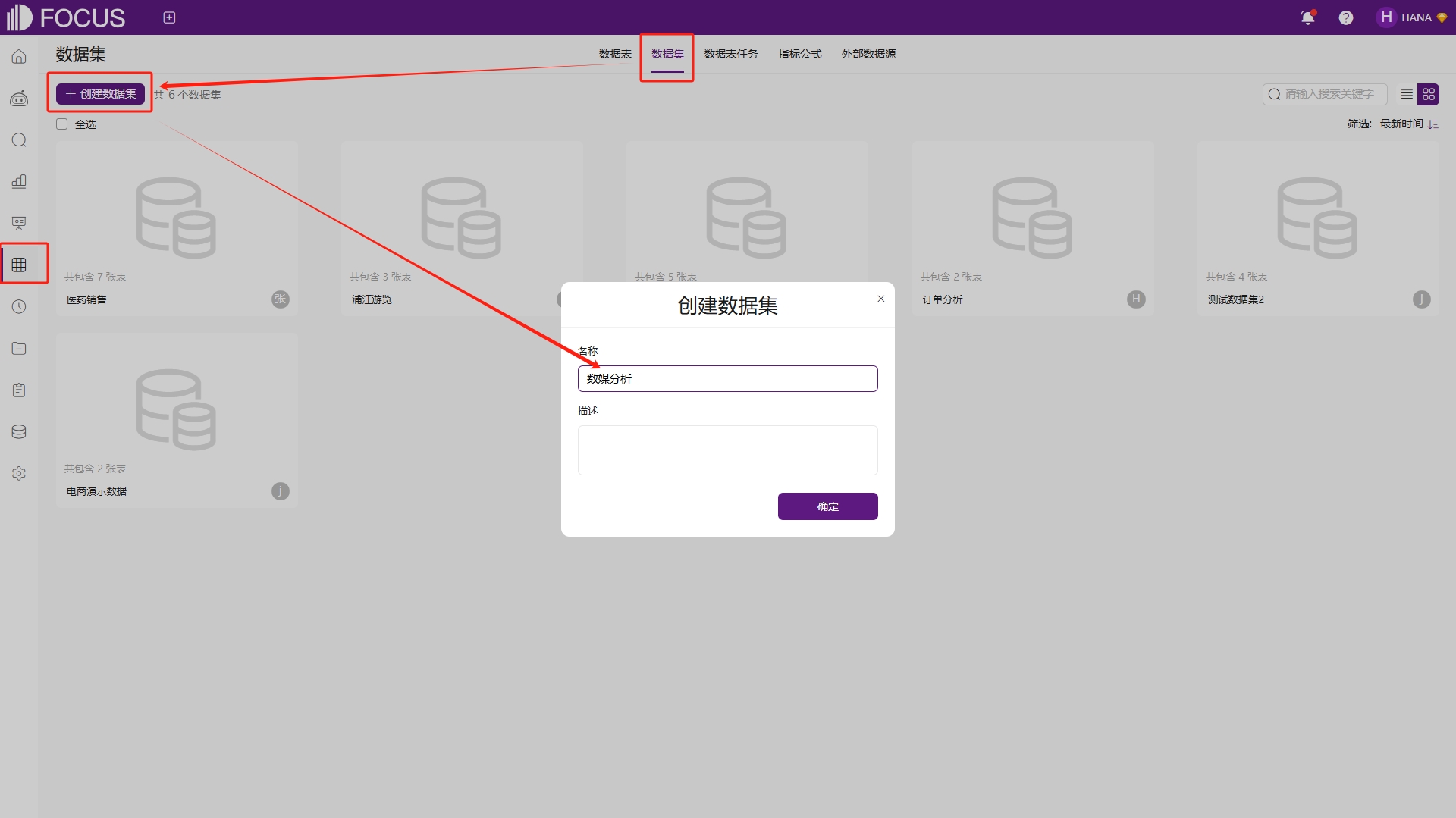
图6-18创建数据集
数据集创建后即可导入数据表,点击左上角的“导入数据表”按钮,可选择已导入系统的数据表加入到数据集中,如图6-19。
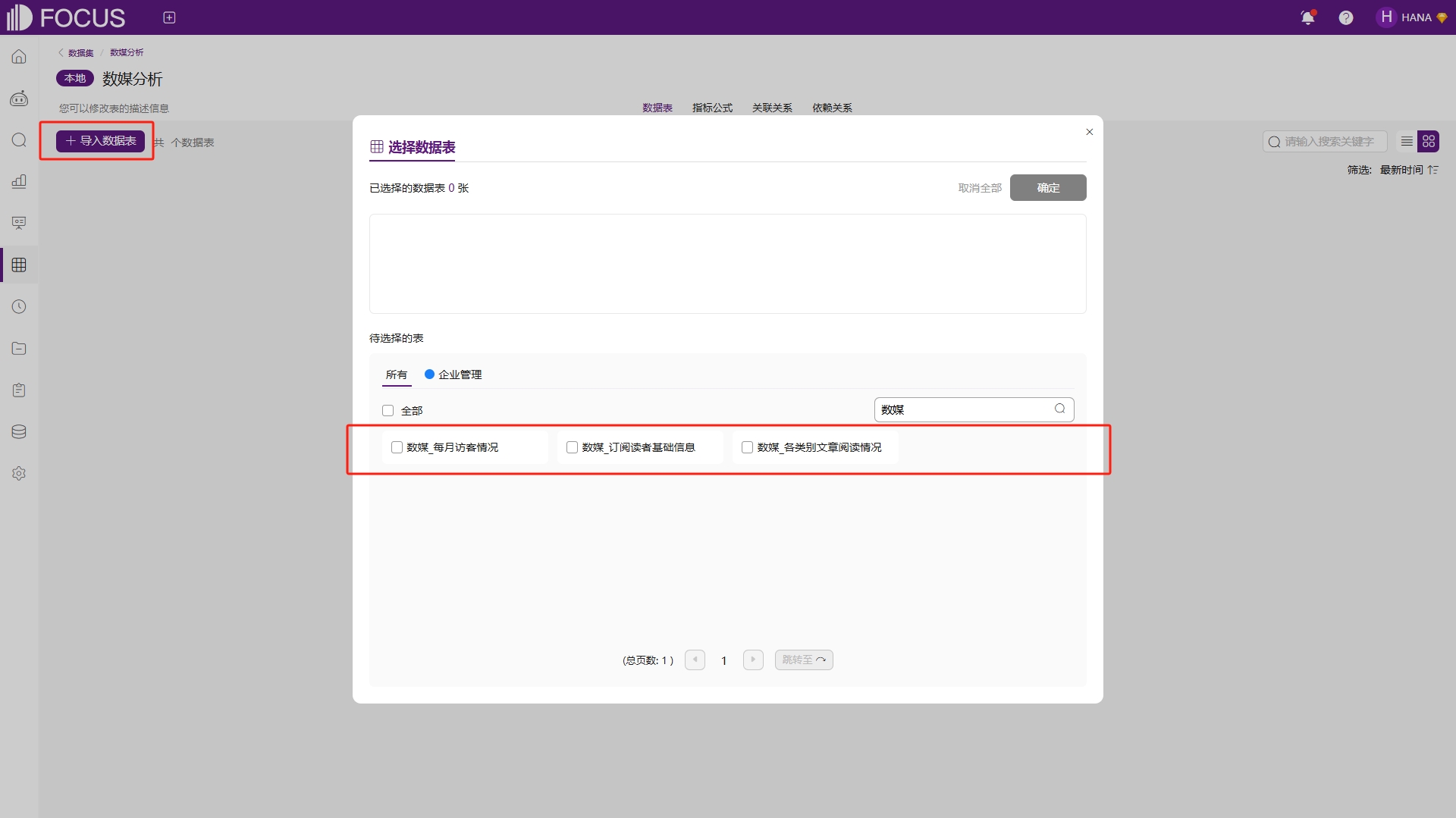
图6-19 数据集导入数据表
导入数据集的数据表可以是若干个相关联或无关联的数据表,若是已创建关联关系的数据表,将会高亮显示,例如导入关联数据表《教材_商品信息》和《教材_订单信息》,如图6-20。
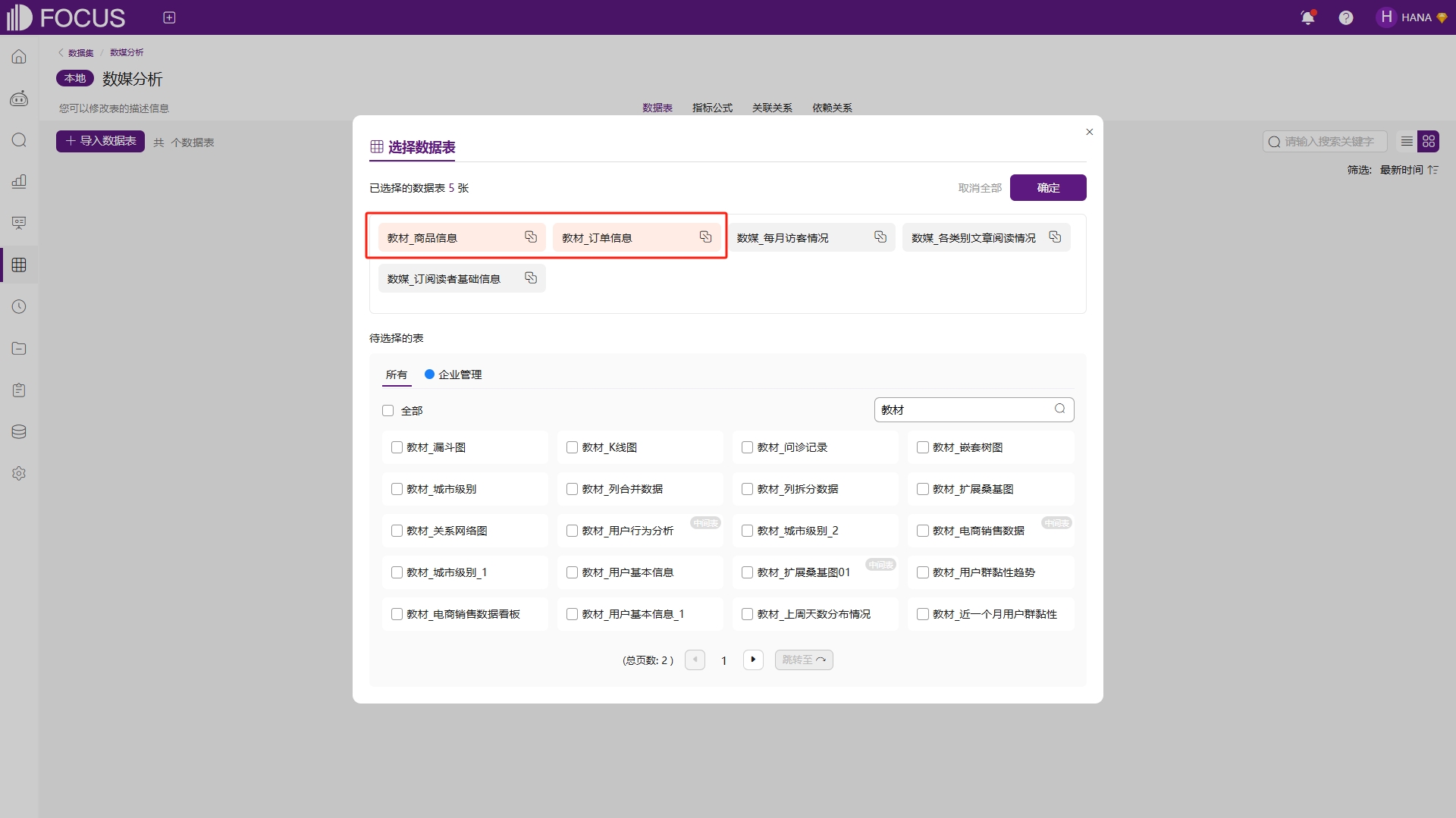
图6-20 选择关联数据表
在数据集中,用户可以定义数据表之间的关联关系。注意,若数据表已存在关联关系,则数据集会继承数据表的关联关系,如图6-21。
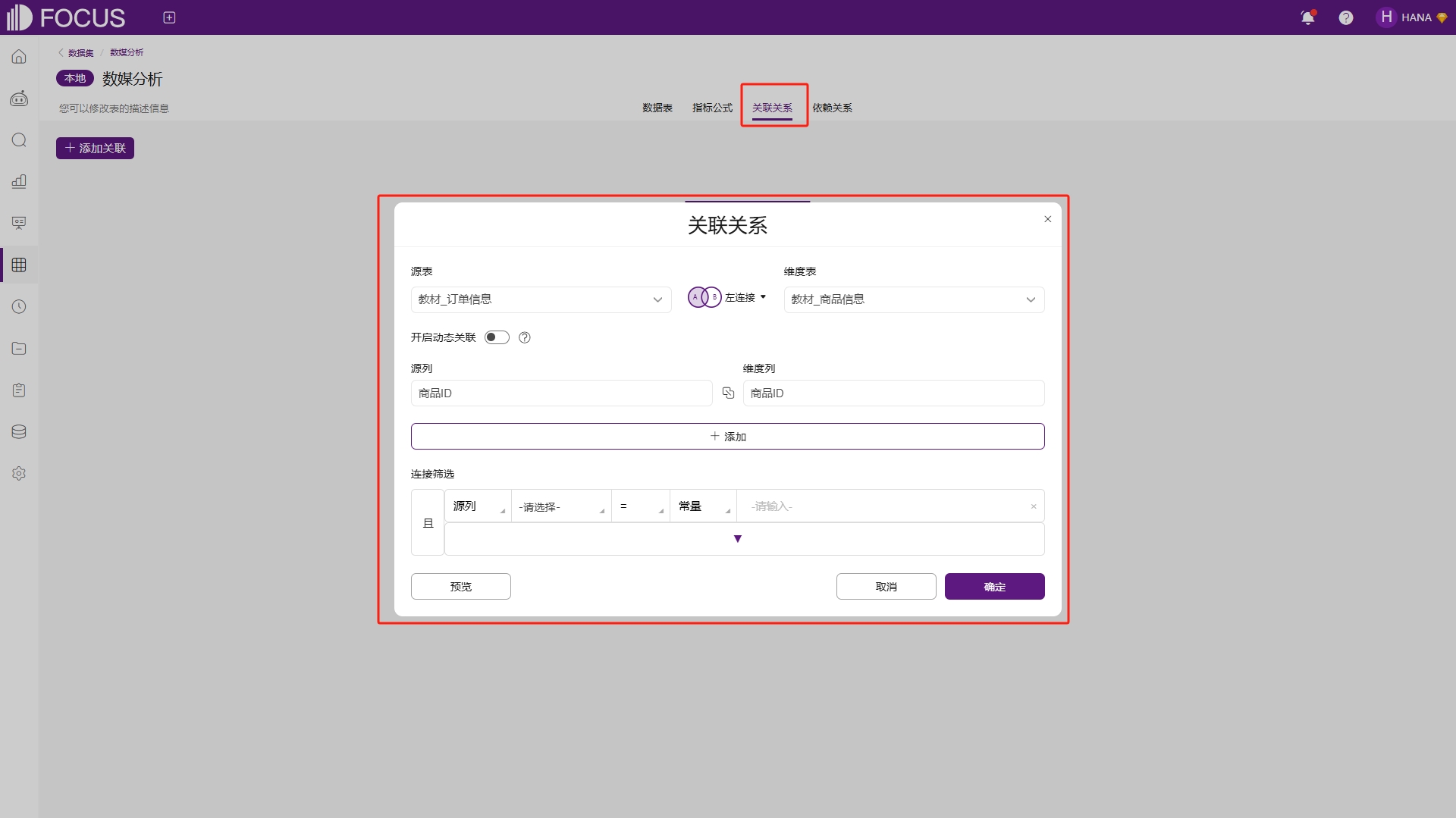
图6-21 继承数据表的关联关系
用户也可以在数据集中独立管理导入表的关联关系,点击“添加关联”按钮,即可为数据集中的数据表增加关联关系,源表和维度表的选择仅限于数据集中的数据表,如图6-22。
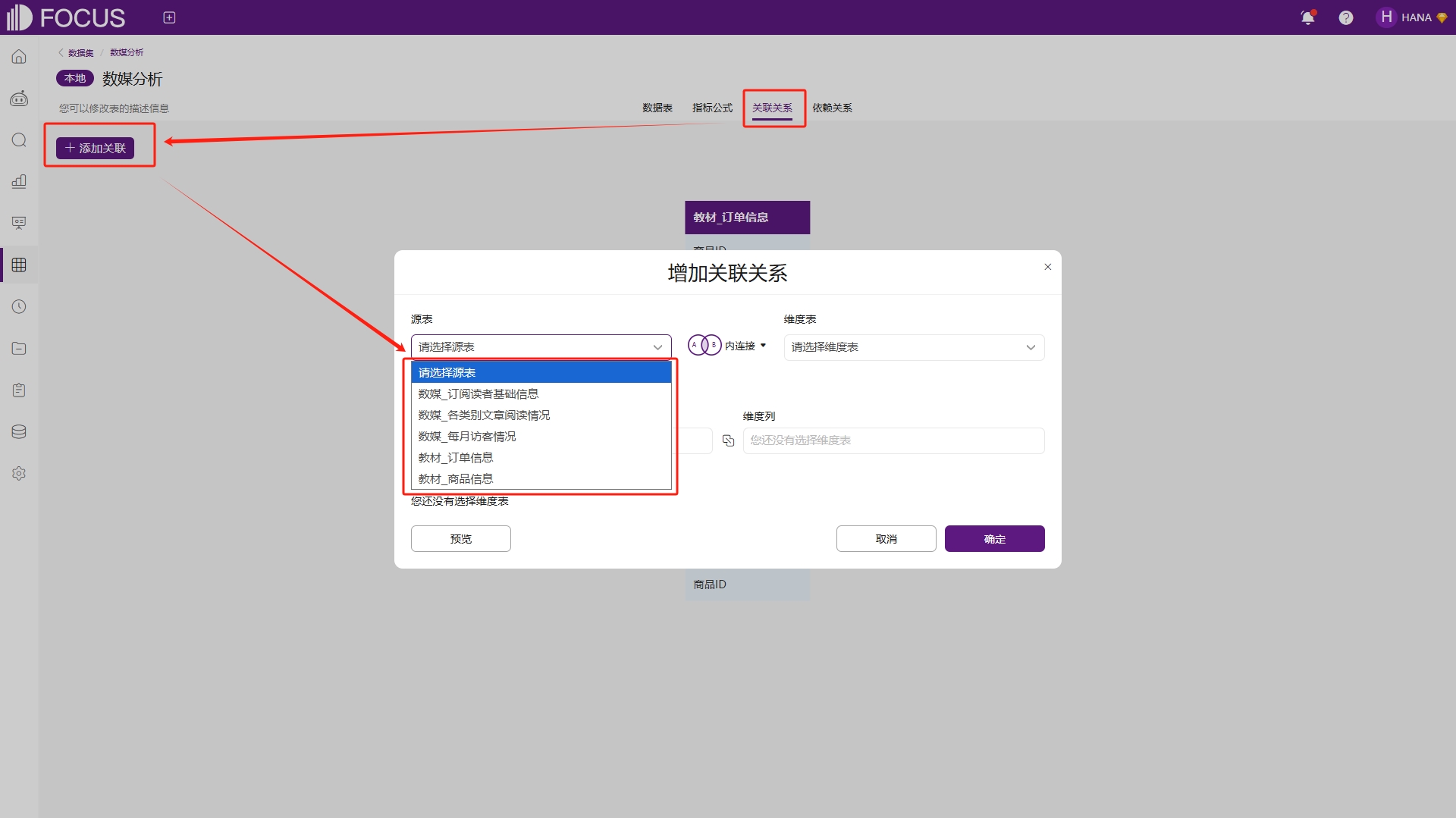
图6-22 数据集添加关联关系
若干个数据表一旦被添加到同一个数据集中,用户就可以将它们视为一个整体来进行搜索和分析。在搜索界面,点击“选择数据”按钮,然后点击“选择数据集”,选中创建的“数媒”分析数据集。选中数据集后,该数据集中的所有数据表将会显示在左侧,如图6-23。这种方式极大地简化了数据处理的流程,使得用户无需在来回切换选择数据,即可获取到所需的数据。
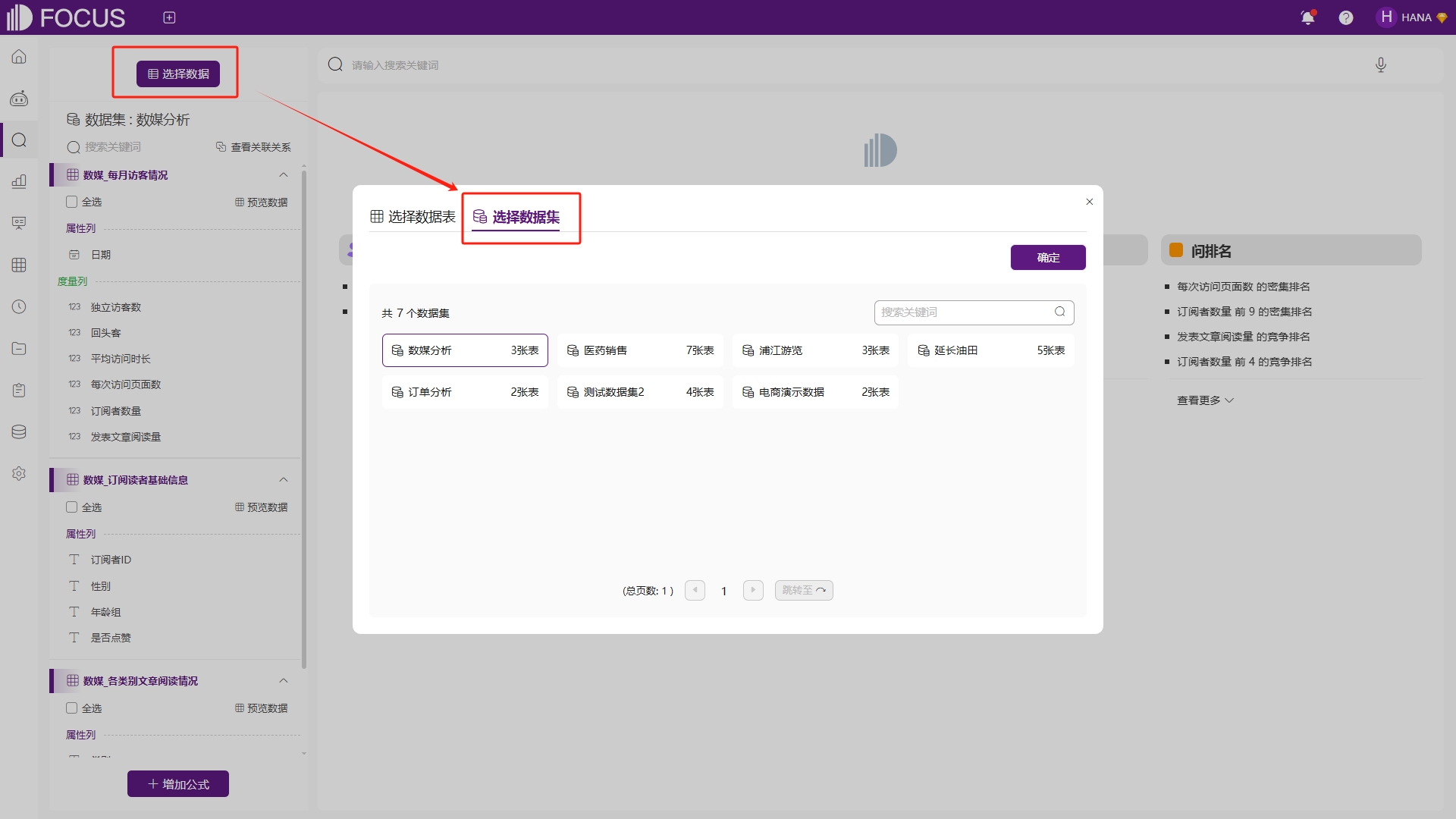
图6-23 选择数据集
但是请注意,虽然数据集允许导入不存在关联关系的数据表,但是无关联关系的数据表之间不能进行联合分析,如图6-24。
图6-24 无关联关系数据表不能联合分析
如果此时用户发现需要重新维护数据集的关联关系,无需返回数据集页面,在搜索页面就可以查看、修改及添加数据集的关联关系,如图6-25。
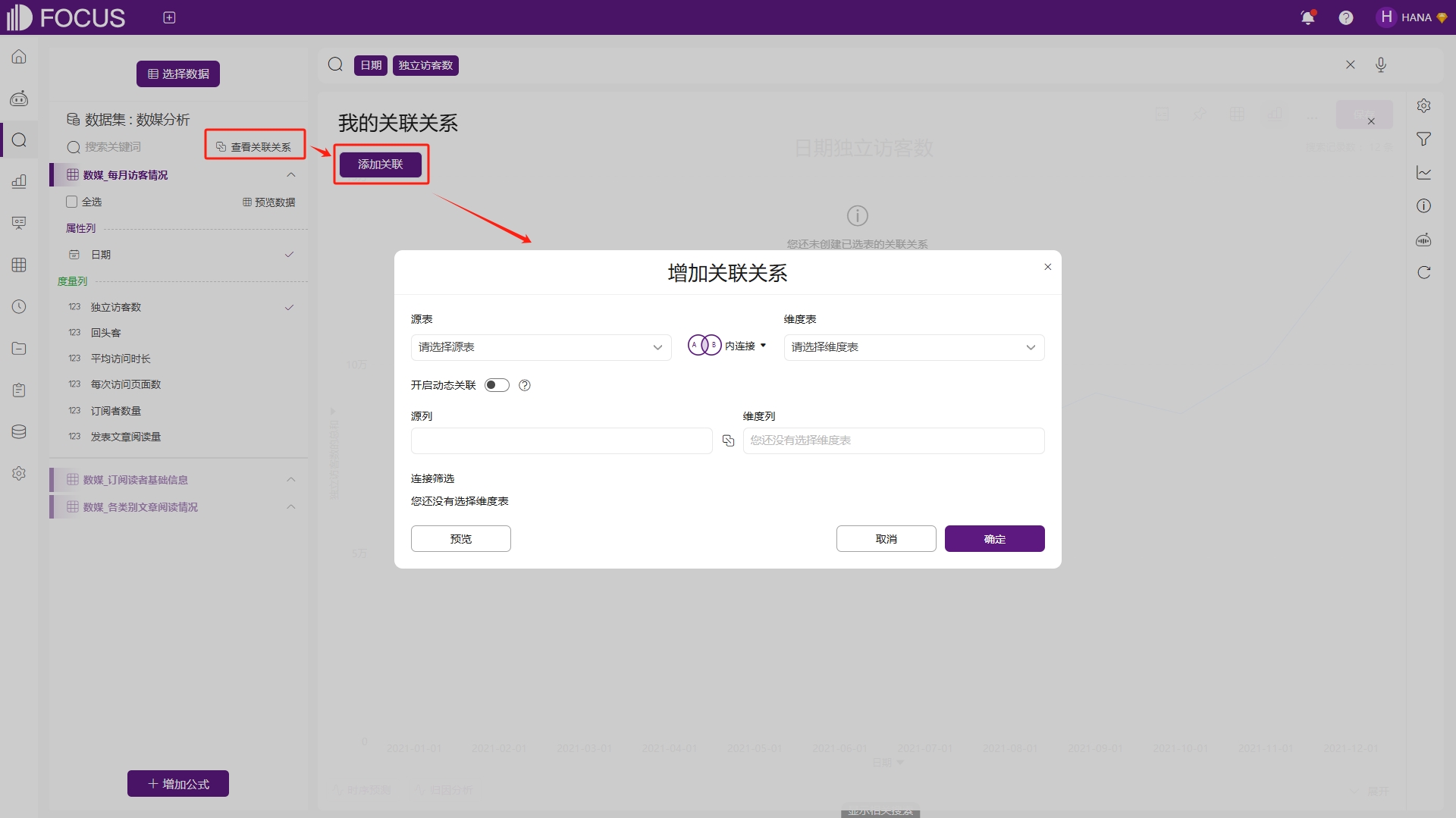
图6-25 搜索界面添加关联关系
数据表详情
将鼠标移至任一具体的数据表,点击“详情”可以进入数据表的详情页面。表格标题名称、表格描述、列名和列描述都可以在当前页面直接点击修改,如图6-27所示。
图 6-26详情按钮
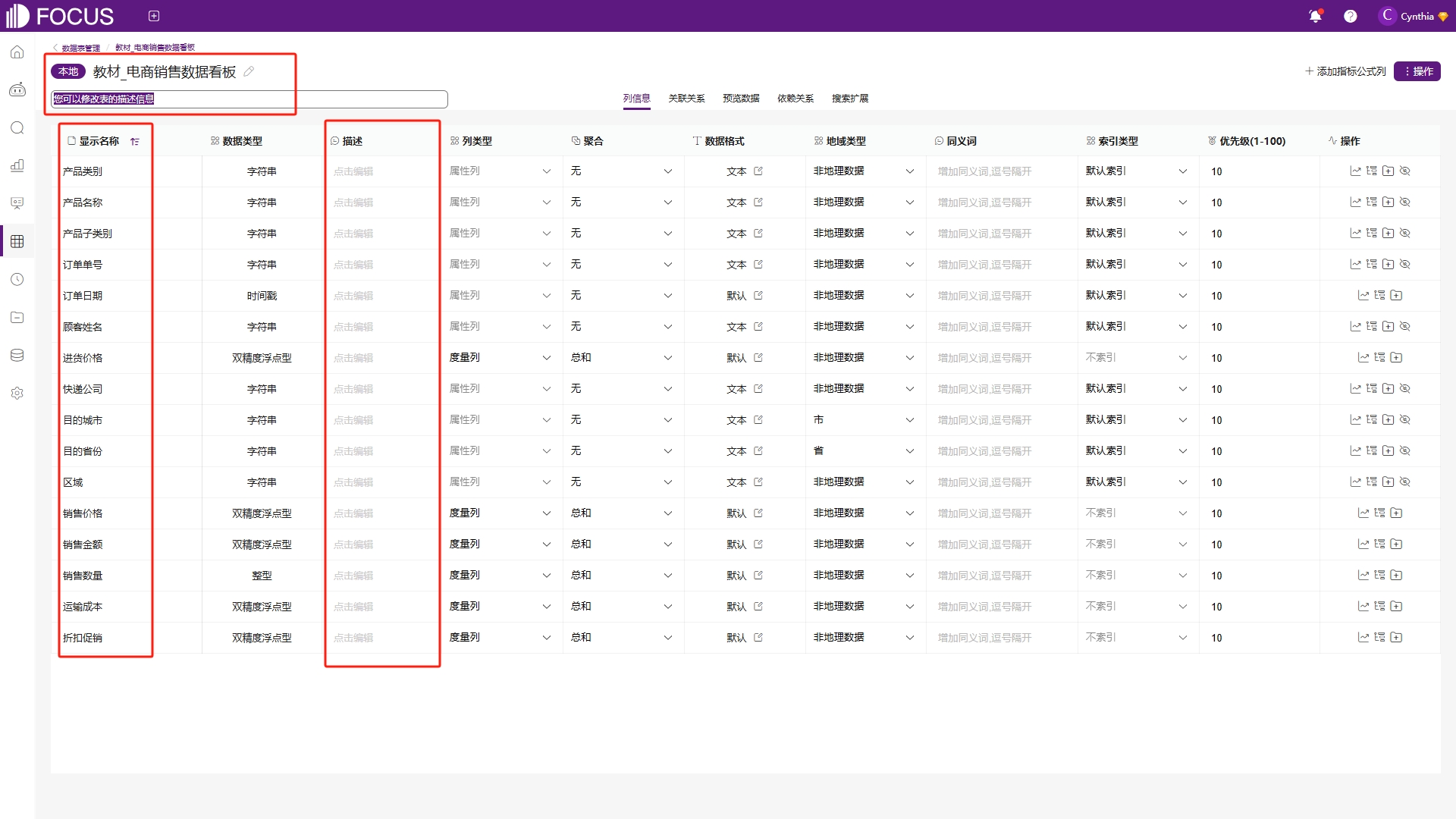
图6-27 修改表名和描述信息
1. 列信息
在列信息中可以看到该表中每列的具体情况,包括显示名称、数据类型、描述、列类型、聚合、数据格式、地域类型、同义词、索引类型、优先级和操作,如所示。
●显示名称:该列在搜索模块中的显示名称。
●数据类型:列的数据类型,在导入时配置固定,不可修改。
●描述:对列字段的描述,可以根据自身需求添加。
●列类型:列类型分为属性列和度量列两种,属性列一般作为X轴和图例使用,度量列作为Y轴使用。只有度量列可以修改为属性列使用。
●聚合:列的默认聚合方式,只有度量列有。聚合方式有总和、最小值、最大值、平均值、标准差、方差、总数、去重总数八种聚合方式,一般默认为总和,也可以选择不进行聚合。用户可以在数据表列信息中进行修改,同样也可以在进行搜索时利用设置和关键词临时修改。
●数据格式:当前列的显示格式,区分文本类、数值类和时间类。文本类可显示为文本、图片和链接地址;数值类可修改格式,显示为数字、货币、百分比、财务等,如图6-28;时间类可修改日期格式,如图6-29。
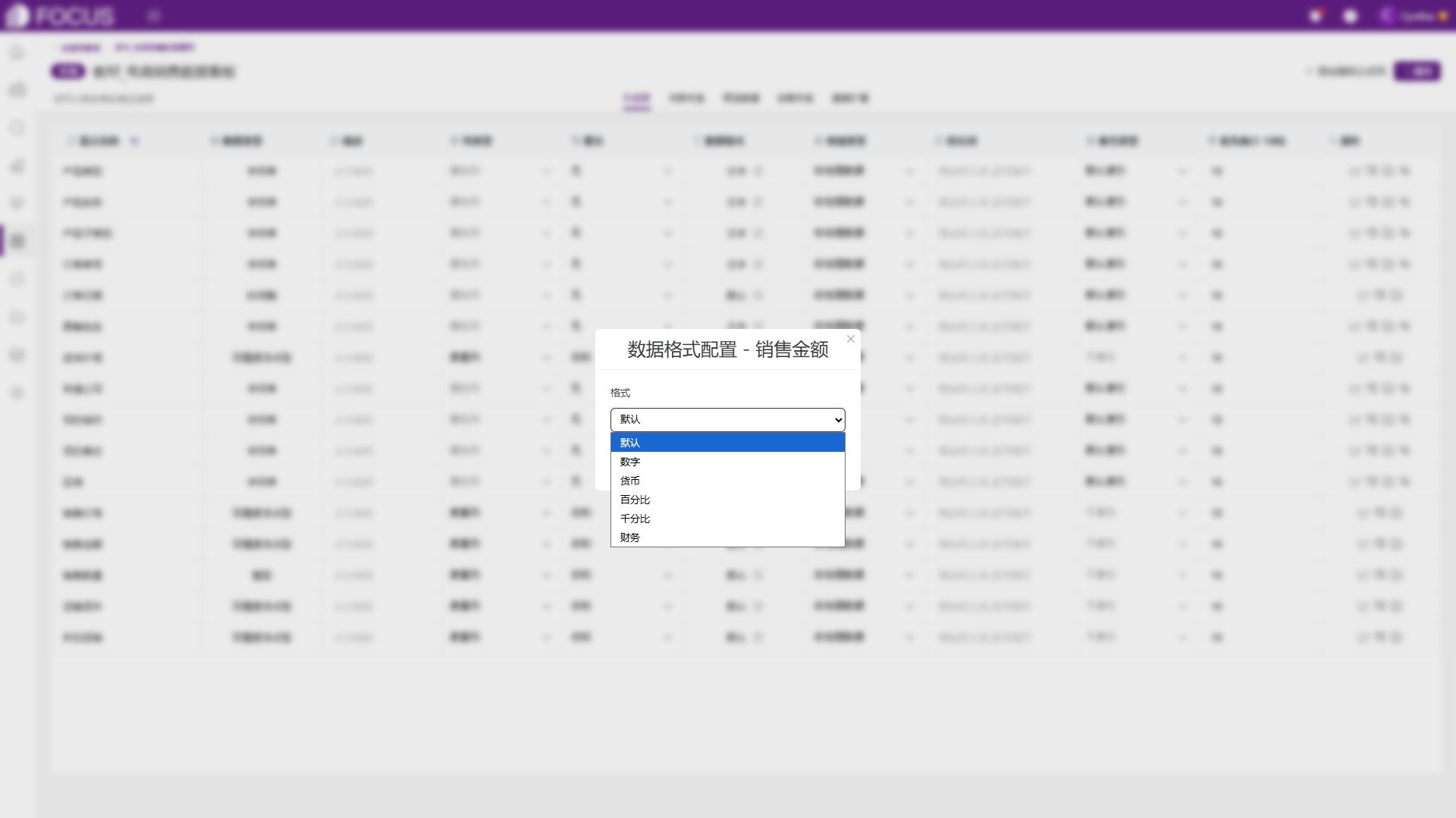
图6-28 修改数值数据格式
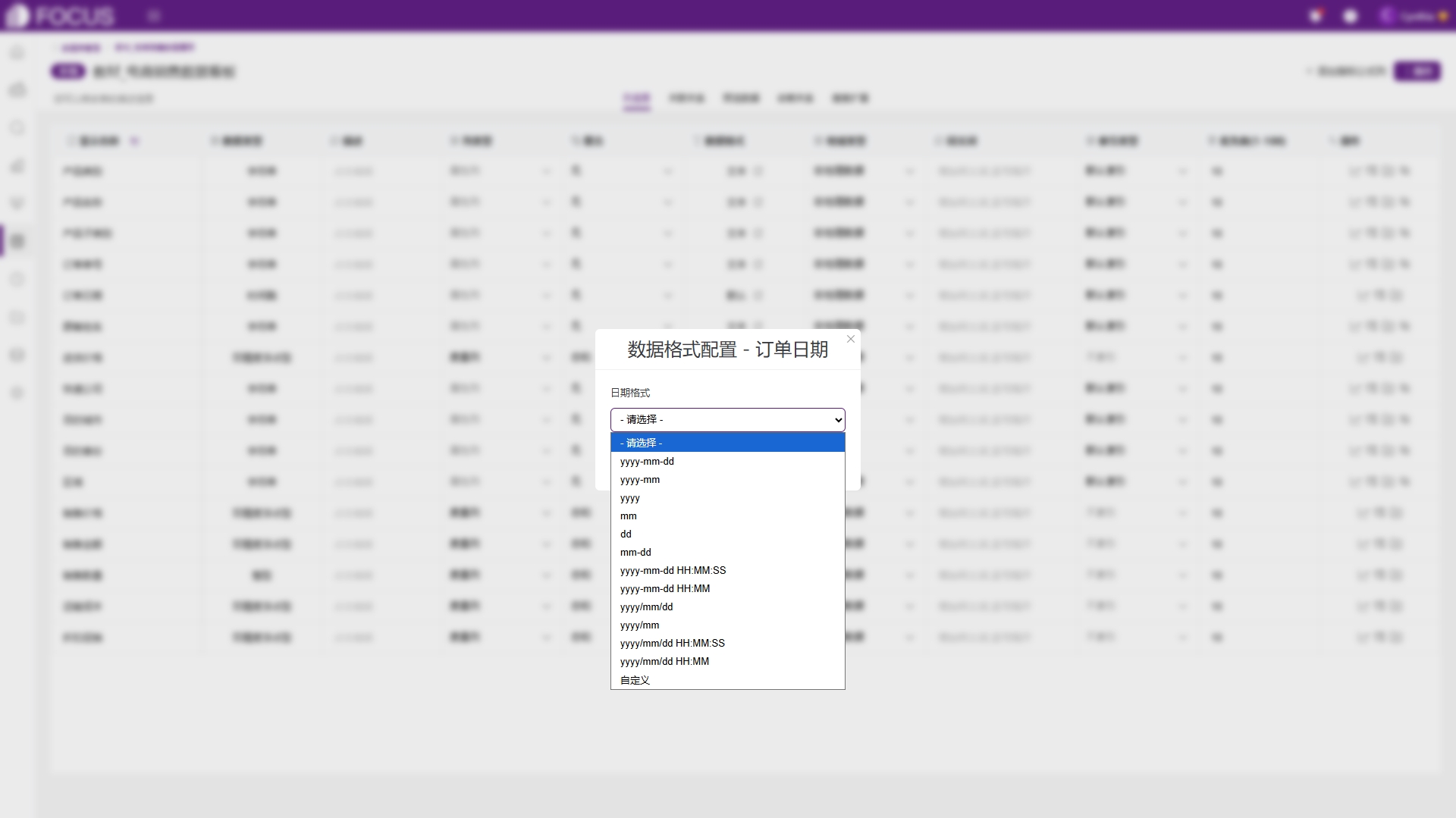
图6-29 修改时间数据格式
●地域类型:配置地理列,属性列可将对应的列配置为国家集合、国家、省集合、省、市集合、市等,度量列可将对应的地域类型配置为经度、维度。要求列符合为地理列的格式与值。
●同义词:列的同义名称,可以在搜索中作为列显示名称的代用,效果和显示名称一致。
●索引类型:选择该列建模方式。属性列默认参与索引,度量列默认不索引且无法修改。
●优先级:当搜索框内输入一个过滤条件时,返回结果会出现聚合后的数值列,优先级越高,则优先显示数值列结果,优先级100为最高。
●操作:数据表的一些其他操作。属性列有四个操作,分别是数据概况、血缘关系、创建分组公式和掩码,度量列则只有前3个,不具备掩码操作。
将鼠标移至属性列的数据概况,可以查看当前属性列去重后的总数、空值数量、数据完整度以及数据重复率,如图6-30;移至度量列,则同样可以查看当前度量列的基础数据,包括最小值、最大值、均值、方差等,如图6-31,并且可以对当前度量的数据分布进行预览。通过查看数据预览界面呈现的统计特征与非空值校验等,可快速建立对数据集维度结构、变量类型及数值范围的立体化认知,为后续分析提供可靠的依据。
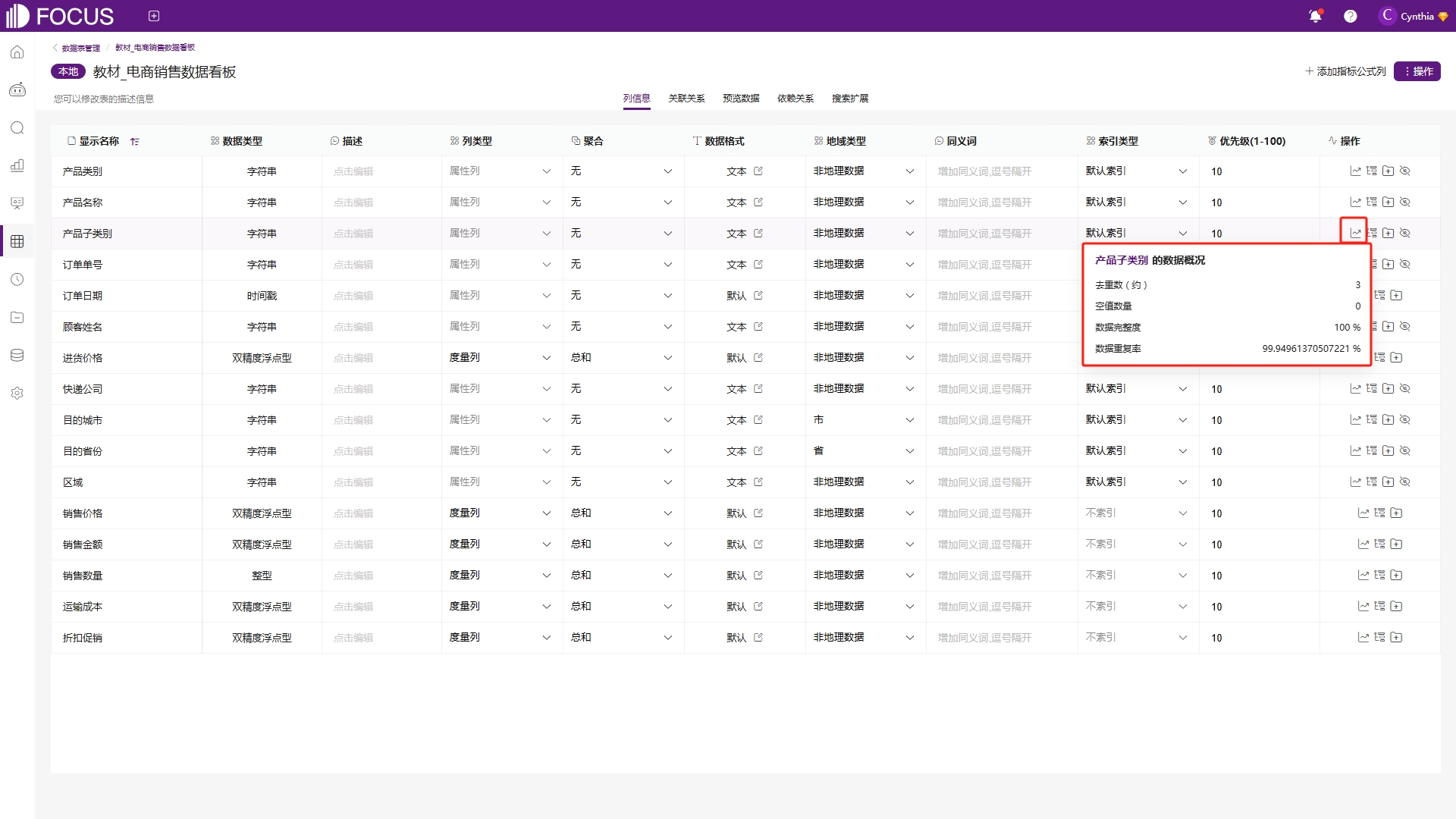
图6-30 属性列数据概况
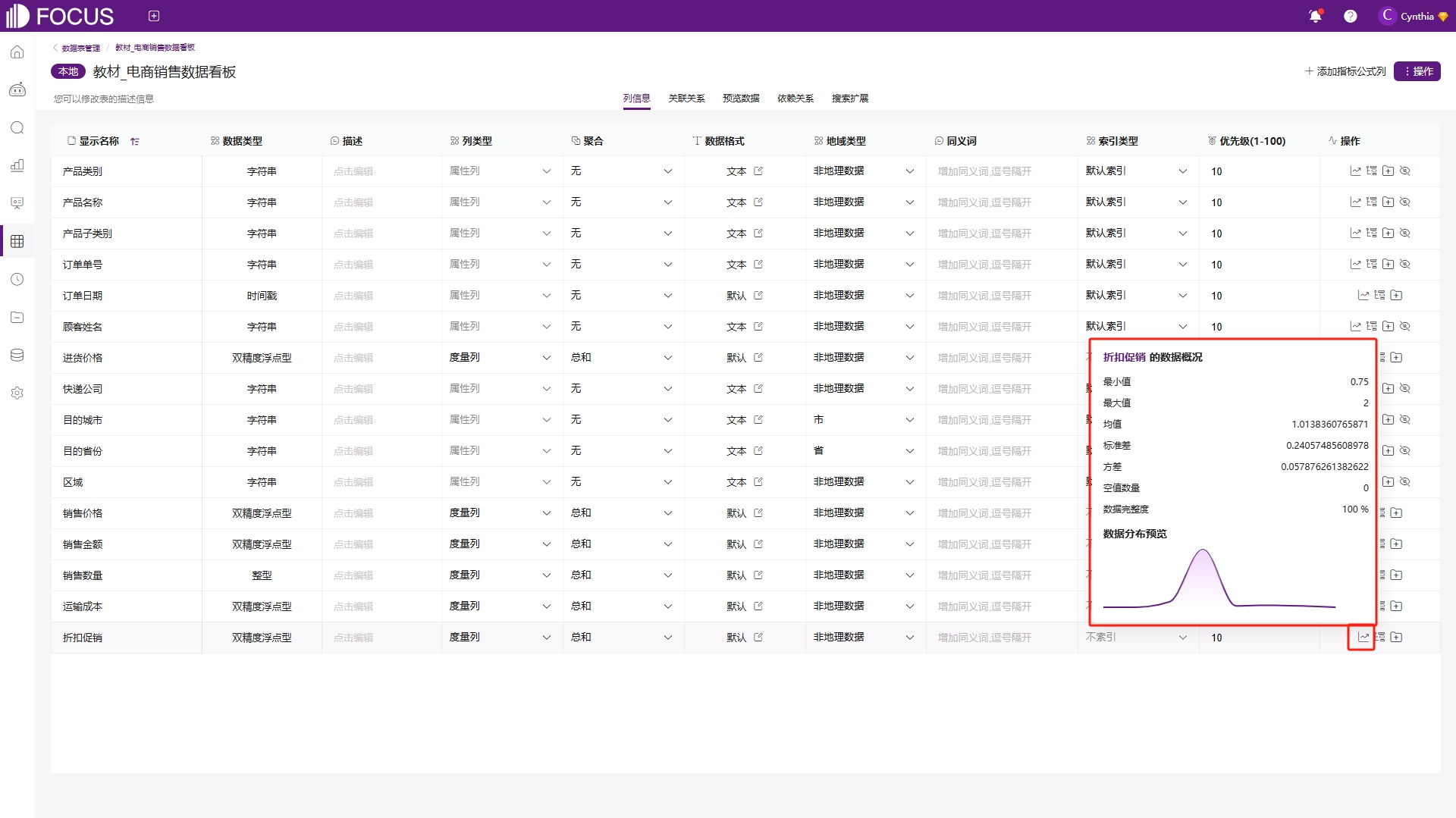
图6-31 度量列数据概况
通过血缘关系图可以查看数据从哪里来,一般是公式列才需要查看血缘关系,如图6-32。
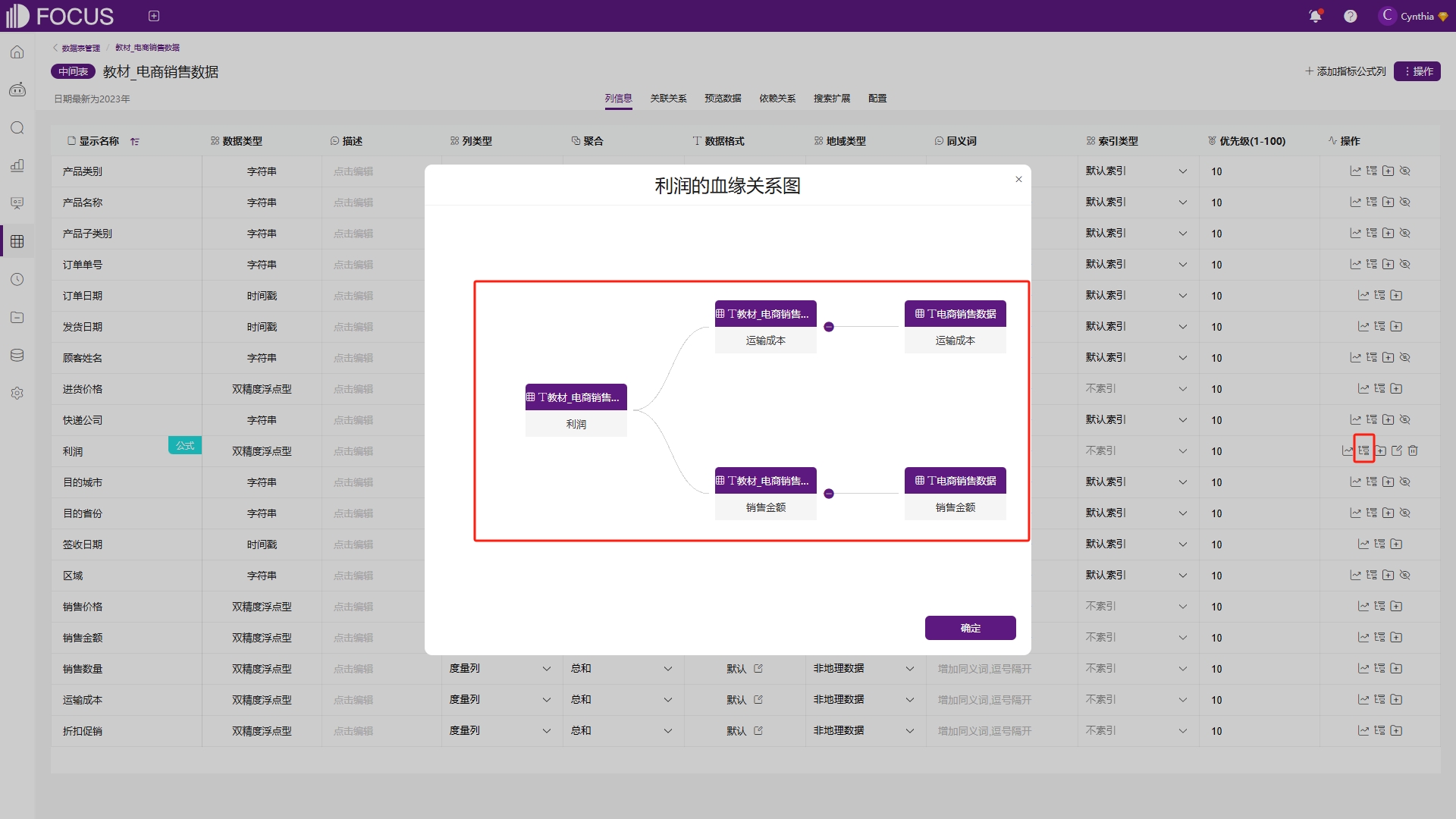
图6-32 血缘关系
通过创建分组公式可以勾选当前列中多个列中值然后点击分组,并为分组后的数据修改一个组名,这个组名会成为新列的列中值,通过点击“查看分组列中值”了解当前数据列下的列中值情况,如图6-33。
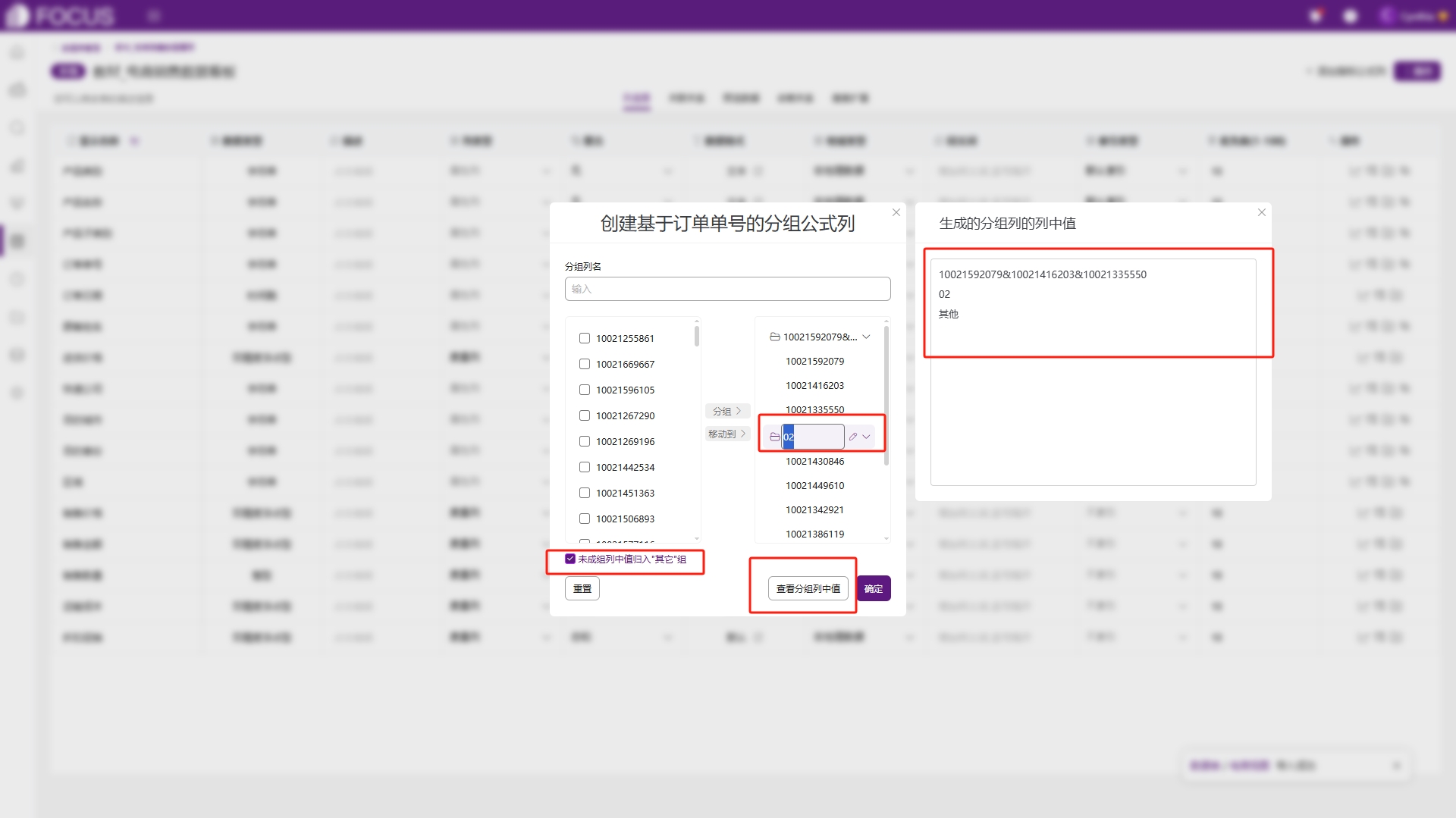
图6-33 创建分组
掩码功能主要是针对一些比较隐私的信息,例如身份证号、电话号码、姓名等,可以通过掩码掩其中部分字符,提高数据的安全性,如图6-34。
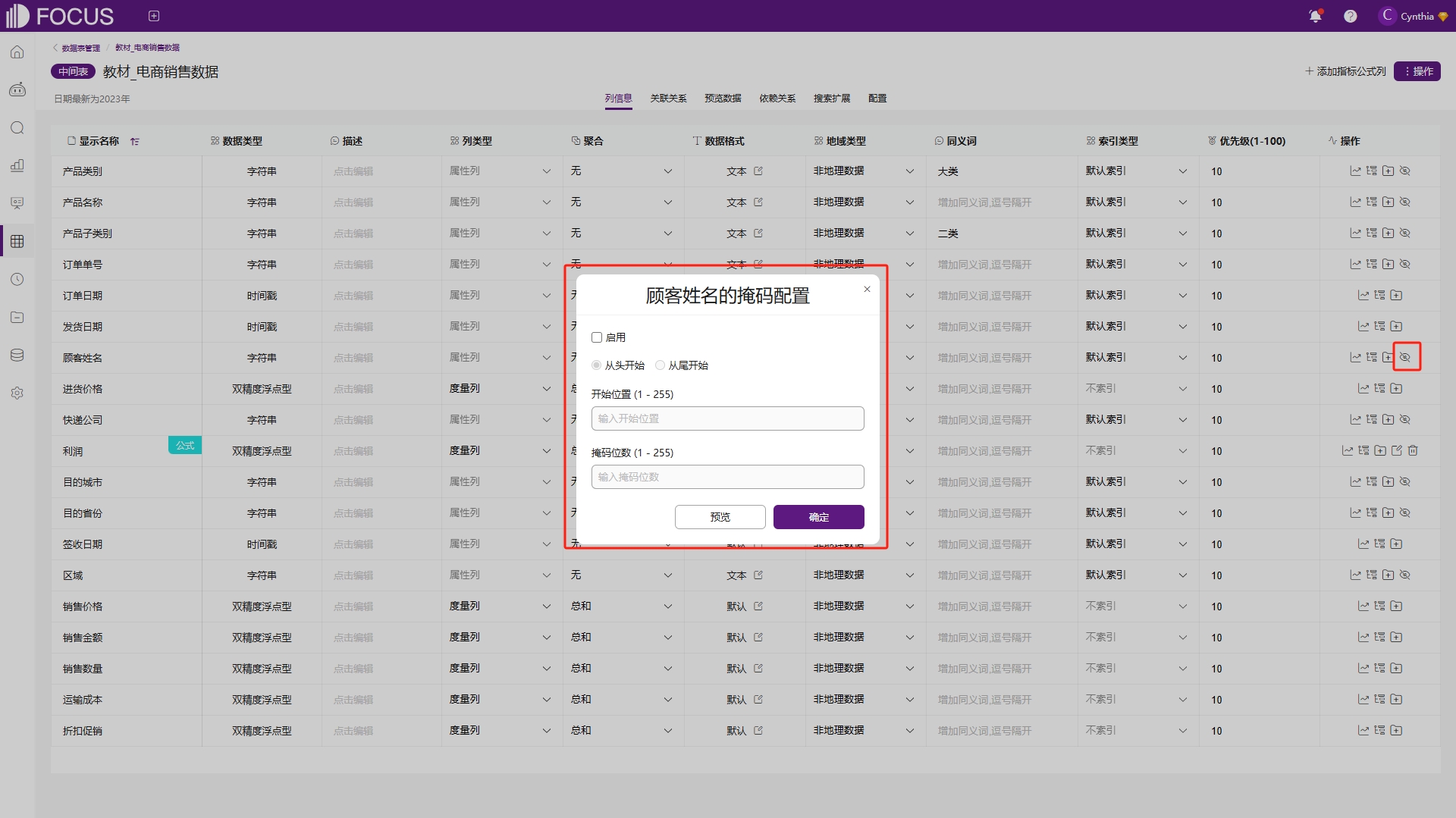
图6-34 掩码配置
针对本地导入的数据,DataFocus支持覆盖上传和累加上传两种数据更新方式。仍旧是在数据“详情”页面中进行操作,点击右上角“操作”——“覆盖上传”,如图6-35,输入数据表相关信息,这里和导入数据表的步骤相同,输入完毕后点击确认即可覆盖原来导入的数据表,需要注意的是表结构需要与原表完全相同才可以进行覆盖。
累加上传的操作与覆盖上传步骤相同,如图6-36,并且表结构也需要与原表保持一致,上传成功后在原表的基础上数据将会进行累加。
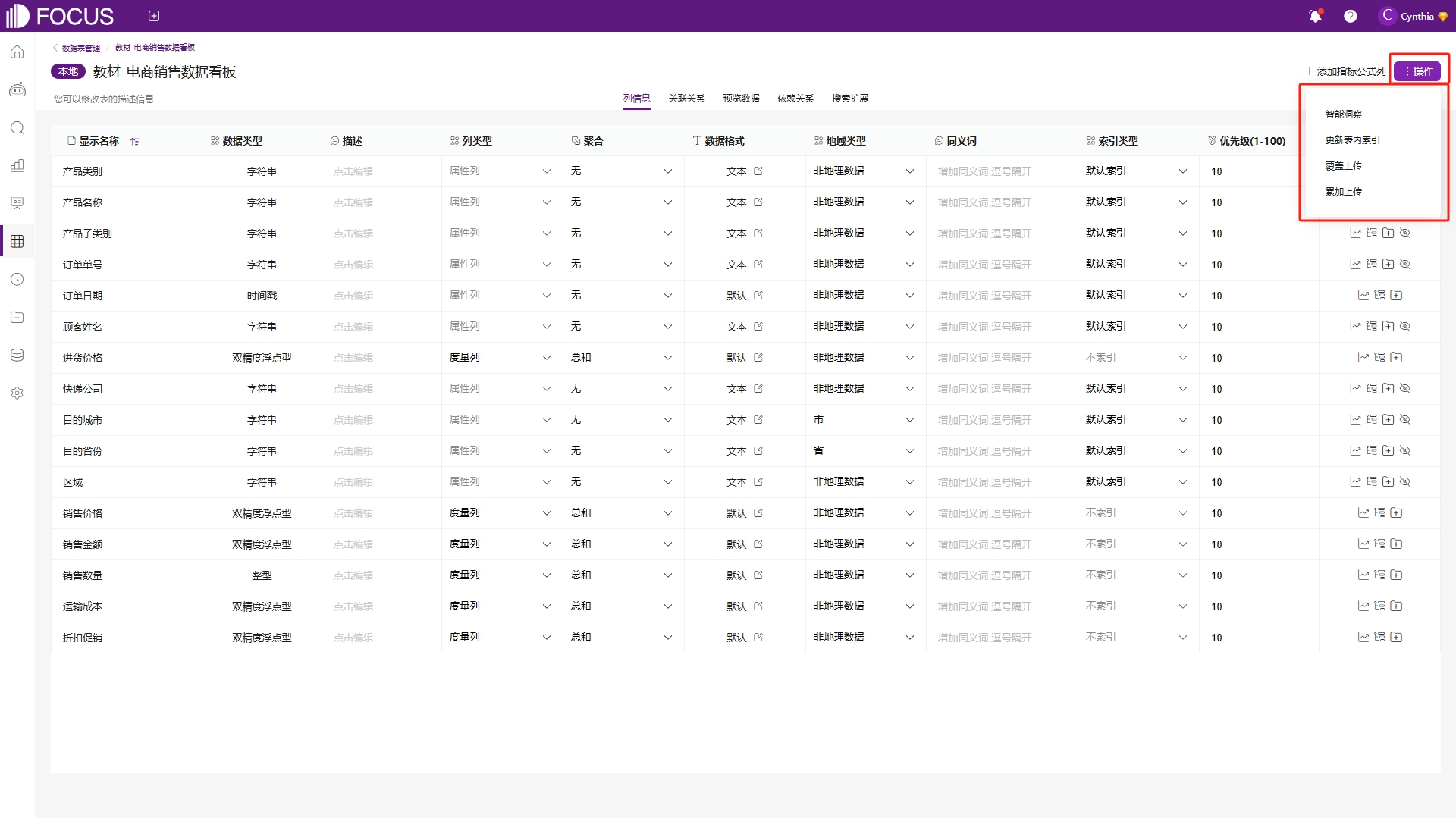
图6-35 覆盖上传
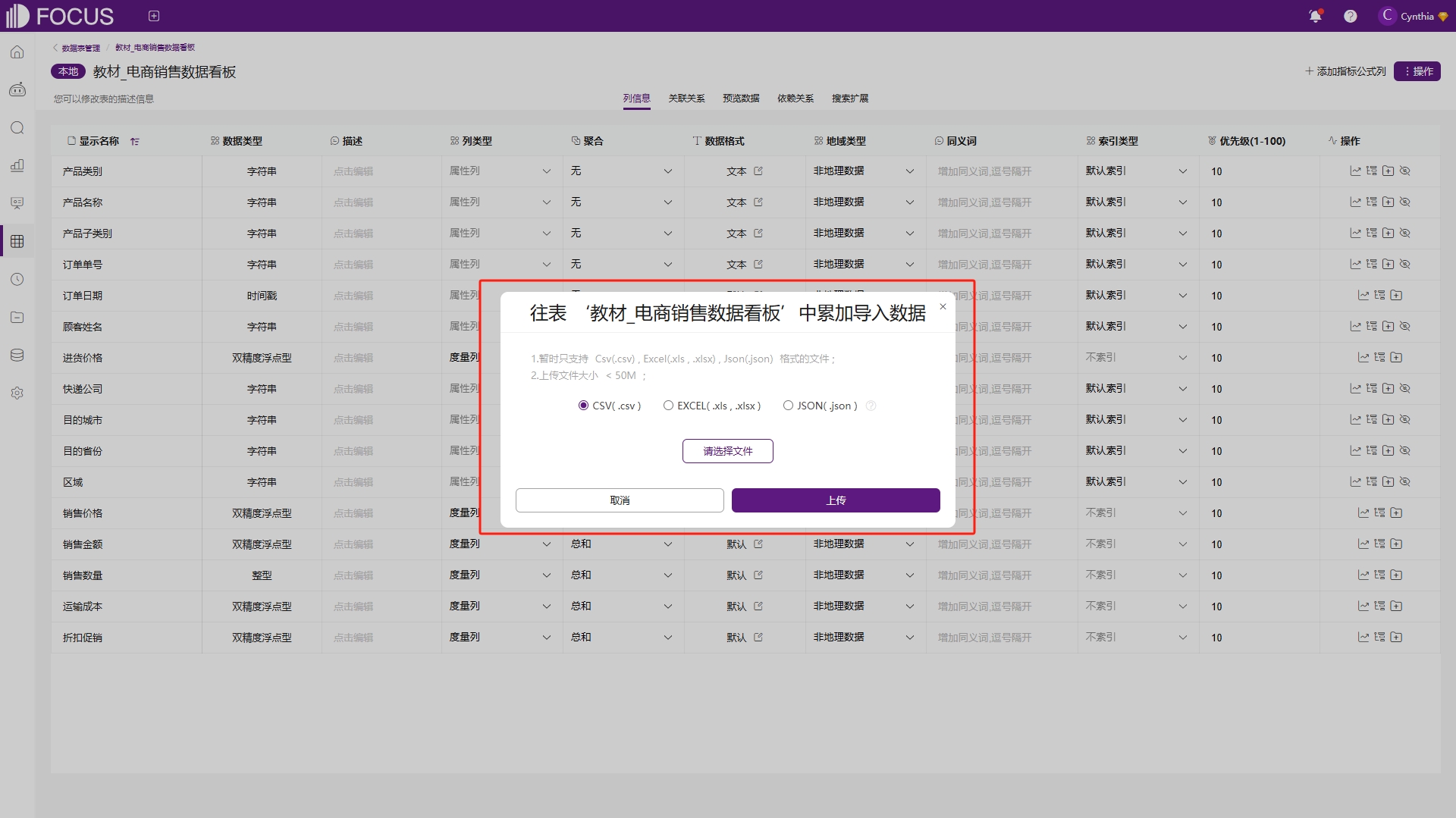
图6-36 累加上传对话框
2. 关联关系
点击关联关系可以为当前表格添加多表关联,实现数据的跨表查询,如图6-37,具体的关联操作参考1.3多表关联。还可以通过点击“查看所有关联关系”查询当前系统内所有表格之间的关联情况,如图6-38。
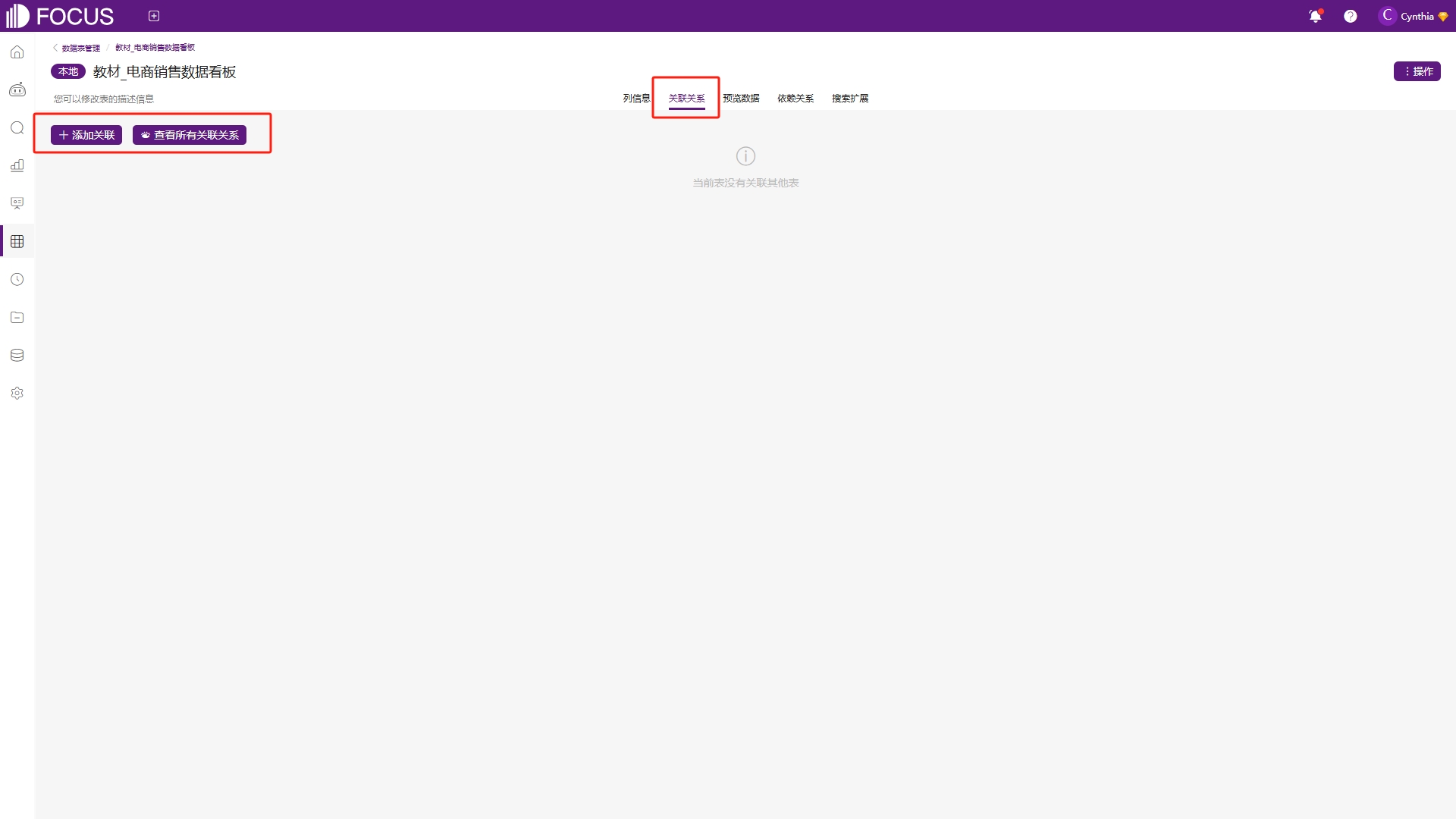
图6-37 关联关系
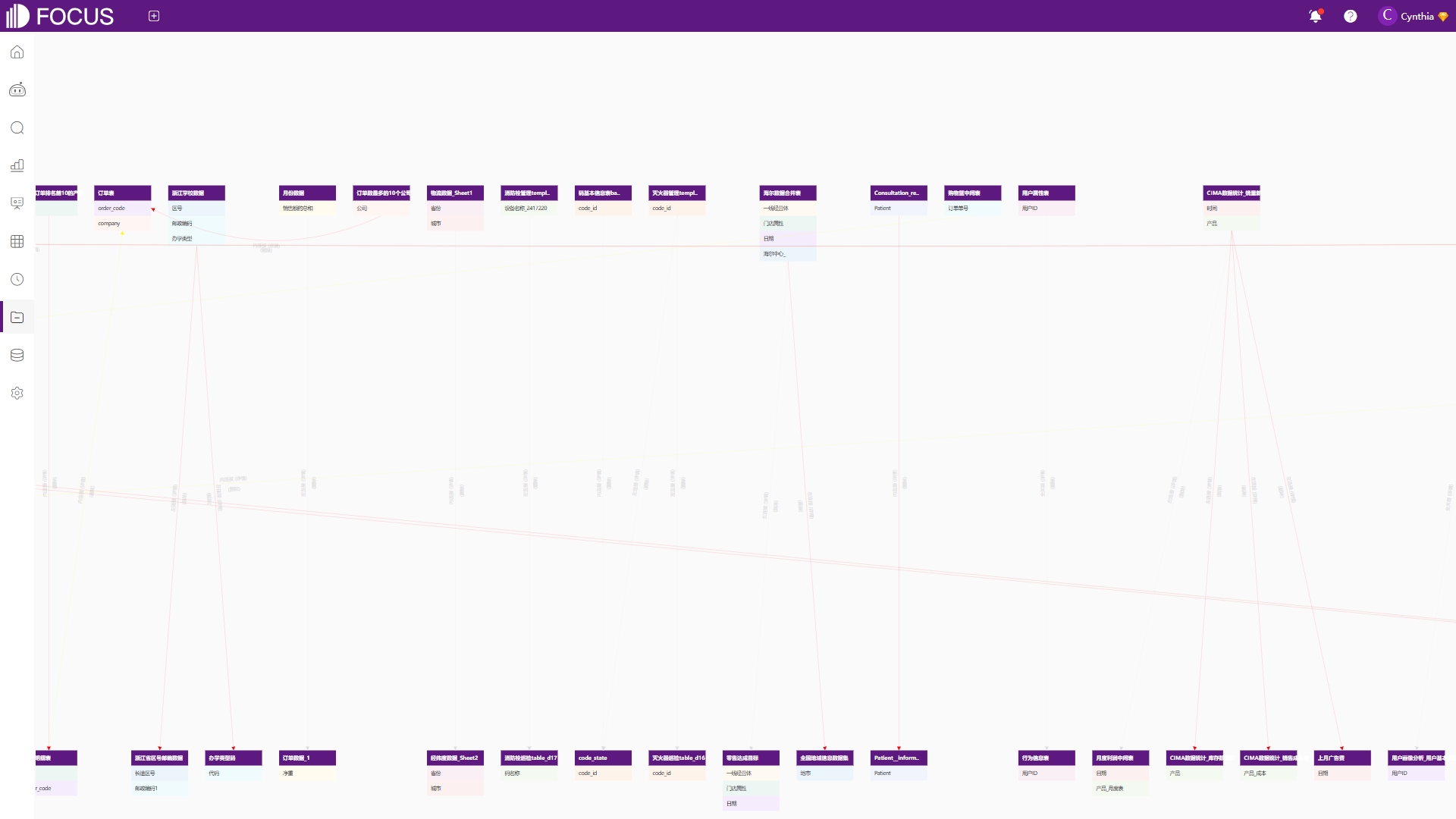
图6-38 查看所有关联关系
3. 预览数据
点击预览数据,可以随机预览当前数据表中的30条数据,还可以了解数据表的总记录条数,如图6-39。
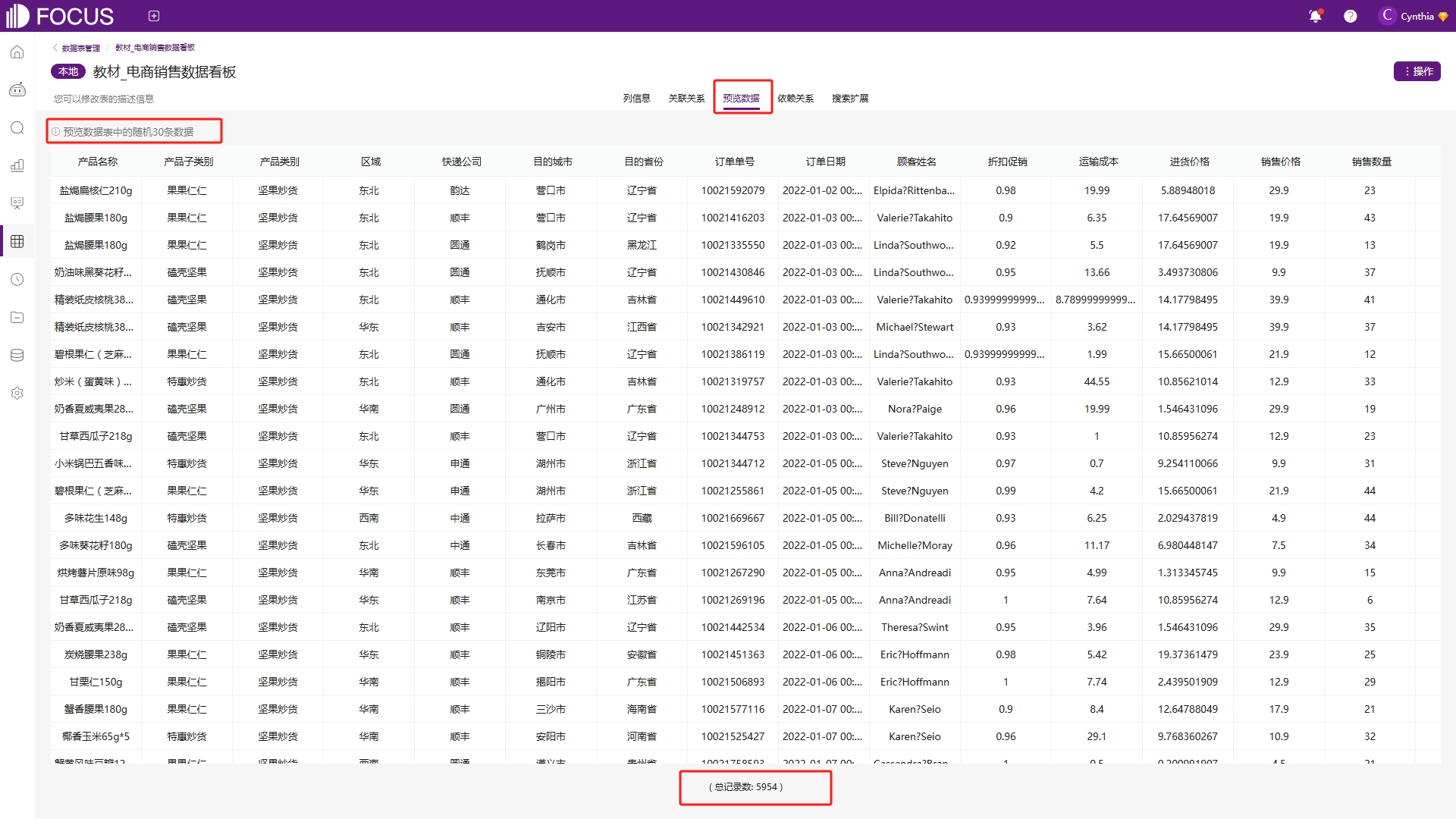
图6-39 预览数据
4. 依赖关系
点击依赖关系可以查看当前表的依赖对象,也就是依赖当前表所创建的全部数据看板和历史问答,如果当前表是中间表,则还会展示出当前中间表的数据来源,如图6-40。
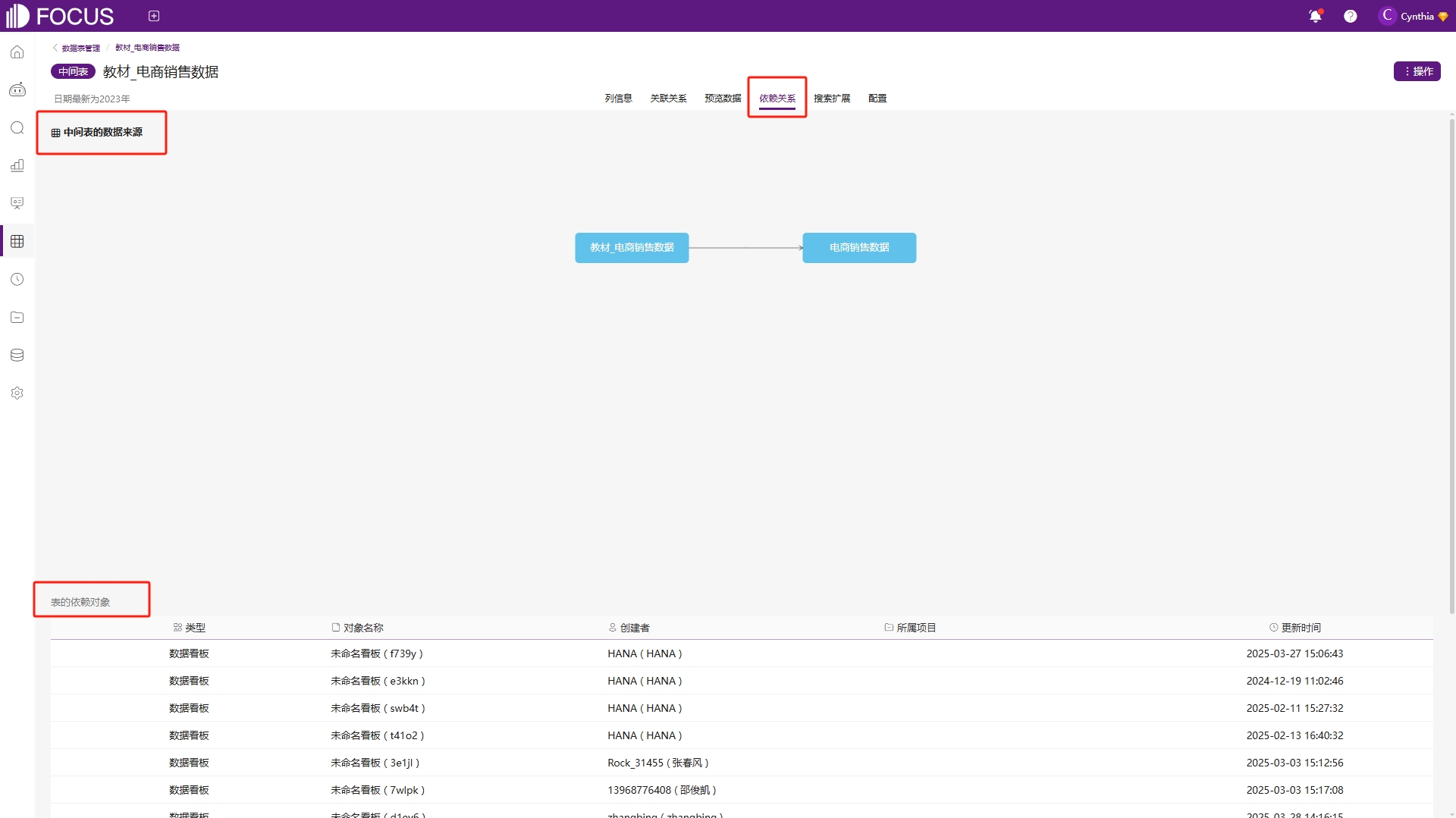
图6-40 依赖关系
5. 搜索拓展
搜索配置在第4章探索性数据分析里全部介绍过,可以直接跳转4.3.3搜索拓展进行查看。
创建中间表
中间表是DataFocus系统进行复杂数据处理的主要方法,对源数据工作表进行二次加工后可得到中间表,目前系统重有三种不同的中间表,分别是问答中间表、关联中间表和合并中间表,问答中间表是在搜索页面生成的中间表,关联中间表和合并中间表是在资源管理页面生成的中间表。
问答中间表是在搜索页面生成的中间表,比如用户在搜索过程中对数据进行了分析整理和计算,最终得到一张图表,如图6-41所示,并且想将这张表的数据保存下来做进一步的分析,此时就可以直接在搜索页面的“…”操作项中找到“保存为中间表”,将当前表的数据保存为中间表。
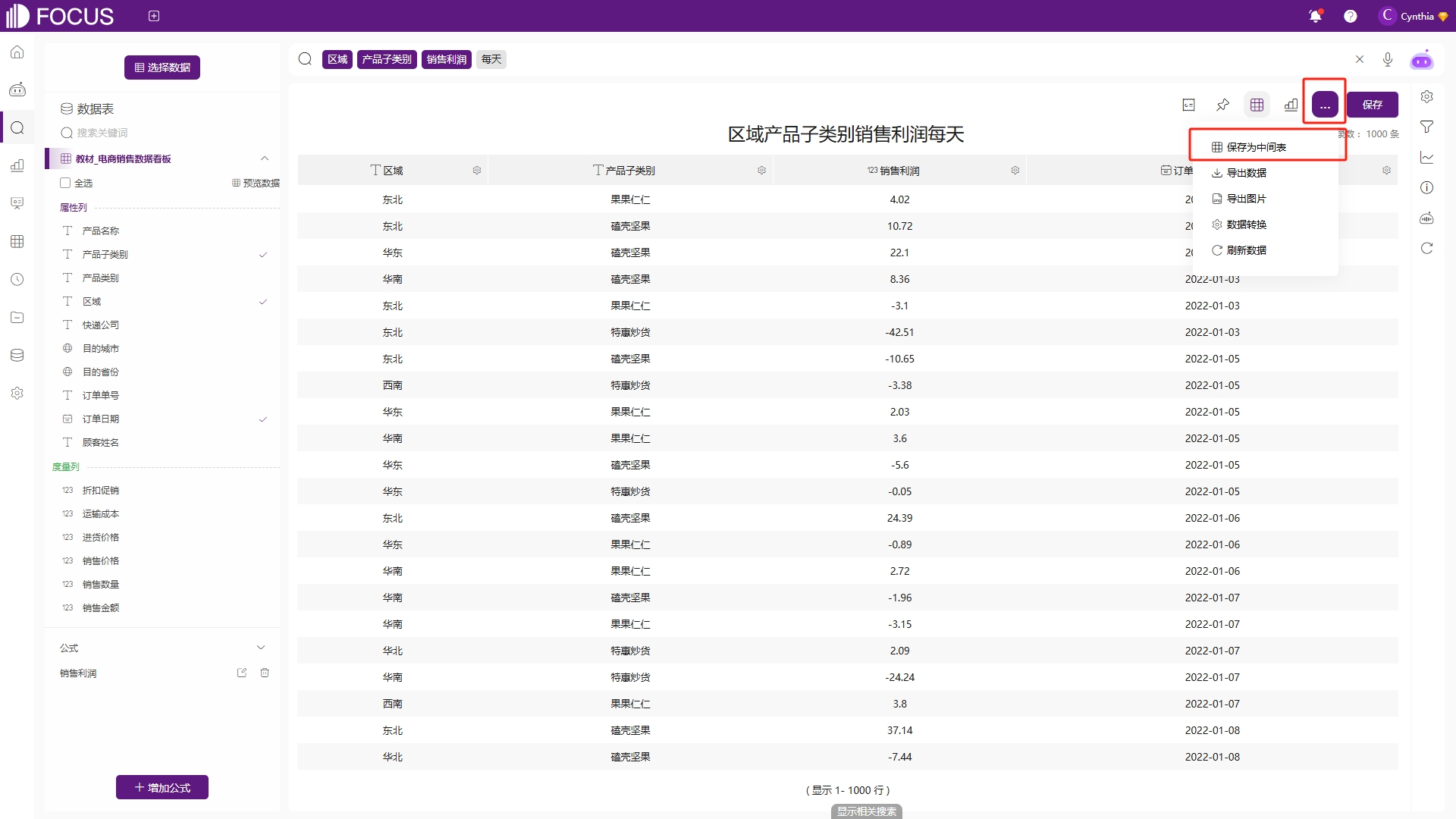
图6-41 保存问答中间表
在弹出的保存对话框中可以对该中间表进行命名,同时可以点击中间表列处的列名进行修改,如图6-42,修改完成后,点击“确定”即可将当前数据保存为问答中间表。保存完成,可以点击“跳转到项目中查看”,系统会自动跳转到资源管理模块。
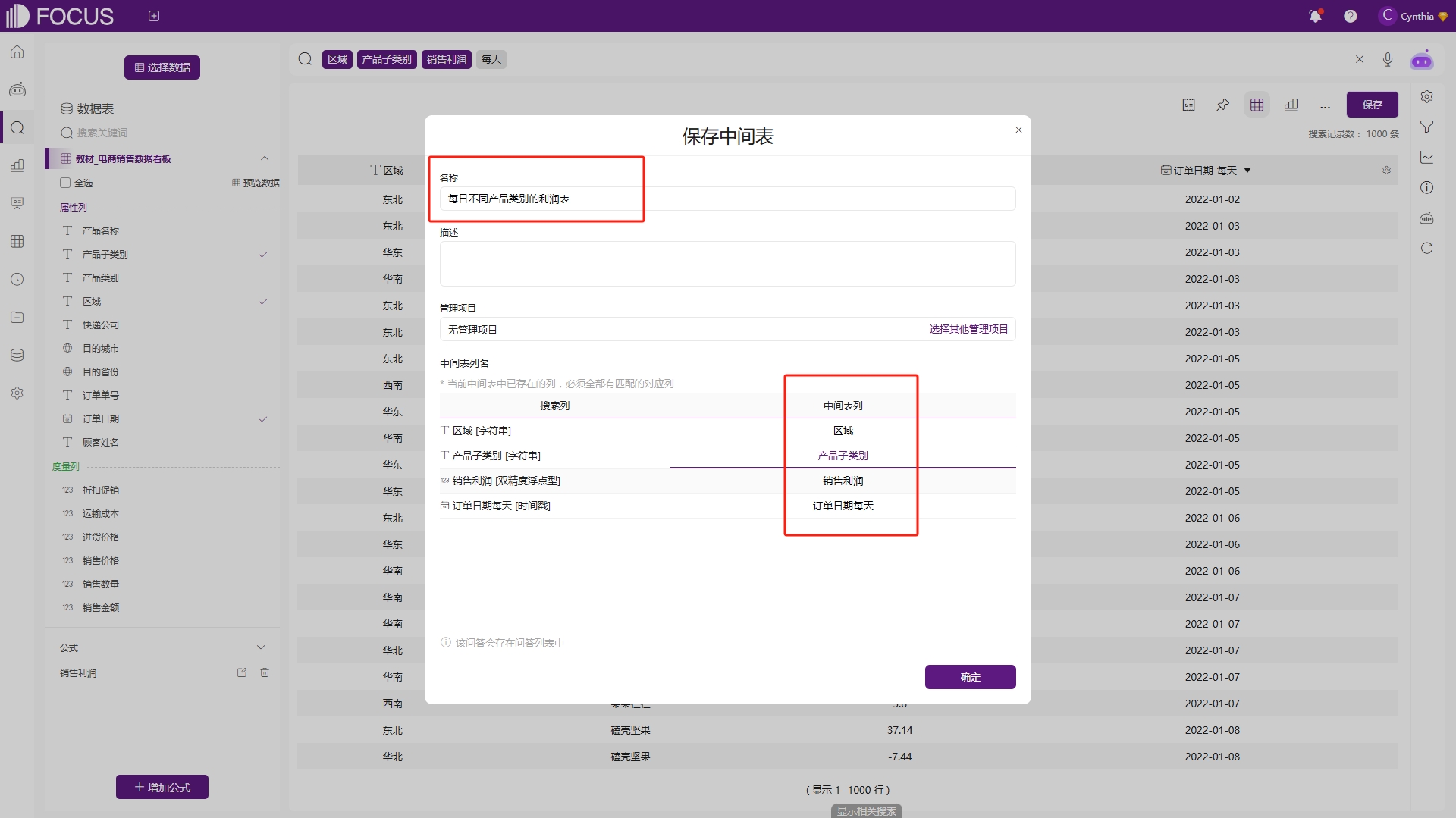
图6-42 问答中间表修改表名和列名
在资源管理模块中可以看到,中间表的创建需要一定的时间,中间表刚创建的时候,会标识为“正在创建中间表”,如图6-43,此时处于创建过程中的中间表是不可用的,需要等中间表创建完成后,才会可以作为一张类型为“问答中间表”的数据表在数据源中选择使用。
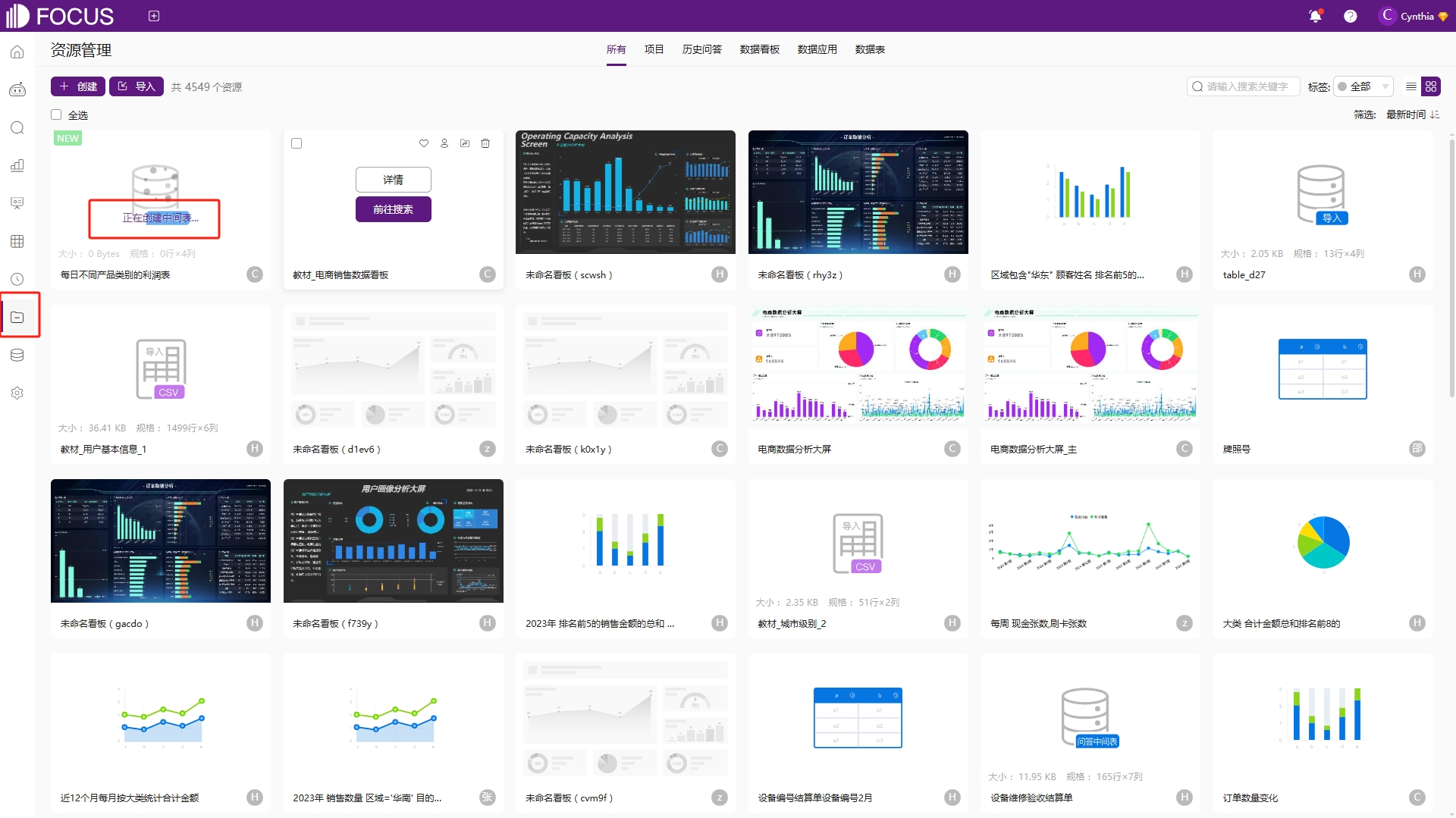
图6-43 中间表创建中
只有当前中间表的拥有者与登录者账号一致时,才可以对创建的中间表进行编辑。如果有特殊情况需要修改所有者为其他账号的中间表时,可以临时将中间表的所有者修改为当前登录账号,如图6-44,然后再进行编辑。具体操作一样是,进入数据表详情,点击操作,可以看到“编辑中间表”,如图6-45。
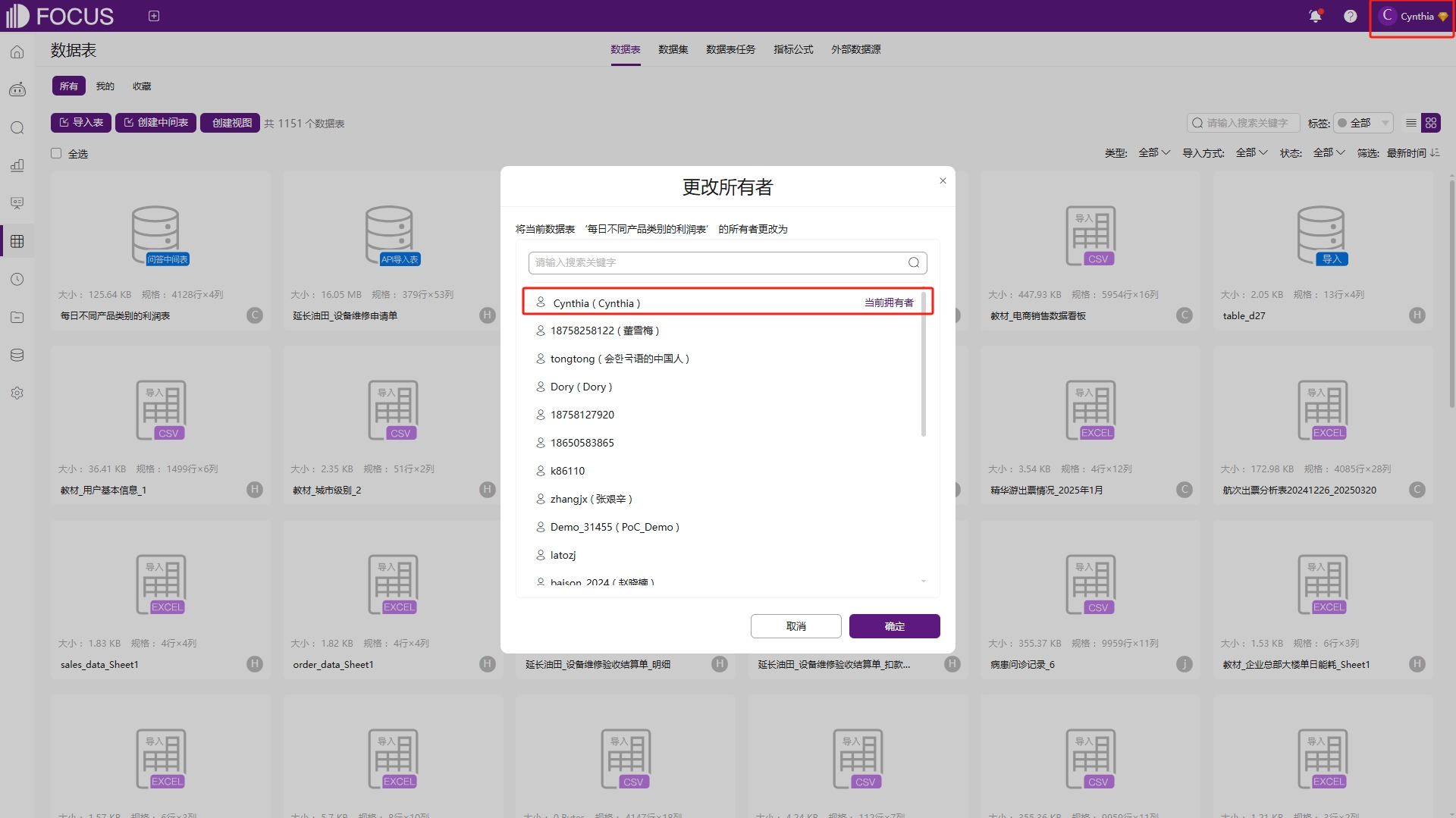
图6-44 中间表拥有者
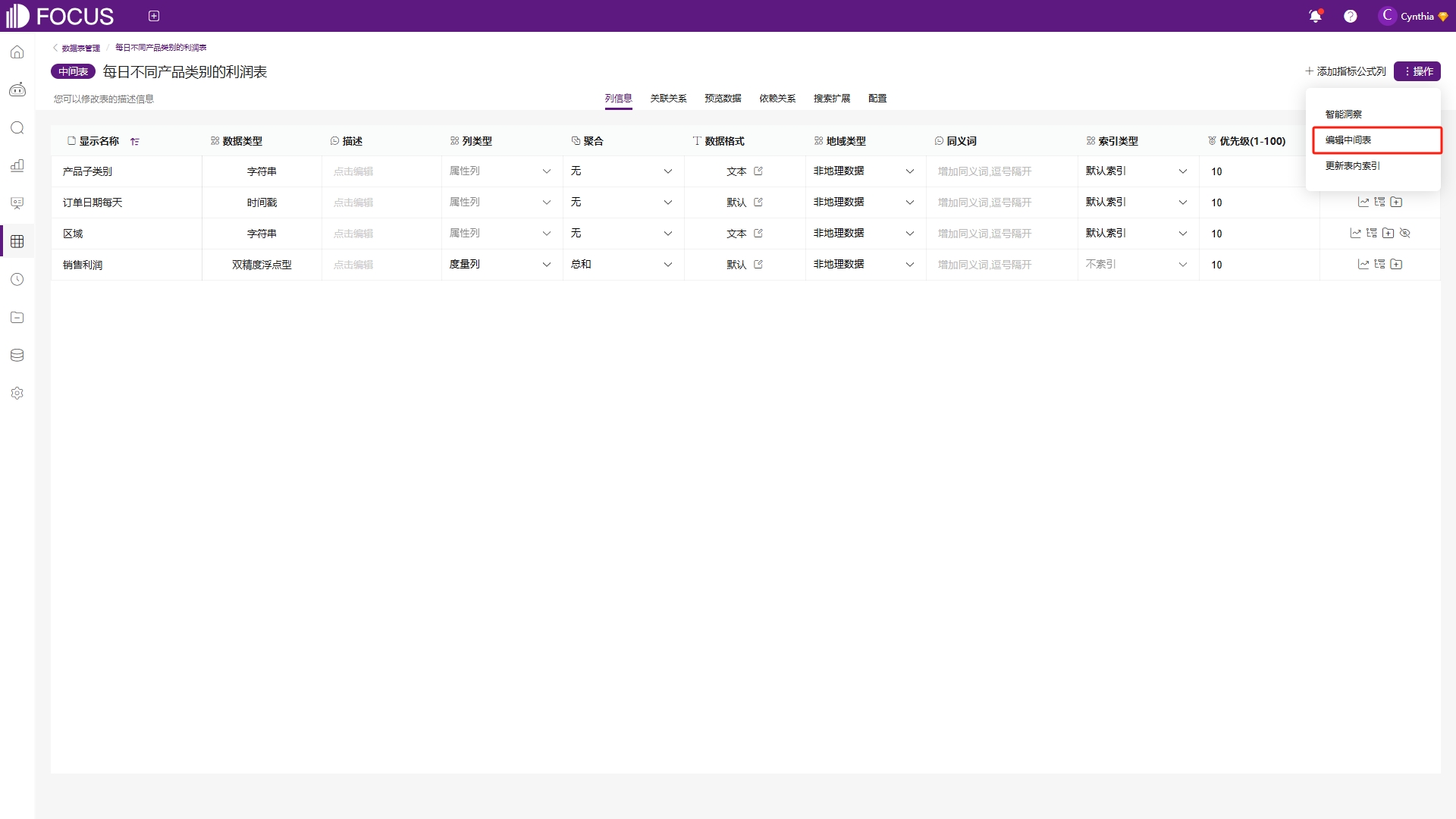
图6-45 编辑中间表
第二种方式是在“数据表管理”模块中点击“创建中间表”——“关联中间表”,如图6-46,进入类似搜索模块的中间表创建页面,在这里需要先选择数据表和数据表中的各个字段,同时通过增加公式创建新列,来构建所需要的中间表,如图6-47。
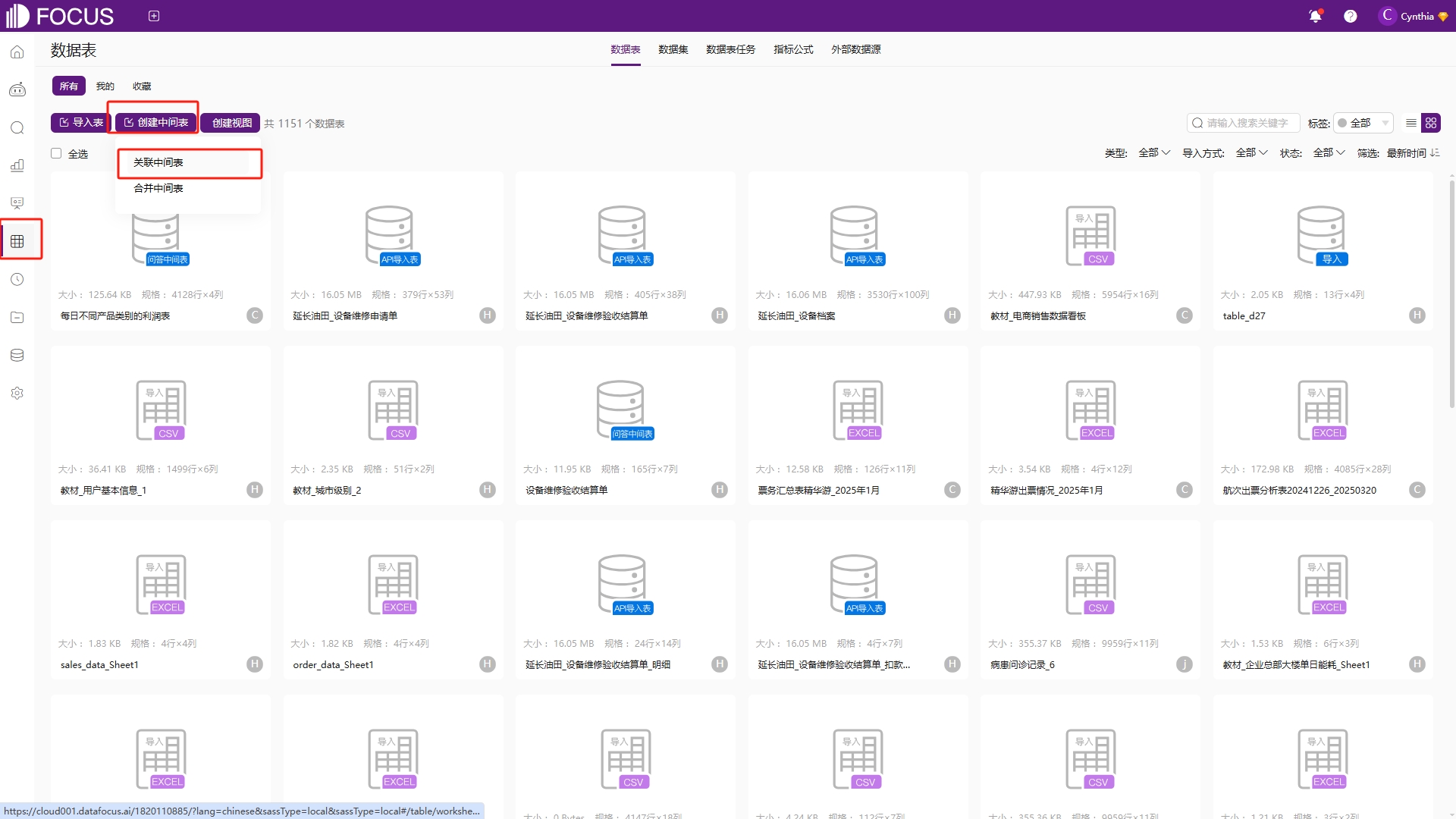
图6-46 创建关联中间表
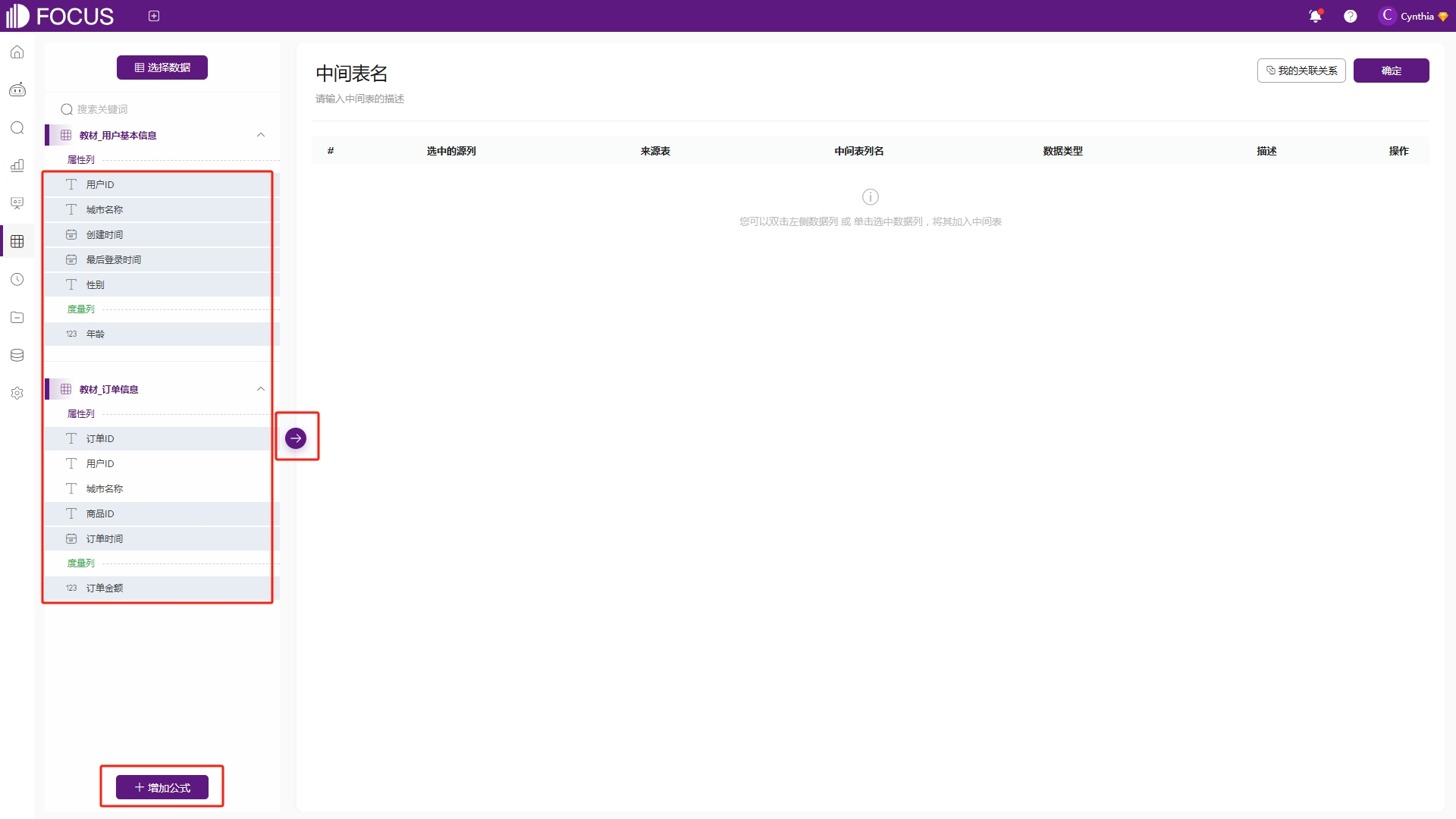
图6-47 中间表添加字段
字段添加完成后,点击“中间表名”对该中间表进行命名,点击“中间表列名”下方可以修改显示的列名,如图6-48。若是使用2张或2张以上的数据表来创建中间表,则需在“我的关联关系”中构建选中的所有表之间的关联关系。若是选择的表在数据表管理中已建立关联关系,那么点击“我的关联关系”会直接显示选中表早前建立的关联关系,如图6-49。用多表创建中间表,表与表之间必须要建立关联关系。创建完成后点击确定,就可以像问答中间表时一样在资源管理页面找到它了,不同之处在于表的类型为“关联中间表”。同样的,中间表的所有者和当前账号一致的情况下,可以进行编辑中间表。
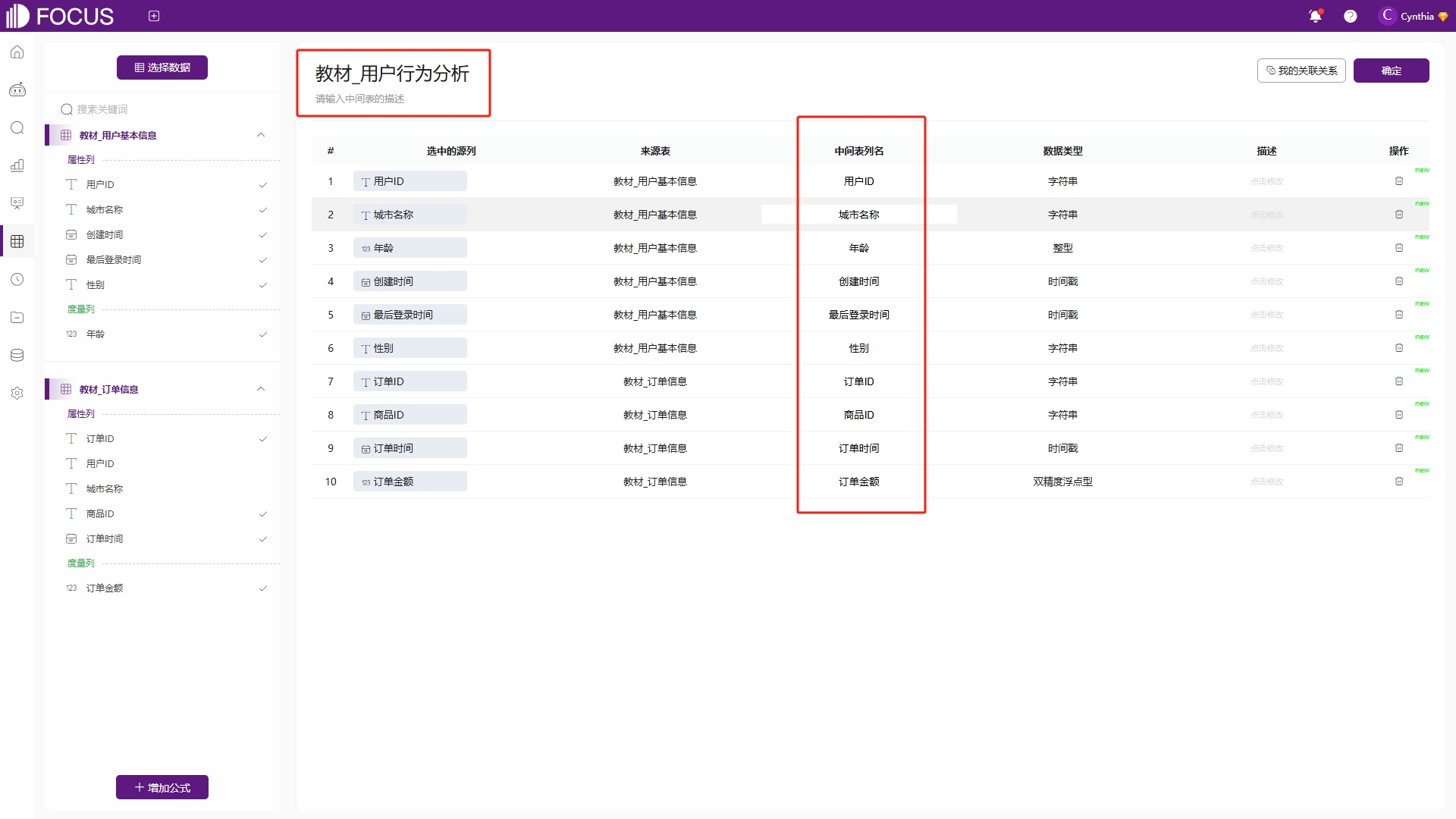
图6-48 关联中间表修改表名列名
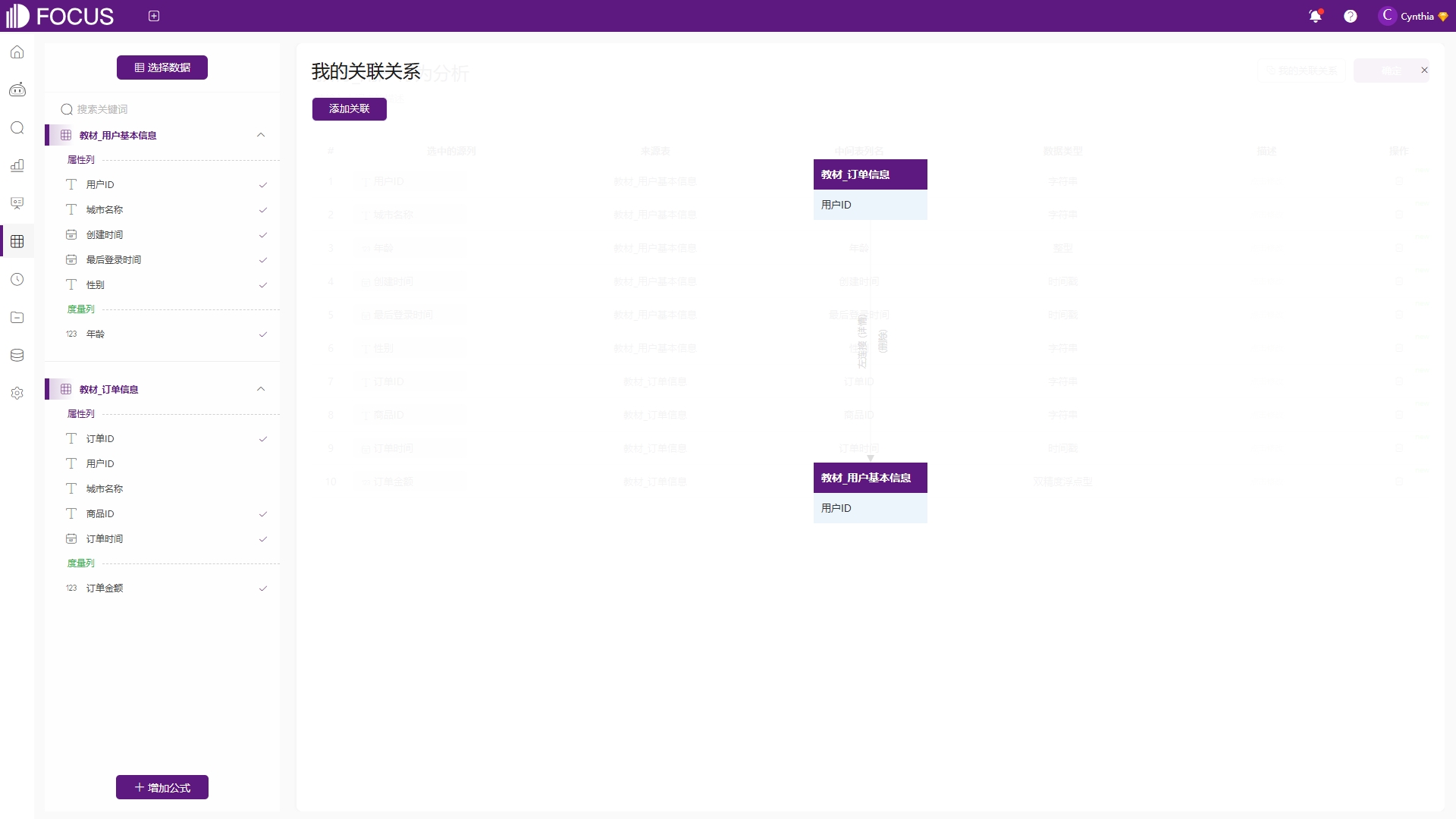
图6-49 我的关联关系
第三种方式是在“数据表管理”模块中点击“创建中间表”——“合并中间表”,进入合并中间表创建页面,一样需要先选择数据表和数据表中需要合并的字段,来构建所需要的中间表,如图6-50。
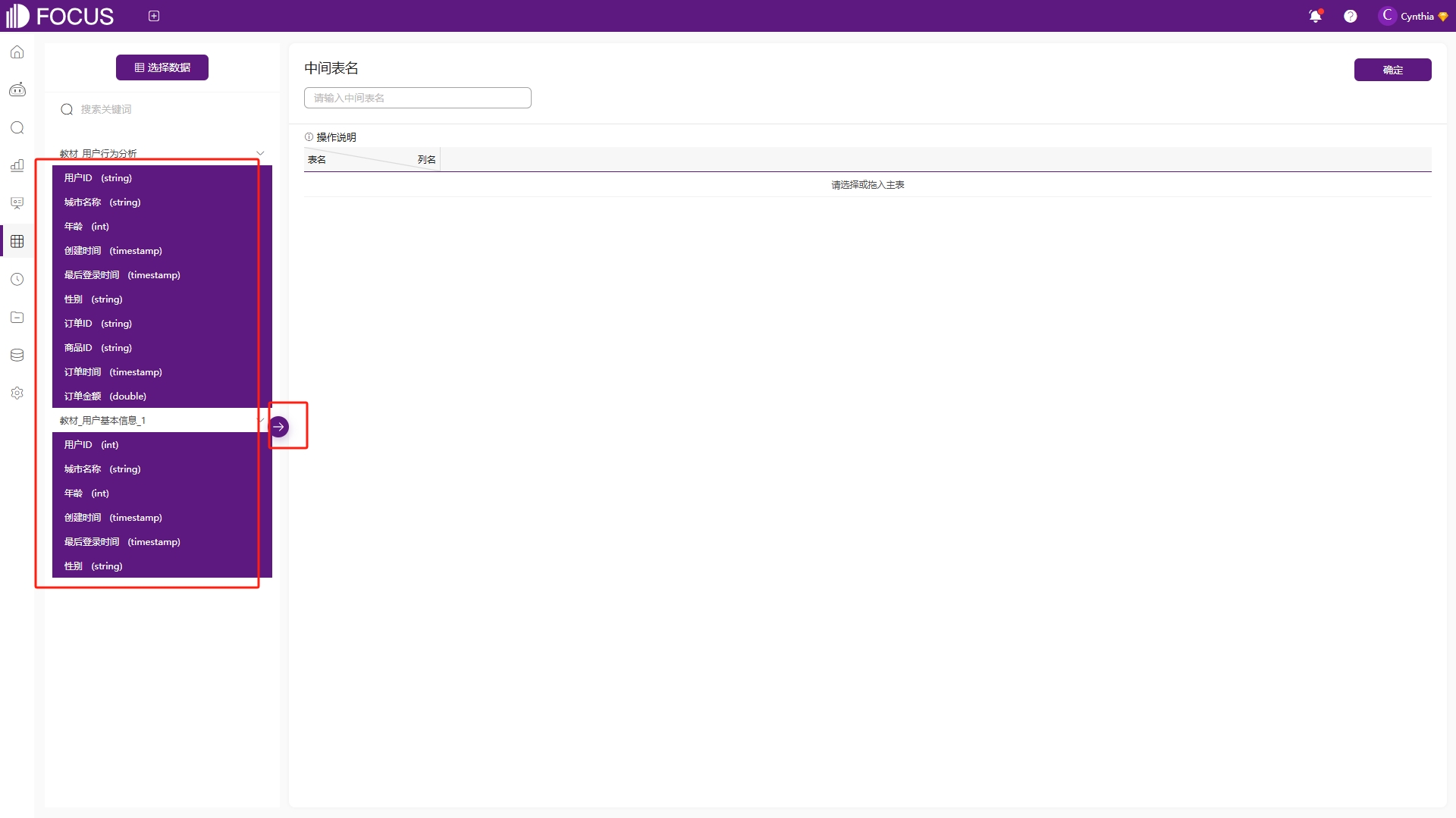
图6-50 合并中间表创建页面
合并中间表的功能与数据表的累加上传类似,实现的都是多张数据表之间的上下合并。但合并中间表与累加上传的差异是,合并中间表不需要数据表的字段名、表结构的严格一致,列名之间的匹配如果有差异,可以通过拖拽进行替换,如图6-51。但需要注意的是,需要合并的列类型必须匹配,不能将属性列和度量列进行合并;其次合并列不允许存在空值,也就是说待合并的多个数据表合并时用的字段数量必须一致,如图6-52。
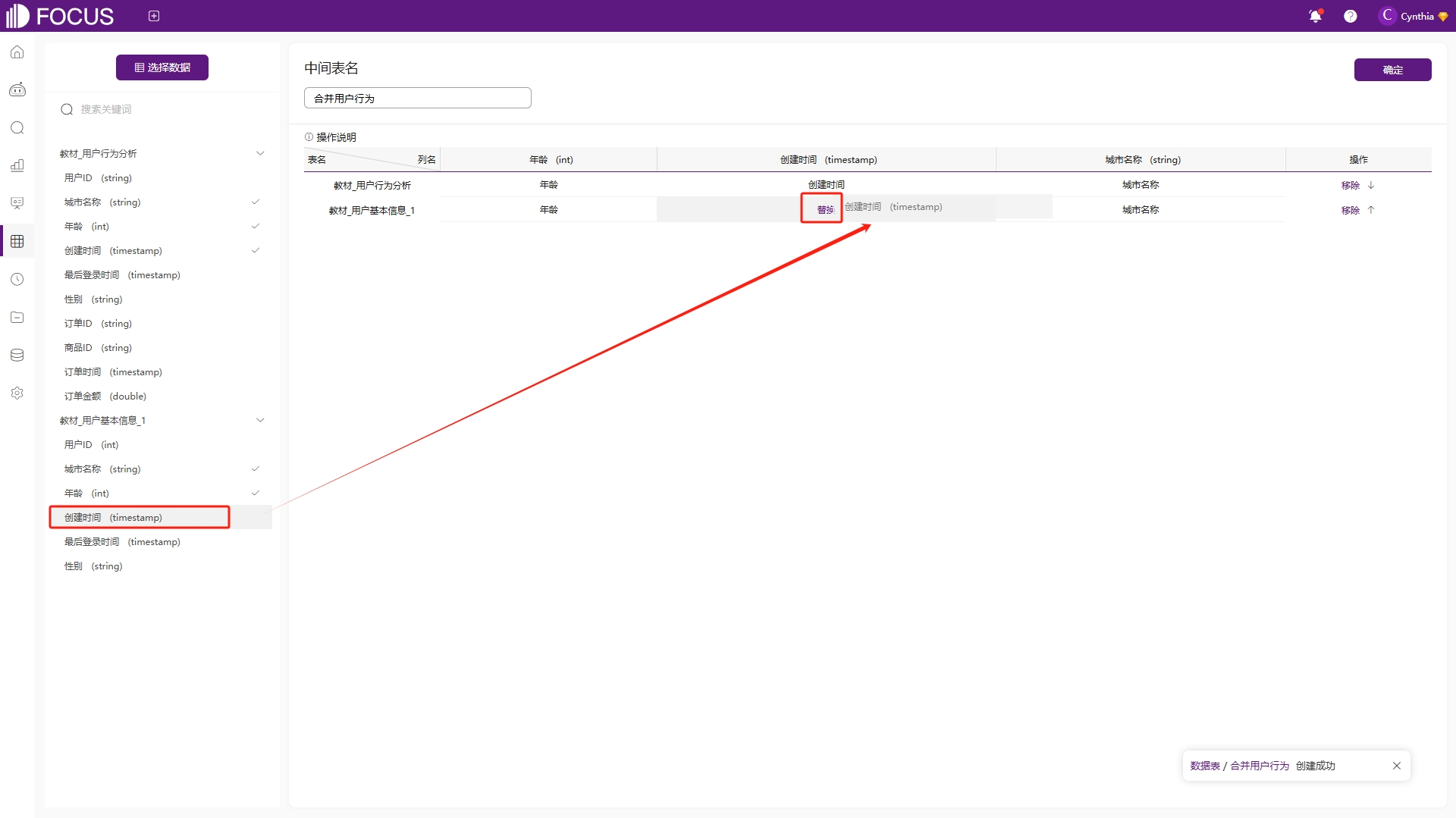
图6-51 拖拽替换字段
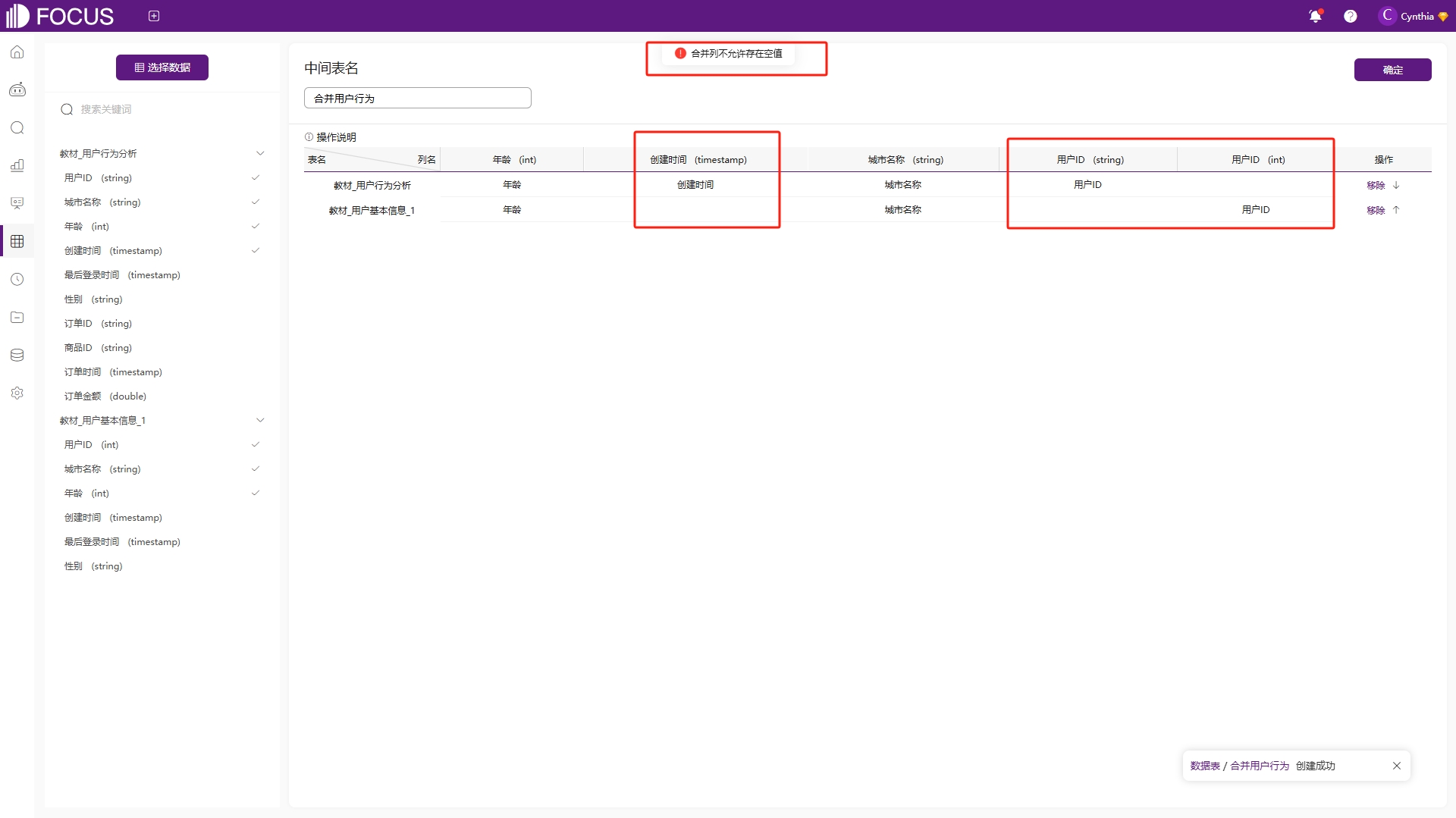
图6-52合并中间表注意点
字段添加完成后,在“请输入中间表名”处,为该中间表进行命名,点击最上方一列的列名可以修改显示列名,创建完成后点击确定,同样可以在资源管理页面找到中间表,表的类型为“合并中间表”,如图6-53。
图6-53 三种不同的中间表
注意:问答中间表和合并中间表的区别:
DataFocus系统在搜索分析时是数据默认进行聚合,比如数据源表中有两条名称相同的商品的销售记录,它们有不同的销售数量,当用户只按商品名称进行搜索分析时,出现的数据结果是一条商品记录,其销售数量为数据源表中两条记录的销售数量的总和,这里发生了一次聚合。而关联中间表创建过程中是没有聚合的,就依然还是两条记录。
创建视图
除了上面讲述的中间表,如果遇到一些复杂的情况,通过公式和搜索无法获取所需的数据,则可以通过创建视图,通过撰写SQL语句,实现中间表的创建与保存。
在“数据表管理”模块中点击“创建视图”,在弹出的视图页面,左侧是系统中存在的所有数据表,在页面正上方输入SQL语句,点击“执行”,即可在页面正下方出现对应的数据预览,如图6-54和图6-55。
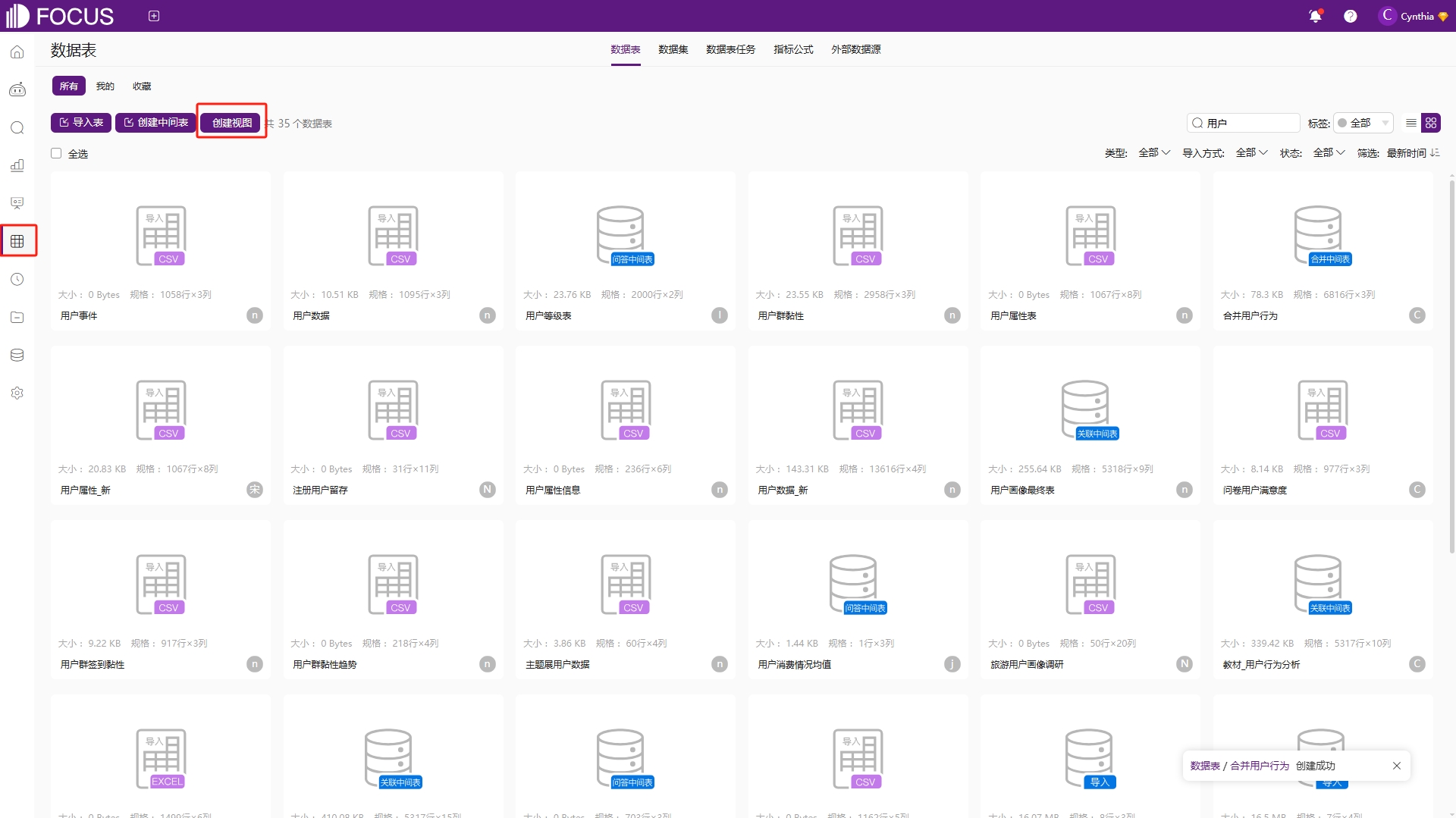
图6-54 创建视图
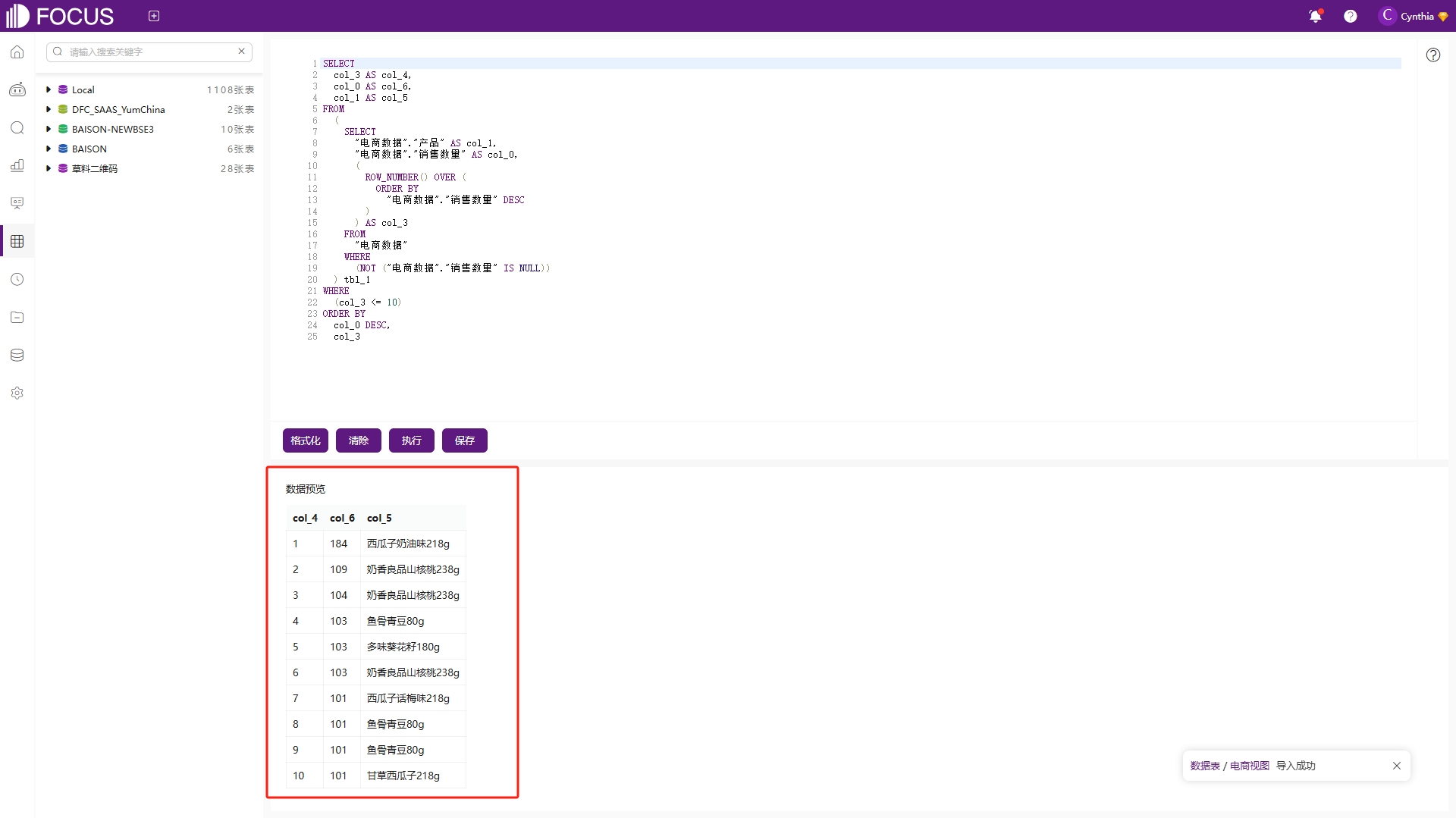
图6-55销售额排名前10的视图中间表预览
需要注意的是,视图中SQL的语法是trino sql,符合ANSI SQL标准。这里例举一段最简单的SQL语句:
SELECT
"订单单号",
"订单日期",
"销售金额"
FROM
"电商销售数据"数据预览无误后,点击保存,则会弹出视图保存对话框,如图6-56。在此处,对当前创建的视图中间表进行命名,配置导入方式,修改视图列名(非必选)后,即可完成视图中间表的创建,如图6-57。
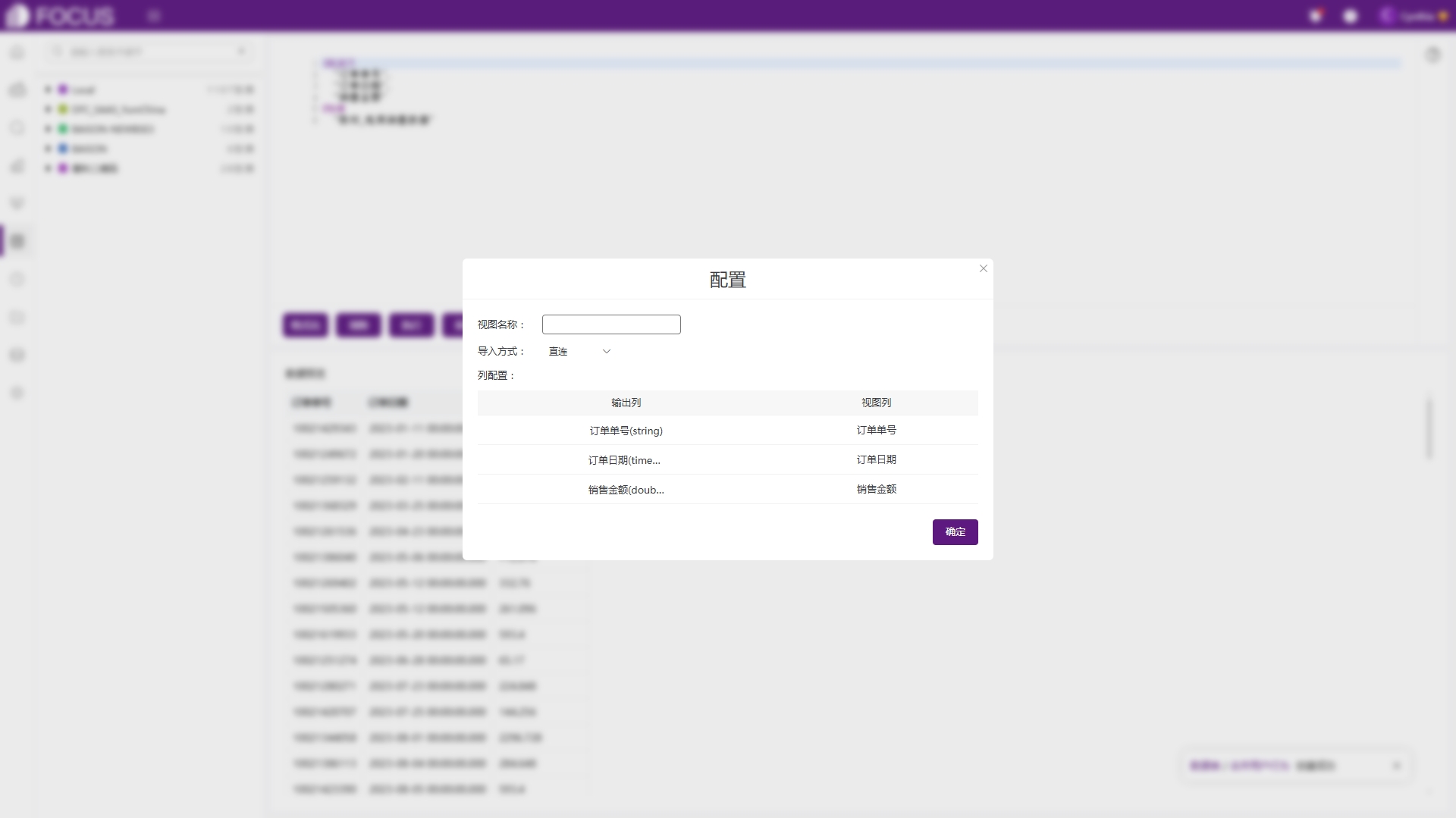
图6-56 视图保存
图6-57 视图中间表创建完成